-
-
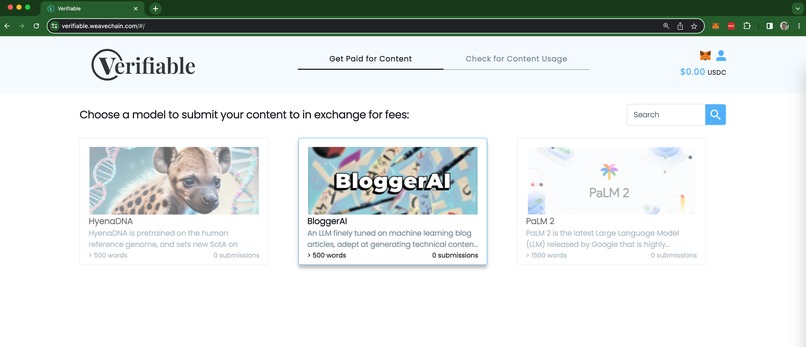
Dashboard of models
-
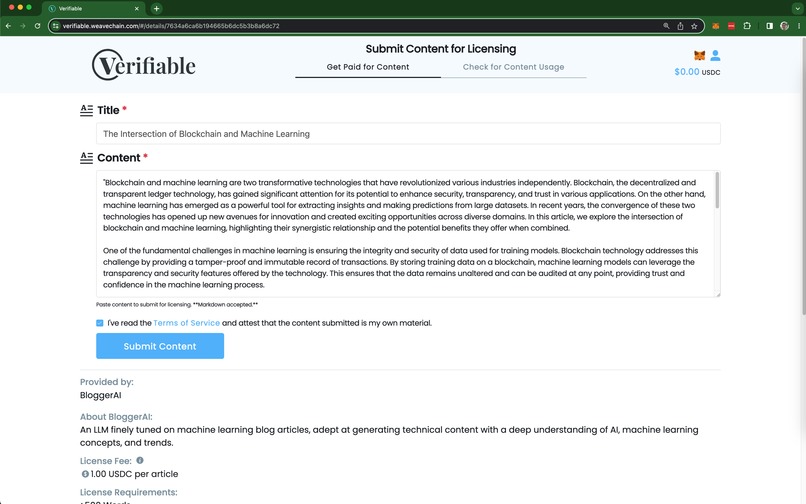
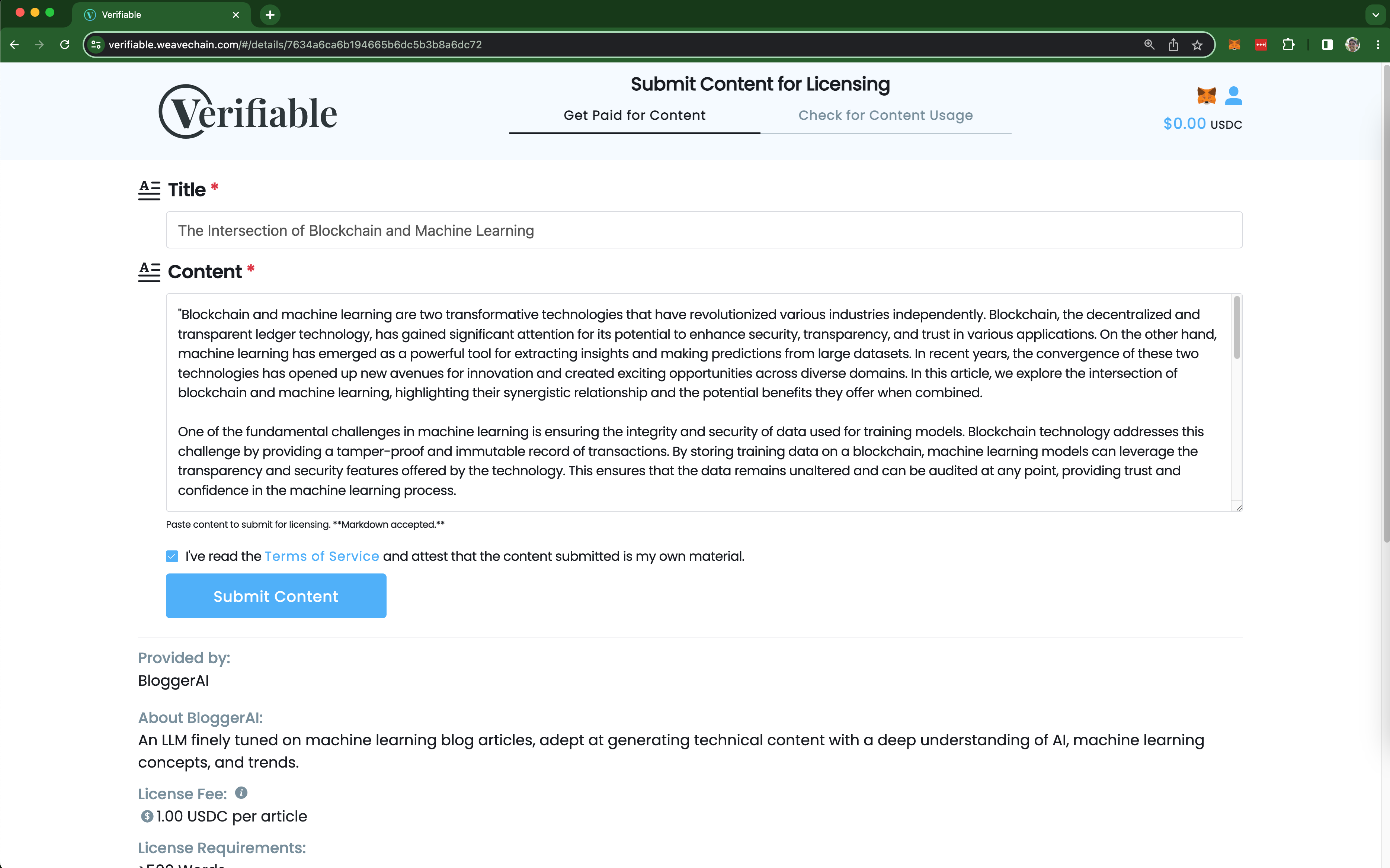
Licensing content
-
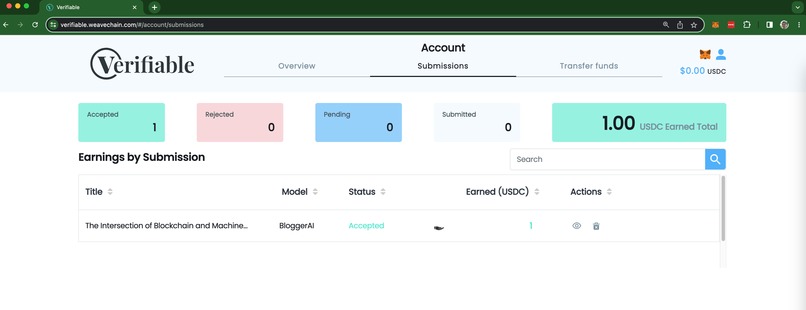
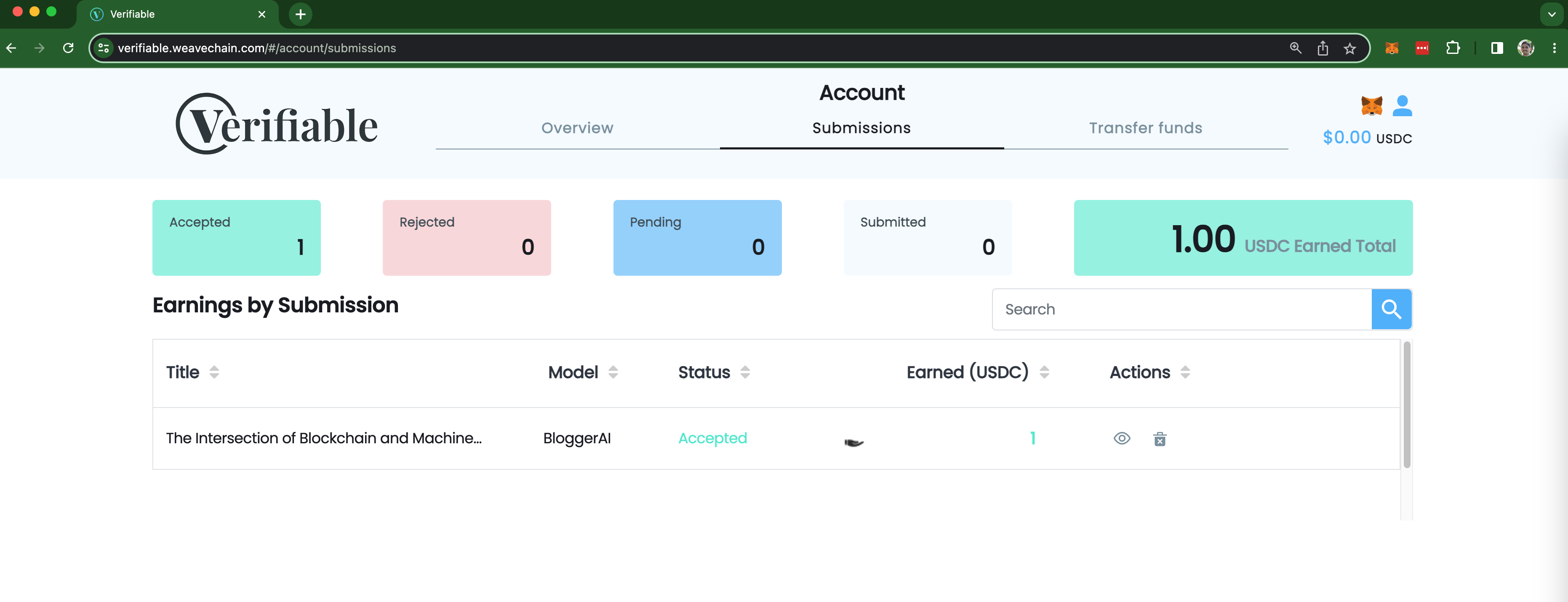
Earning from content
-
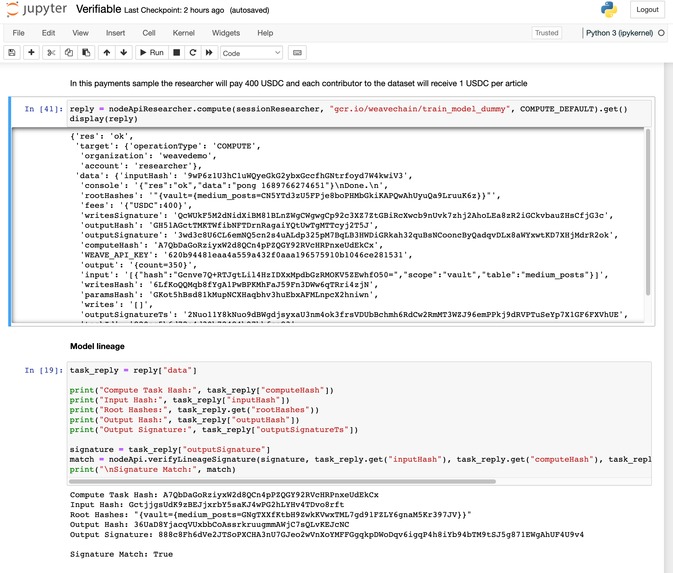
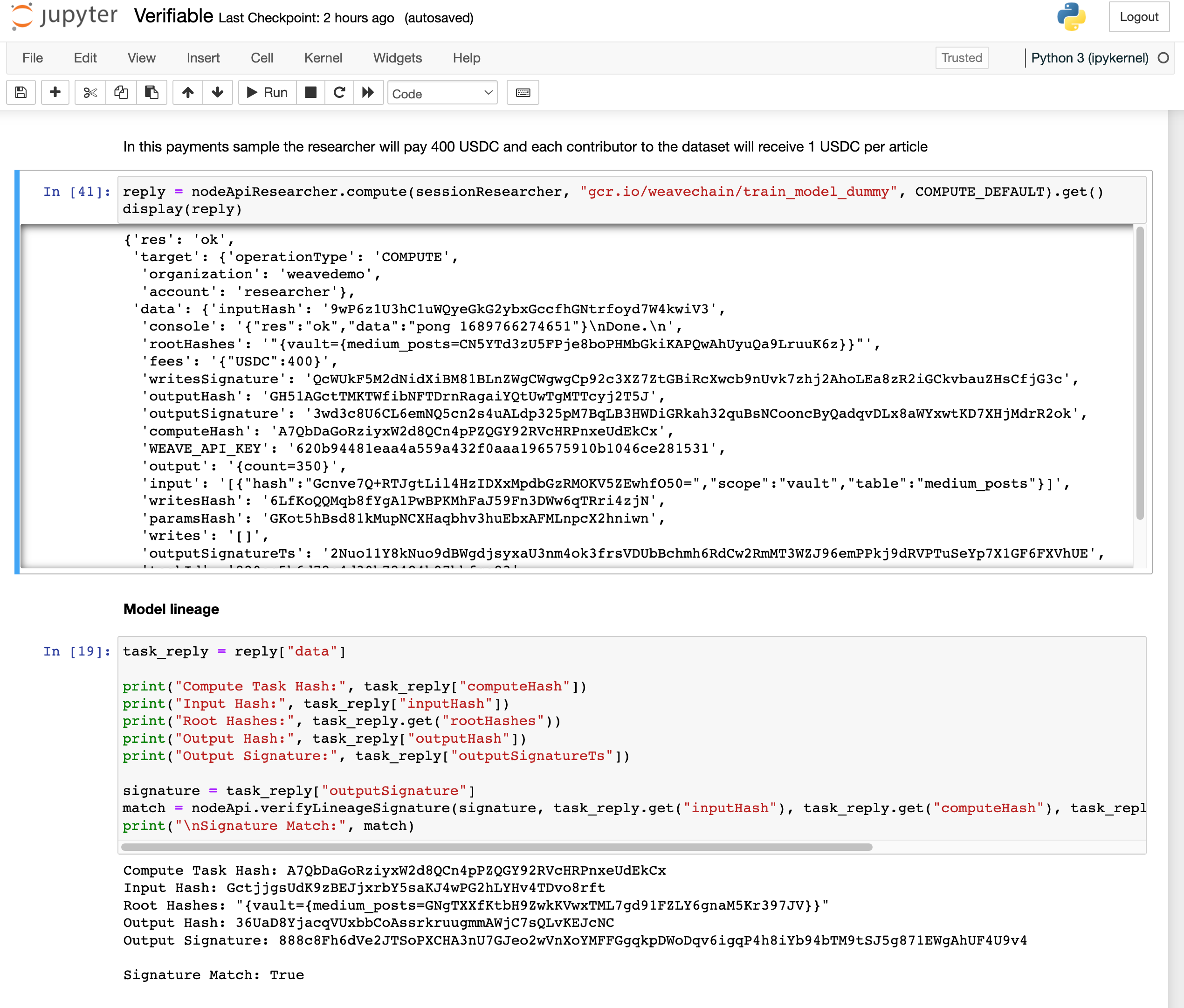
Computational lineage of AI training
-

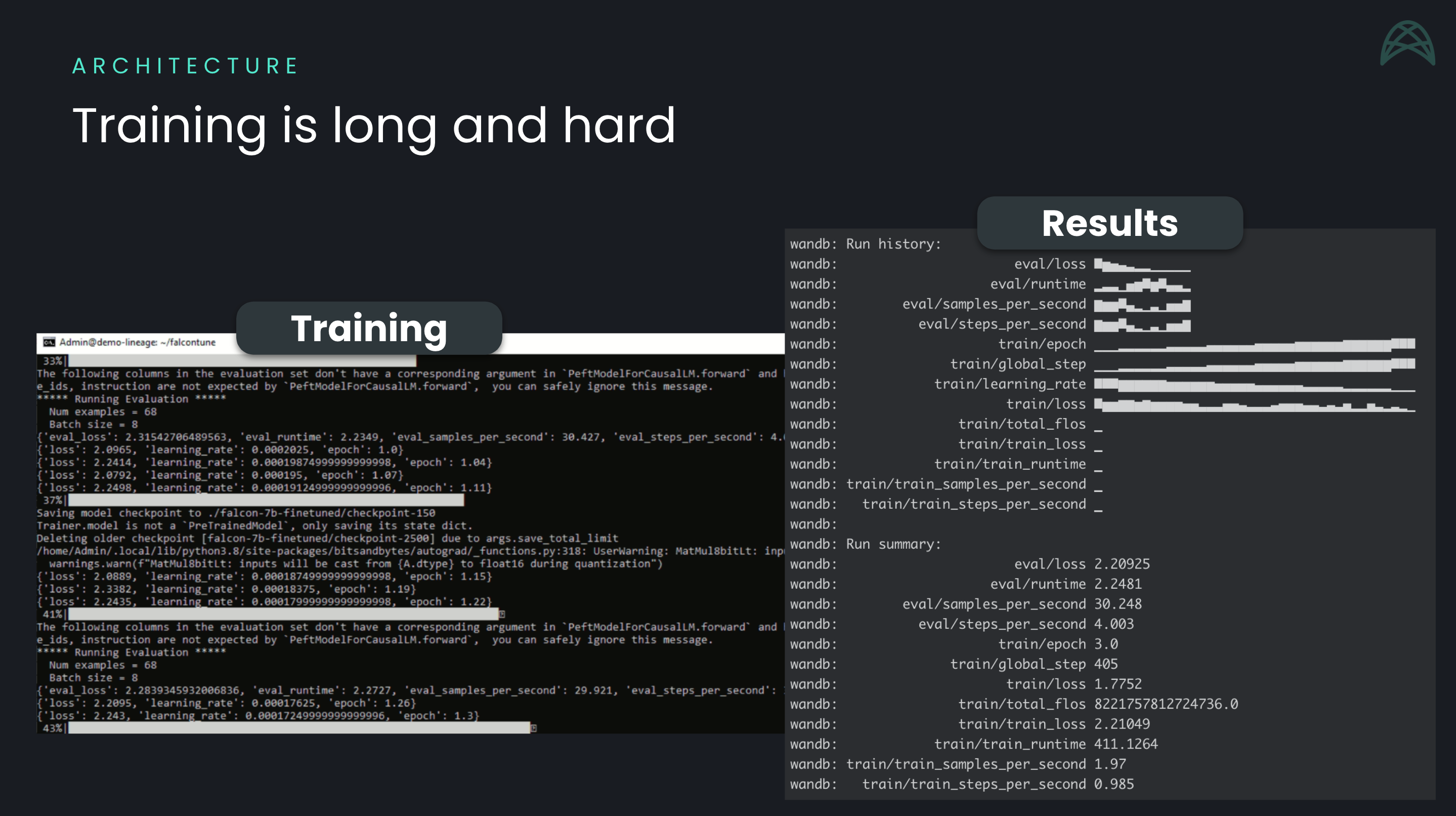
Executing fine-tuning using blog articles
-
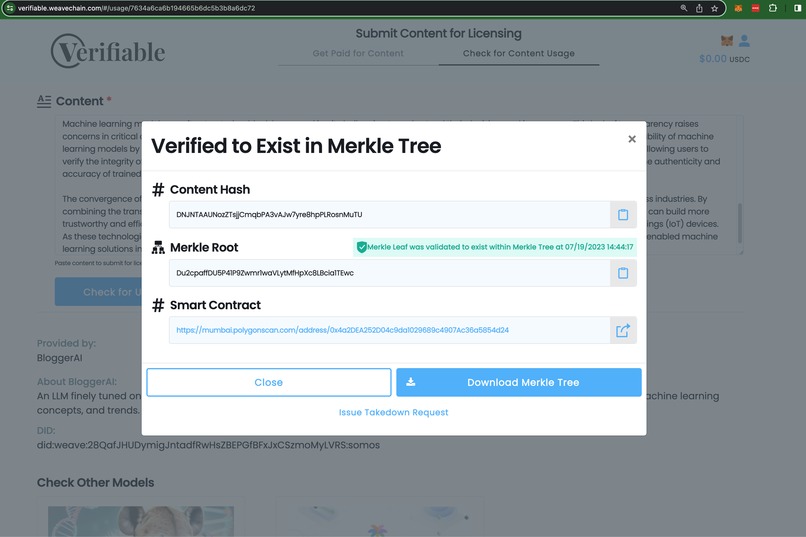
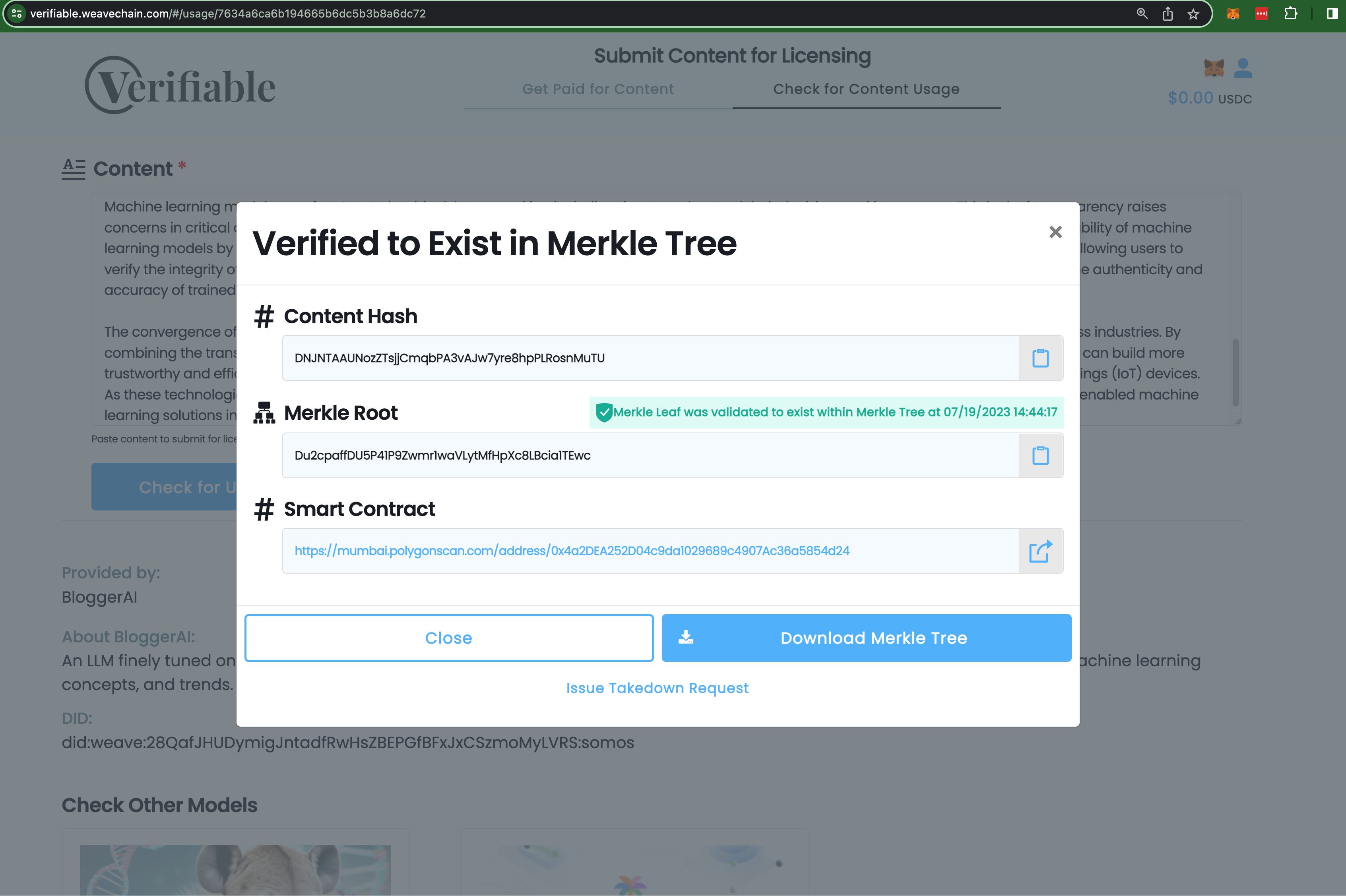
Validating inclusion
Inspiration
We were inspired by the social and legal challenges plaguing generative AI products. The lawsuits against OpenAI by Sarah Silverman and others are just the beginning. We wanted to provide an easy way for all the parties involved to operate more transparently and receive compensation when appropriate. We believe verifiable, trusted chains of data with easy Web3 monetization are the perfect solution for trainers, content creators, and the users of generative AI products.
What it does
- Provides a way for LLM trainers to prove what data was used to train their models in a zero-trust environment.
- Provides a way for LLM trainers to license content directly from individual creators and publishers using hyper-efficient Web3 payments.
- Provides a way for content creators to verify their content’s inclusion in any one of the models providing verified chains of trust for the data used in model training.
How we built it
First, we established a data access pipeline through Weavechain to establish our notarized source data. Weavechain also created a computational lineage of the training by chaining that with a hash of the model and of the output, signing this by the node orchestrating the training. It also handled storing the immutability proofs on-chain for the data that goes into models training or fine-tuning. We used dockerized tasks for compute to data to allow any model training or fine tuning and used Falcon LLM (the 7B parameters variant) as an example.
In the frontend app, we made it so that writers hash and sign their content and they get compensated at training time by making token transfers in a custodial wallet based on the number of rows they contributed.
We had to extend the core backend code with a new way to build Merkle Trees to test content inclusion with Locality Sensitive Hashing in order to be able to provide a solution for matching altered content.
Challenges we ran into
- Package dependency incompatibilities and libraries not working with the latest cuda drivers when trying to finetune Falcon LLM.
- High computational requirements for working with LLMs.
Accomplishments that we're proud of
We are proud of our ability to conceptualize and develop a complex framework that addresses the social and legal challenges associated with generative AI products. We were able to devise a solution that promotes transparency and fair compensation for all parties involved. Our framework not only helps AI trainers prove the data used in their models, but also enables content creators to verify their content's inclusion in these models. Despite the complex nature of this task, we were able to make significant progress within the short span of this hackathon, partially because of the robust infrastructure that Weavechain offers for building, so we’re proud of our work building Weavechain over the last years as well.
Also, we were super excited to be able to implement Locality Sensitive Hashing, and are curious to explore using embeddings in a similar fashion
What we learned
During this hackathon, we learned the immense value of having a robust underlying infrastructure when embarking on complex projects. Our existing Weavechain infrastructure allowed us to focus on the specific challenges of our project, rather than getting bogged down with foundational technical issues. This significantly accelerated our progress, enabling us to create a complex framework addressing the social and legal challenges associated with generative AI products within the short span of the hackathon. It was a powerful lesson in the importance of solid groundwork and the efficiency it can bring to development processes.
What's next for Verifiable
- Talk with model trainers and tuners to understand more about their concerns and appetite for defense technology.
- Enable filters for trainers to be able to choose which submitted content they train on. This could be manual, or likely programmatic filters like size of content, reputability of the author, etc.
- Provide a way for content creators to verify inclusion in any model and to have payments routed to them at inference, whenever their content was used to generate an output.
- We’d love to continue with other content forms besides text. We think art and music are good places to start considering the climate of fear and stress around copyrighted content making its way into generative AI from stakeholders in those industries. We want to be every trainer’s first stop in ensuring their data is fairly trained so they can defend themselves against claims and promote the public good of doing things the right way.
- Ideally content writers would contribute individually and use their private keys to sign content for authenticity, but the initial content onboarding will likely happen from pre-existing collections. In order to support that scenario we also had to add a mechanism to create accounts for authors by publishers, the idea being that the publisher can act as an intermediary trust point and these accounts will receive micropayments and can be claimed later by the authors themselves (via email magic link for example) to transfer the funds to their privately held account.







Log in or sign up for Devpost to join the conversation.