Inspiration
I’m currently on the job market, and I’ve attended many career fairs and spoken with many recruiters. One thing I noticed is that they receive a huge number of applications and often struggle to identify trustworthy candidates efficiently. That led me to develop a product that generates a trust index from a resume based on a person’s digital footprint.
What it does
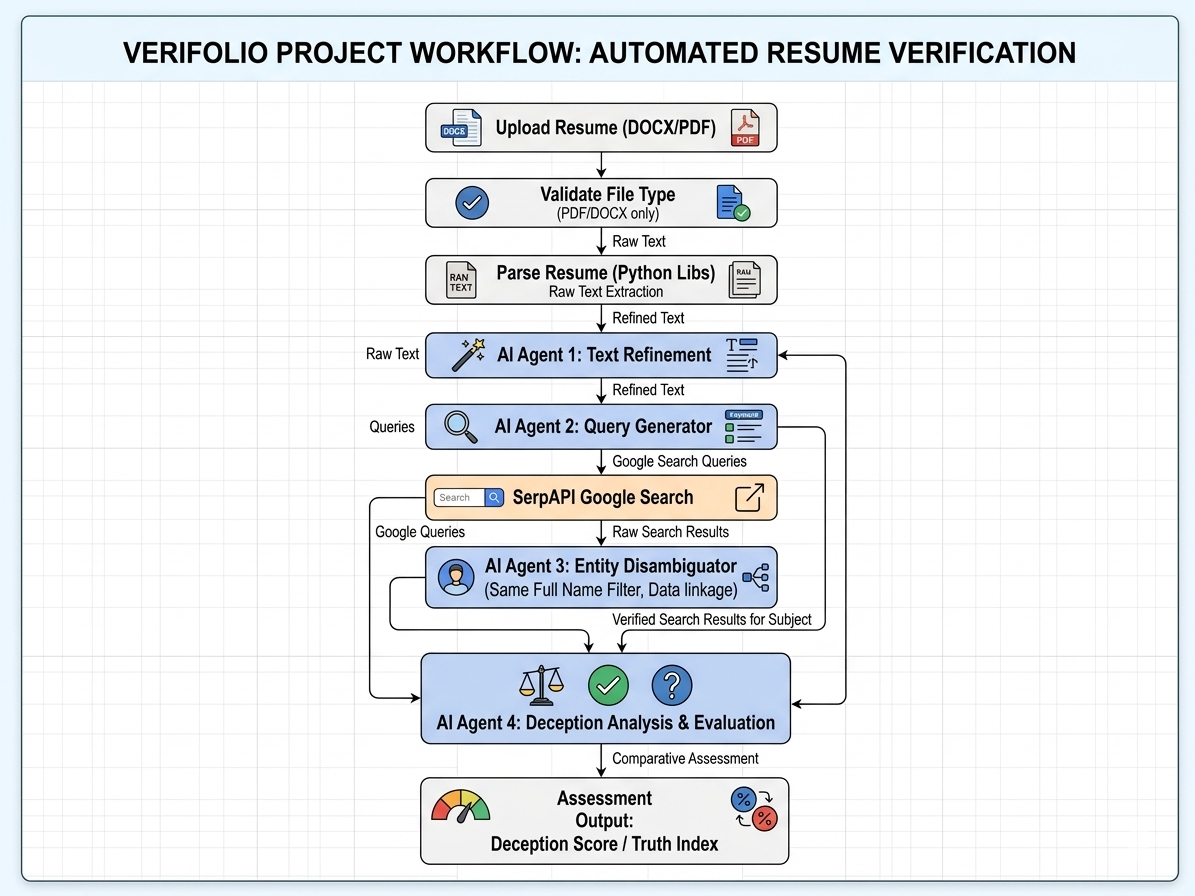
The system first takes a resume and parses it. Then, an AI agent classifies the resume’s content to make the information more structured. After that, another AI agent generates possible search queries, which are run on Google through SerpAPI to retrieve relevant URLs that are then crawled using Beautiful Soup. The results gathered from Beautiful Soup are passed to another AI agent to produce an identity score and an evidence score. Finally, the structured resume, along with these results, is fed into the last AI agent, which generates the trust index.
How we built it
I used Cursor and Codex to build it.
Challenges we ran into
The outputs from the AI agents were not very consistent, so I had to spend time on prompt engineering.
Another challenge was that the final agent was not able to generate a reliable trust index at first because I was only using a relevance score between the resume and the digital footprint. To solve this, I introduced additional metrics, such as an identity score and an evidence score, to help the AI agent avoid confusing results from people with the same name. This made it possible to focus only on results with a high identity match score.
Accomplishments that we're proud of
I’m proud that I was able to design additional metrics and improve the prompts to make the decision-making process more consistent. I also tested the pipeline with both real and fake resumes, and it produced good results.
What we learned
I learned that LLM outputs are not always consistent, which is expected since next-word prediction involves randomness. However, this inconsistency becomes more noticeable when multiple AI agents are chained together.
What's next for Verifolio
I’d like to make the results more consistent across different resumes. First, I plan to collect a large number of resumes to build a dataset of real and fake resumes. Then, I’ll optimize the prompts to improve whichever metric we decide to prioritize. If the dataset becomes large enough, I may also try fine-tuning the agents.
Built With
- bs4
- fastapi
- gemine
- python
- serpapi

Log in or sign up for Devpost to join the conversation.