
Inspiration
In November 2025 Anthropic documented GTG-1002, a state-sponsored operation that drove Claude Code through reconnaissance, exploitation, and lateral movement at 80 to 90 percent autonomy, at request rates it called physically impossible for a human. That is the offensive side. Protocol SIFT is the defensive answer, meeting AI threat speed with defensive AI orchestration. VERDICT sharpens that orchestration so a responder can trust an autonomous agent with the evidence and with the truth of the findings.
What it does
VERDICT extends Protocol SIFT into a fully autonomous triage analyst. You point it at a case (a disk image, a memory capture, a packet capture, or several from the same host) and it investigates the way a senior analyst does at 3 AM during an active incident.
It orients on the evidence and hashes every object read-only before touching it. It writes down falsifiable hypotheses and names the artifact that would confirm or kill each one. It then sequences tools adaptively, running the cheapest tool that can decide a hypothesis and letting each result choose the next move, rather than marching through a fixed pipeline.
The part that matters most is what happens before a finding reaches the report. Every claim is checked by a deterministic corroboration engine that re-reads the actual tool output and confirms the asserted value is really there before anything is called confirmed. When the cited output does not support a claim, the claim is caught as a likely hallucination and retracted. When two sources disagree, the agent runs a third to break the tie. Every change of mind is logged with the exact execution that triggered it.
The output is a structured investigative narrative plus an honest accuracy report, generated from the run ledger, in which confirmed facts are separated from inferences and every sentence traces back to a specific tool execution.
How we built it
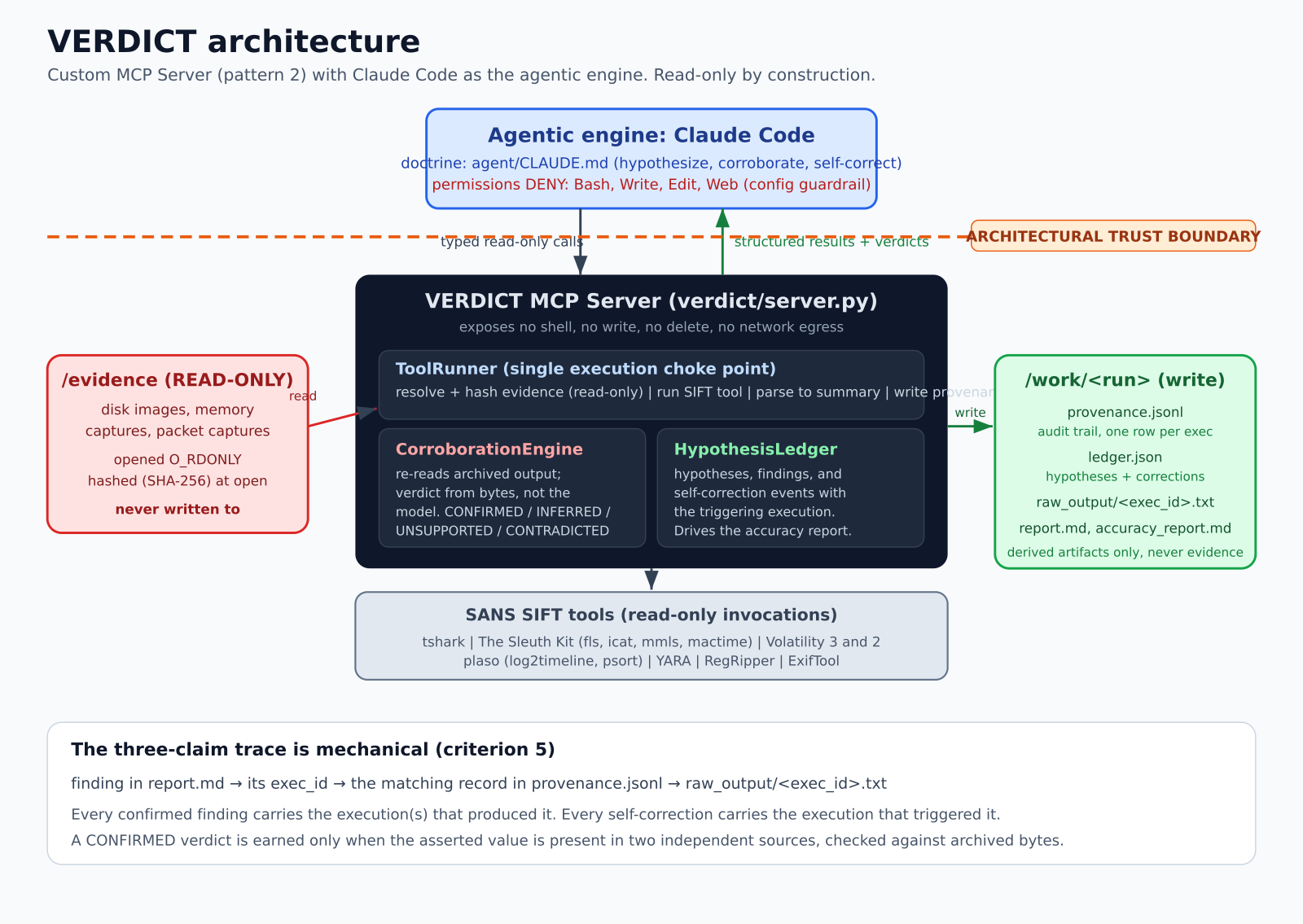
The architecture is a Custom MCP Server (pattern 2 in the brief), with Claude Code as the agentic engine. The server exposes the SANS SIFT toolchain as typed, read-only functions instead of a shell. The agent has no execute_shell, no write primitive, and no network egress. It cannot run a destructive command because no such tool exists in its menu. Evidence safety is a property of the architecture, not an instruction in a prompt.
The pieces: an evidence vault that opens originals O_RDONLY and refuses any write target inside the evidence root; a tool runner that is the single choke point for every forensic binary, parsing raw output into compact summaries while archiving the full output and writing one provenance record per execution; a corroboration engine that verifies each asserted value against the archived raw bytes, requires the value to be referenced by the claim, and (for an inference) present in two distinct evidence objects, so a confident wrong answer cannot be confirmed by assertion alone; a hypothesis ledger from which the narrative and accuracy report are generated; typed wrappers over tshark, The Sleuth Kit, Volatility 3 and 2, plaso, YARA, RegRipper, plus Windows execution-evidence tools; and a Docker image so a judge can reproduce a full investigation with one command.
We verified it on the genuine SANS SIFT Workstation: the official OVA was booted and the full autonomous agent ran end to end against the real toolchain, with the run committed to the repository. The audit trail is tamper-evident: each provenance record commits to the digest of the one before it, forming a hash chain sealed at the end of every run. A hallucination-rate benchmark catches 5 of 5 injected fabrications with zero false confirmations. Measured against the actual installed Protocol SIFT proof-of-concept, the baseline permits 10 of 12 evidence-destroying commands; VERDICT permits 0.
Challenges we ran into
The hardest problem was making self-correction real rather than theatrical. We built the trigger into the data path: a corroboration verdict computed from archived tool output. The agent corrects itself because the bytes do not support the claim, and that moment is logged with its trigger, so it cannot be faked. The second challenge was context overload, the documented source of the baseline's hallucinations; parsing each tool's output into a compact summary while archiving the raw output solved both the context and the audit problem at once. The third was proving evidence integrity rather than asserting it, so we made the server incapable of writing to evidence and re-hash the originals at the end of every run.
What we learned
For an autonomous responder, the trust boundary belongs in the architecture. A prompt that says "be careful" is not a control; a server that exposes no dangerous function is. The same logic applies to accuracy: rewarding a model for confident answers teaches it to guess, so we built a layer that rewards proof and catches guesses, and let honesty fall out of the data structure.
What's next for VERDICT
Deeper multi-source correlation across three or more evidence types from one host, more SIFT tools exposed as typed functions, and an expanded community hallucination benchmark. The corroboration and provenance layers are designed to be reused by any Protocol SIFT submission, not just this one.

Log in or sign up for Devpost to join the conversation.