-
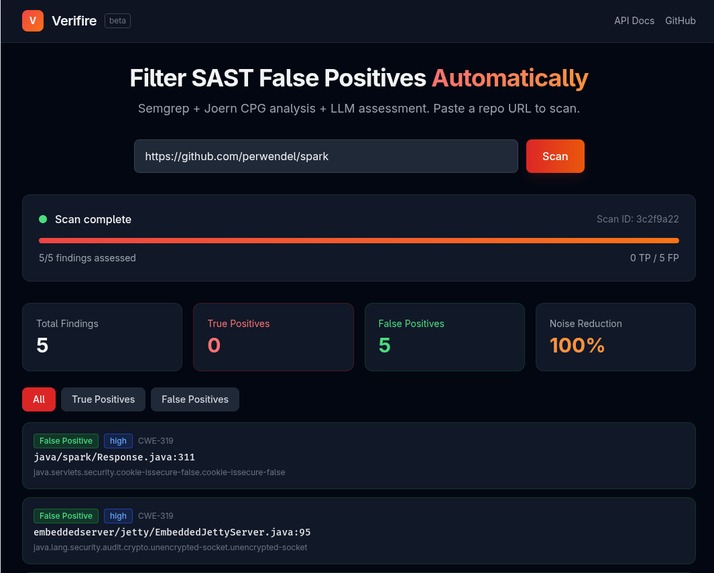
A screenshot of verifier's web frontend
Inspiration
Every developer who's run a static analysis tool knows the experience: hundreds of findings, most of them false positives. You learn to ignore the output entirely, which means real vulnerabilities get buried in noise. Recent academic papers have shown that combining program analysis with LLMs can filter false positives with F1 scores above 0.95 — but to our knowledge, no open-source tool has combined deep program analysis (Code Property Graphs, taint tracing) with LLM reasoning and published benchmark results. We wanted to build that tool and validate it.
What it does
Verifire takes the output of Semgrep (a popular open-source SAST tool) and determines which findings are real vulnerabilities and which are false alarms. It does this by combining Joern Code Property Graph analysis with LLM reasoning — the program analysis extracts precise facts about data flow, and the LLM makes the judgment call. The result: developers see only the findings that actually matter.
How we built it
We started with the evaluation harness — measuring before optimizing. We ran Semgrep on the OWASP Benchmark (2,740 labeled test cases) and got F1=0.776. Then we iteratively added layers:
- A regex-based taint tracer that identifies sources, sinks, and sanitizers in code
- Joern integration for Code Property Graph analysis — extracting precise method bodies and data flow context
- Carefully engineered LLM prompts that constrain the model to reason from evidence, not pattern-match on project names
Each layer improved accuracy, ultimately reaching F1=0.951 on the NIST Juliet test suite. We validated on three datasets (OWASP Benchmark, ZeroFalse OpenVuln, and Juliet) to avoid overfitting to any one.
The tool is deployed as a FastAPI service with a web dashboard, packaged in Docker, and hosted on fly.io.
Challenges we ran into
The biggest surprise was that throwing an LLM at the problem barely helps on its own. Our first attempt — sending raw code to an LLM and asking "is this a real vulnerability?" — scored F1=0.590 on real-world code. The LLM couldn't trace data flow, couldn't identify framework-level sanitization, and kept assuming every finding in a project with a known CVE was that CVE.
The breakthrough was realizing the LLM needs structured program analysis facts, not raw code. Once we fed it Joern's CPG-derived method bodies and our taint tracer's source/sink/sanitizer summaries, accuracy jumped from 0.714 to 0.951 — same model, same prompt style, just better input.
Accomplishments that we're proud of
- F1=0.951 on Juliet, competitive with the best academic results (LLM4FPM's 0.989) — but ours is actually a tool you can install and use
- F1=0.898 on real-world code (ZeroFalse OpenVuln dataset), approaching ZeroFalse's 0.955 — and we're open source, they're not
- The architecture genuinely works: Semgrep → Joern CPG → taint tracer → LLM, each component measurably contributing
What we learned
Program analysis and LLMs are better together than either alone. Pure LLM approaches max out around F1=0.7 on real code. Pure structural checks only work on patterns you've seen before. The combination — PL extracts structure, LLM provides judgment — reaches 0.95.
Also: prompt engineering matters more than model selection. The same model (Claude Sonnet) went from F1=0.620 to F1=0.898 on the same dataset just by changing the prompt to say "use only the code provided" and "do not use knowledge of specific CVEs."
What's next for Verifire
- Joern project-level CPG — currently we build a CPG per file. A project-wide CPG would enable cross-file data flow tracking, which LLM4FPM showed is worth +8 accuracy points.
- Local model support — LLM4FPM proved that a fine-tuned Qwen2.5-32B matches frontier model performance. Running locally would eliminate API costs and code privacy concerns.
- Cross-language validation — the architecture is language-agnostic (Semgrep and Joern both support Java, JS, Python, C/C++, Go, and more) but our evaluation was on Java datasets. Validating on Python and JavaScript benchmarks is the next priority.
- GitHub App integration — post results as PR review comments instead of requiring a separate dashboard.

Log in or sign up for Devpost to join the conversation.