-
-
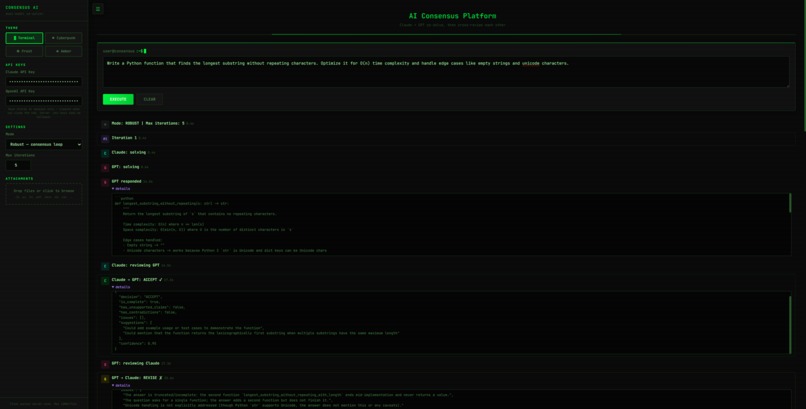
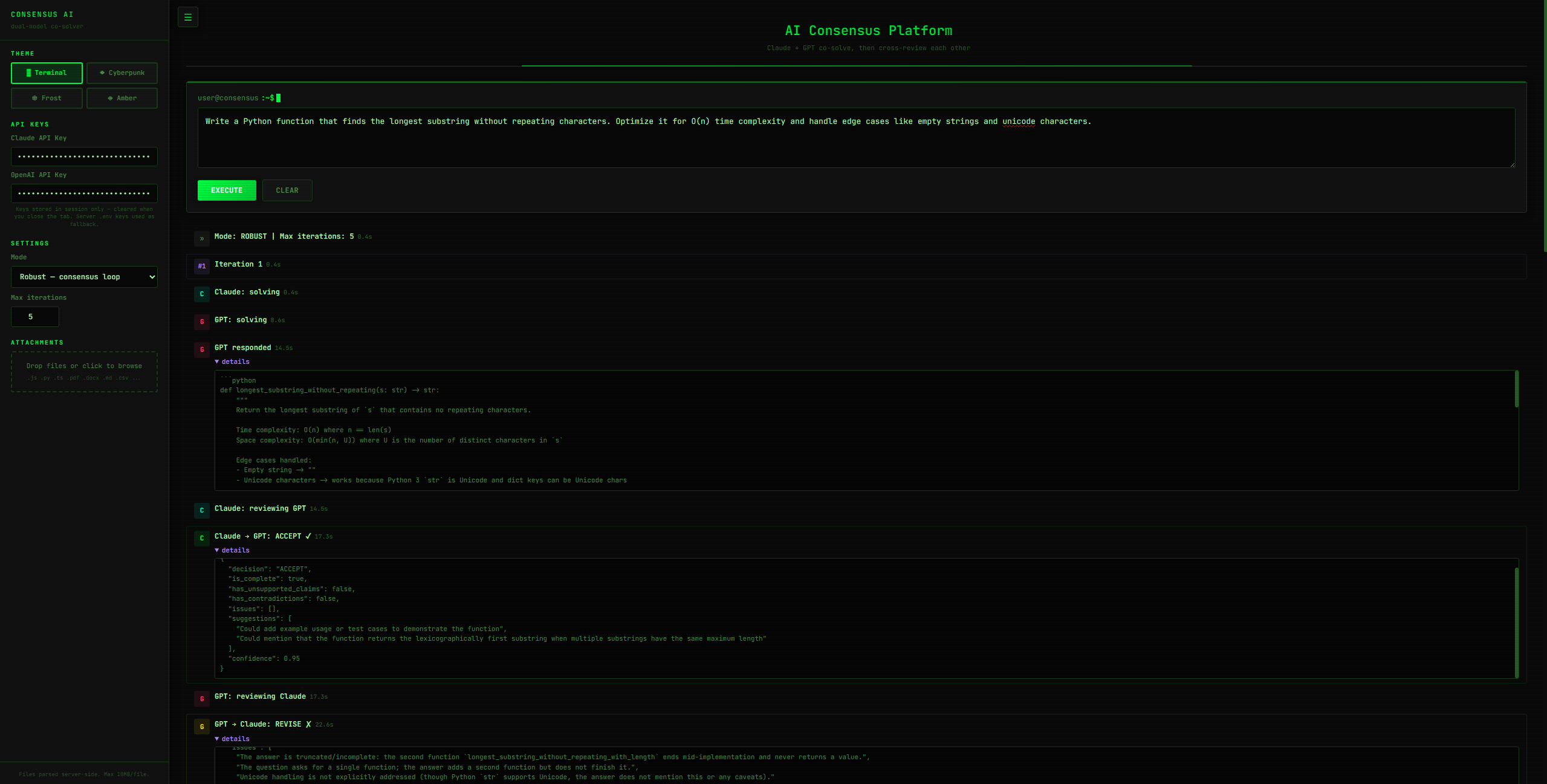
Demo UI
Inspiration
I built Veridict because I needed it. While automating job applications with AI, I hit a bug where Claude got stuck in a loop and couldn't produce working code. Out of frustration, I asked GPT the same question, copied its solution, and pasted it back into Claude's context. Claude immediately corrected itself and produced the right code.
That moment clicked, these models don't just autocomplete, they actually reason and can self-correct when given a different perspective. But doing this manually every time was painful: copy from one tab, paste into another, compare outputs, repeat. I thought, why not automate the entire back-and-forth?
What it does
Veridict is an AI consensus platform that orchestrates Claude and GPT to collaboratively solve problems. Here's how it works:
- You submit a question or task (code, debugging, writing, analysis, anything)
- Both Claude and GPT independently generate solutions
- Each model reviews the other's answer through structured JSON evaluations, checking for completeness, fabrications, and contradictions
- They iterate up to 5 rounds, refining their answers based on each other's feedback
- You get a final high-confidence consensus answer, not just one model's best guess
It supports 30+ file types, so you can upload code files, documents, or data and let both models analyze them together.
How I built it
The frontend is built with React and TypeScript, designed to show the multi-round debate in real-time so users can watch the models think and challenge each other.
The backend orchestrates two separate LLM APIs, Anthropic's Claude API and OpenAI's GPT API, managing the iterative cross-checking loop. Each round involves parallel API calls to both models, structured JSON evaluation parsing (completeness, accuracy, contradiction detection), and multi-gate validation to decide if consensus has been reached or another round is needed. I implemented exponential backoff retry logic for handling rate limits and transient failures, and Server-Sent Events (SSE) for real-time streaming so users see responses as they generate.
The whole thing is deployed on DigitalOcean.
Challenges I ran into
Different response formats, Claude and GPT structure their outputs differently. Getting them to evaluate each other required careful prompt engineering and JSON schema enforcement so the cross-review was actually meaningful.
Async state management, Two API streams feeding into each other in a loop is a non-trivial state problem. Handling timeouts, partial failures, and displaying a multi-round conversation cleanly in React took multiple iterations.
Knowing when to stop, Defining "consensus" programmatically was tricky. I built a multi-gate validation system that checks agreement scores across completeness, factual accuracy, and logical consistency, the loop terminates when all gates pass or after 5 rounds.
Cost management, Every round means 2+ API calls. I implemented smart early termination and caching to keep costs reasonable.
Accomplishments that I'm proud of
I built and shipped the entire platform end-to-end as a solo developer. The real-time streaming UI lets you watch two AIs debate live, it's genuinely fun to watch. The multi-gate validation system catches fabrications and contradictions that a single model would miss. Best of all, I use it daily for my own coding, debugging, and writing — it's a tool I built for myself that actually stuck.
What I learned
I gained a deep understanding of prompt engineering for structured outputs across different LLM providers, and how to orchestrate multiple async AI workflows with graceful failure handling. The biggest takeaway was the power of adversarial review, models catch each other's mistakes in ways that self-review often misses. I also learned a lot about real-time streaming architectures with SSE for long-running AI tasks.
What's next for Veridict
Adding more model providers (Gemini, Llama) for 3-way consensus. Persistent conversation history so you can build on past debates. A VS Code extension so developers can trigger consensus checks directly from their editor. And fine-tuning the evaluation prompts based on task type (code vs. writing vs. analysis).
Built With
- anthropic-api
- digitalocean
- gemini
- javascript
- node.js
- openai-api
- react
- server-sent-events
- typescript
