-
-
 GIF
GIF
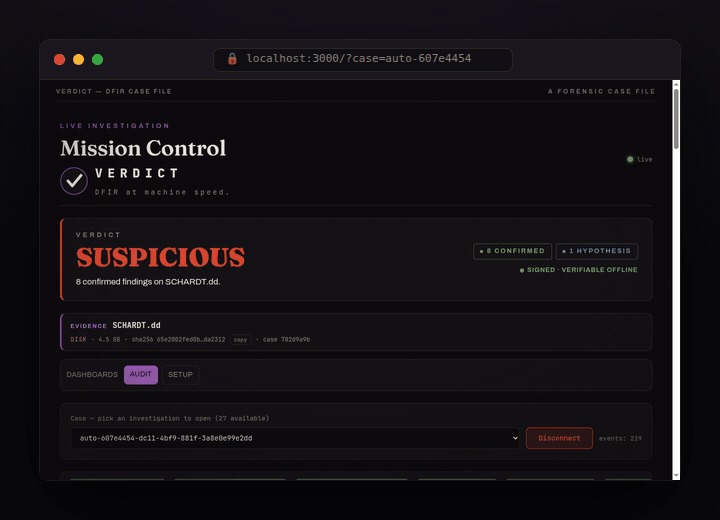
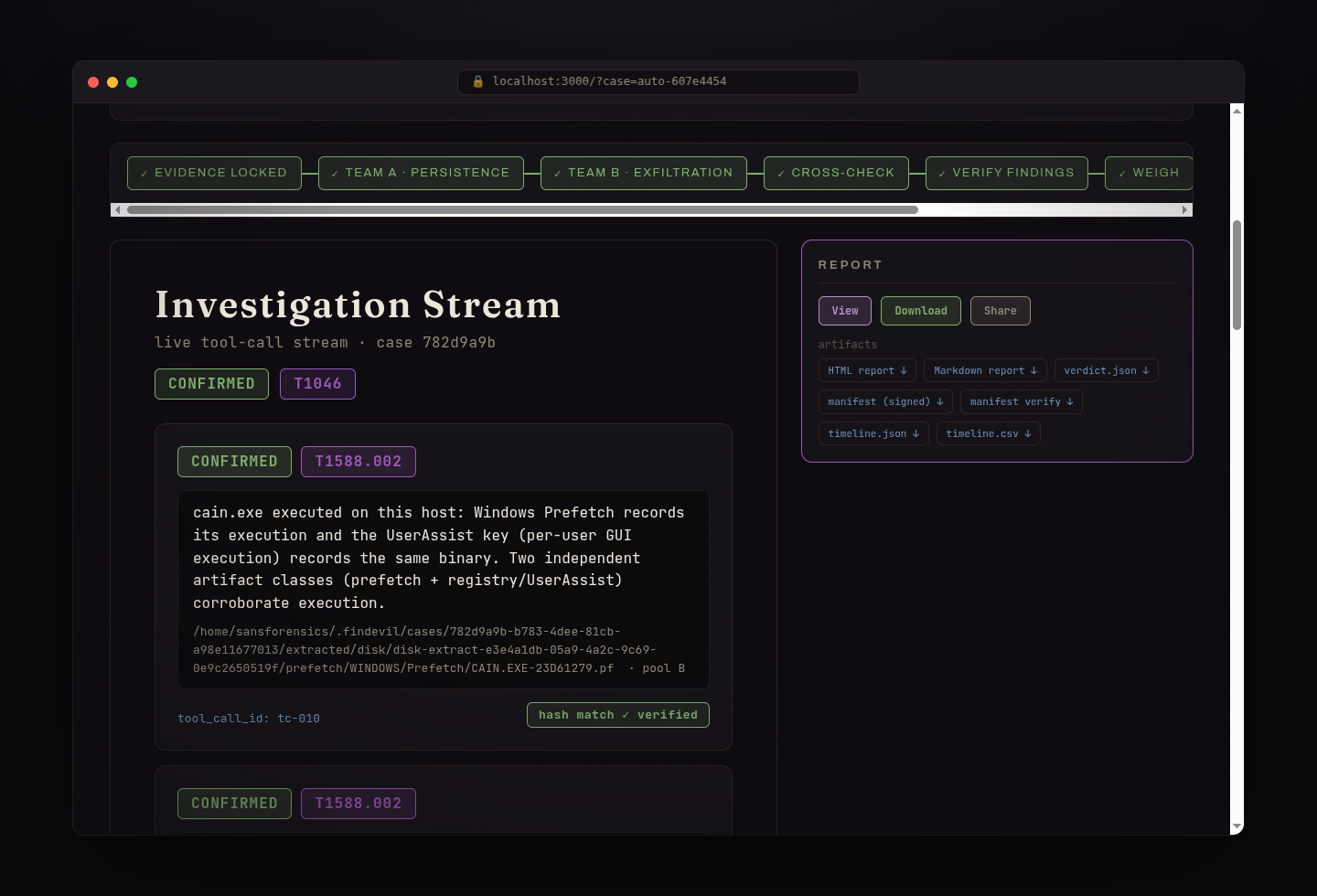
Watch it live: findings appear the moment they are proven, tagged confirmed / inferred / hypothesis, each linked to its tool call.
-
 GIF
GIF
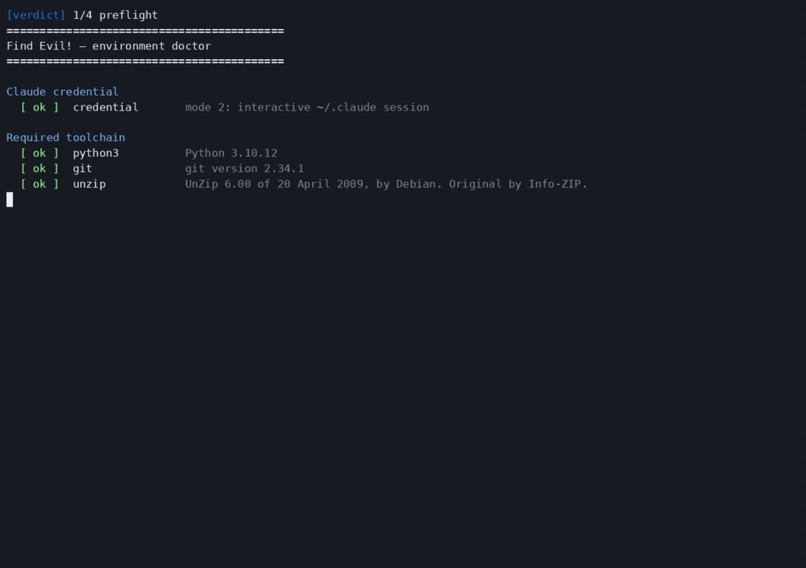
How you run it: scripts/verdict <evidence> in Claude Code. No separate server, the agent session IS the engine.
-
-
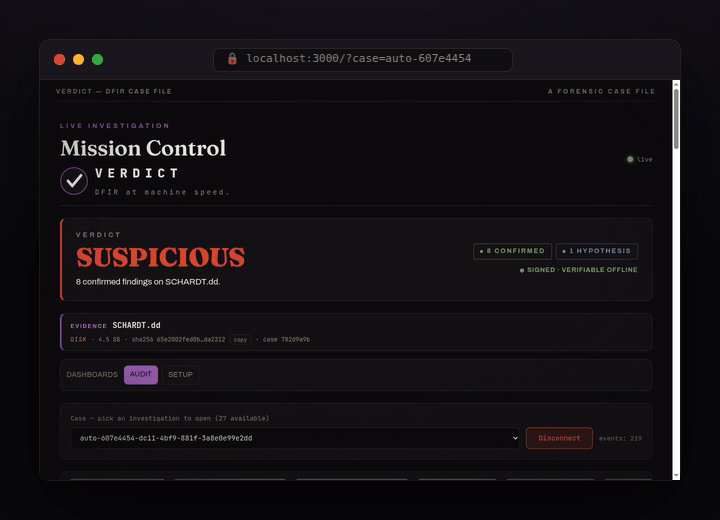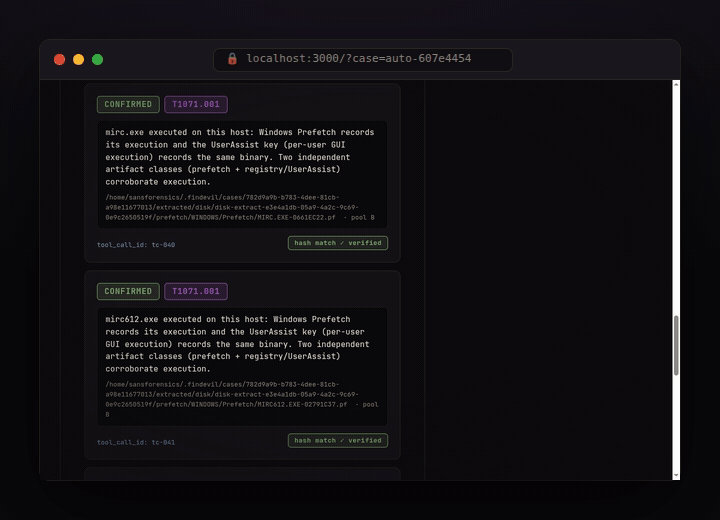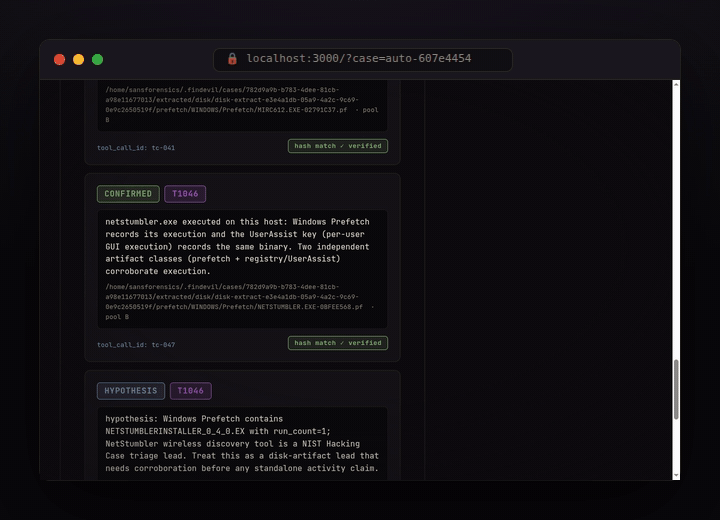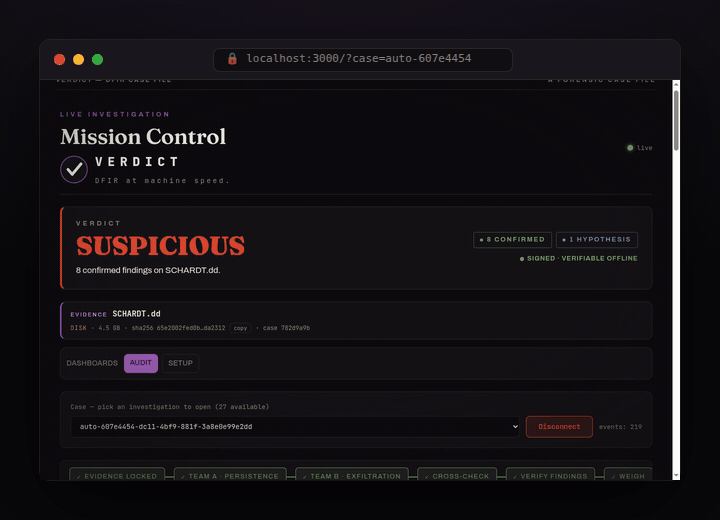
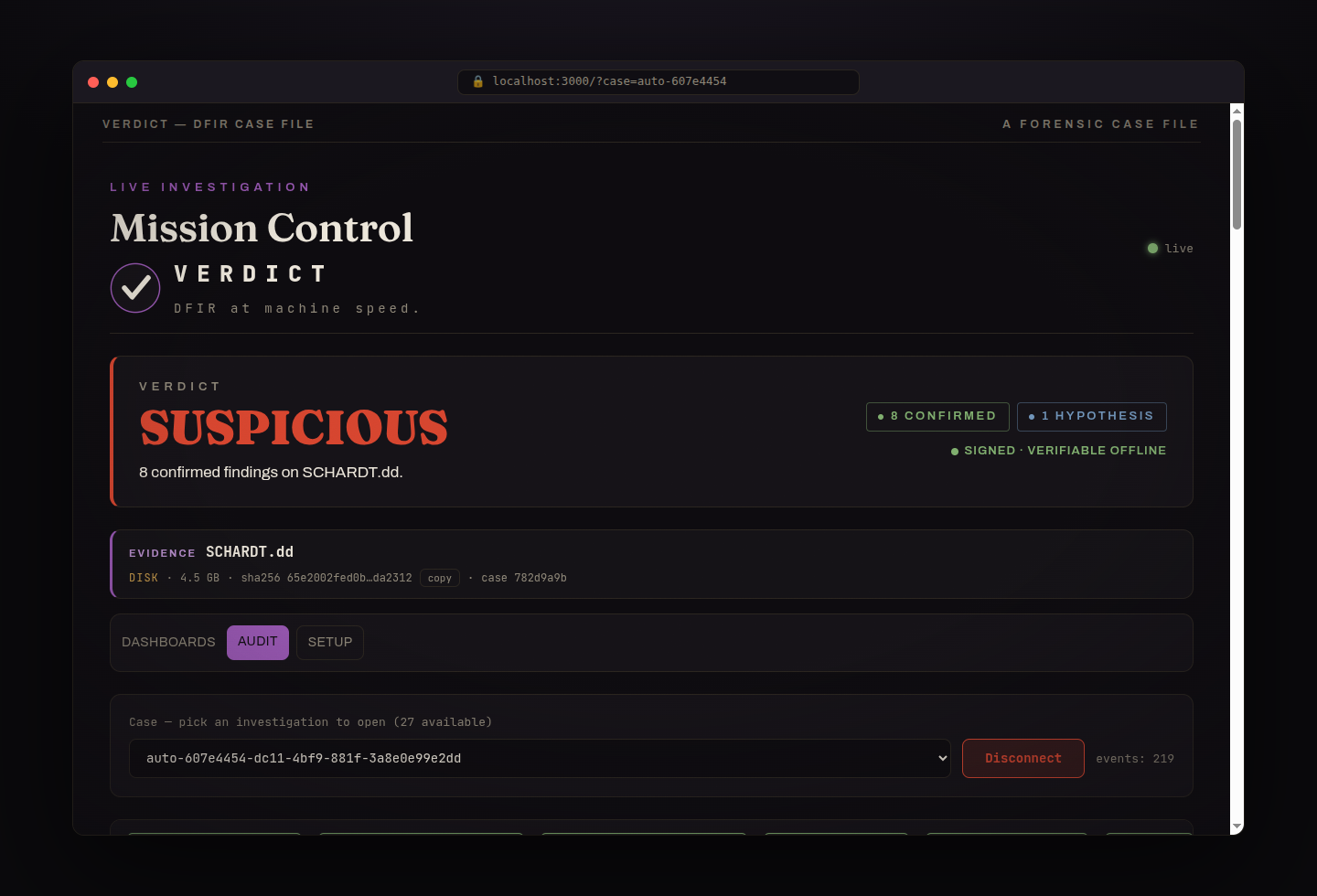
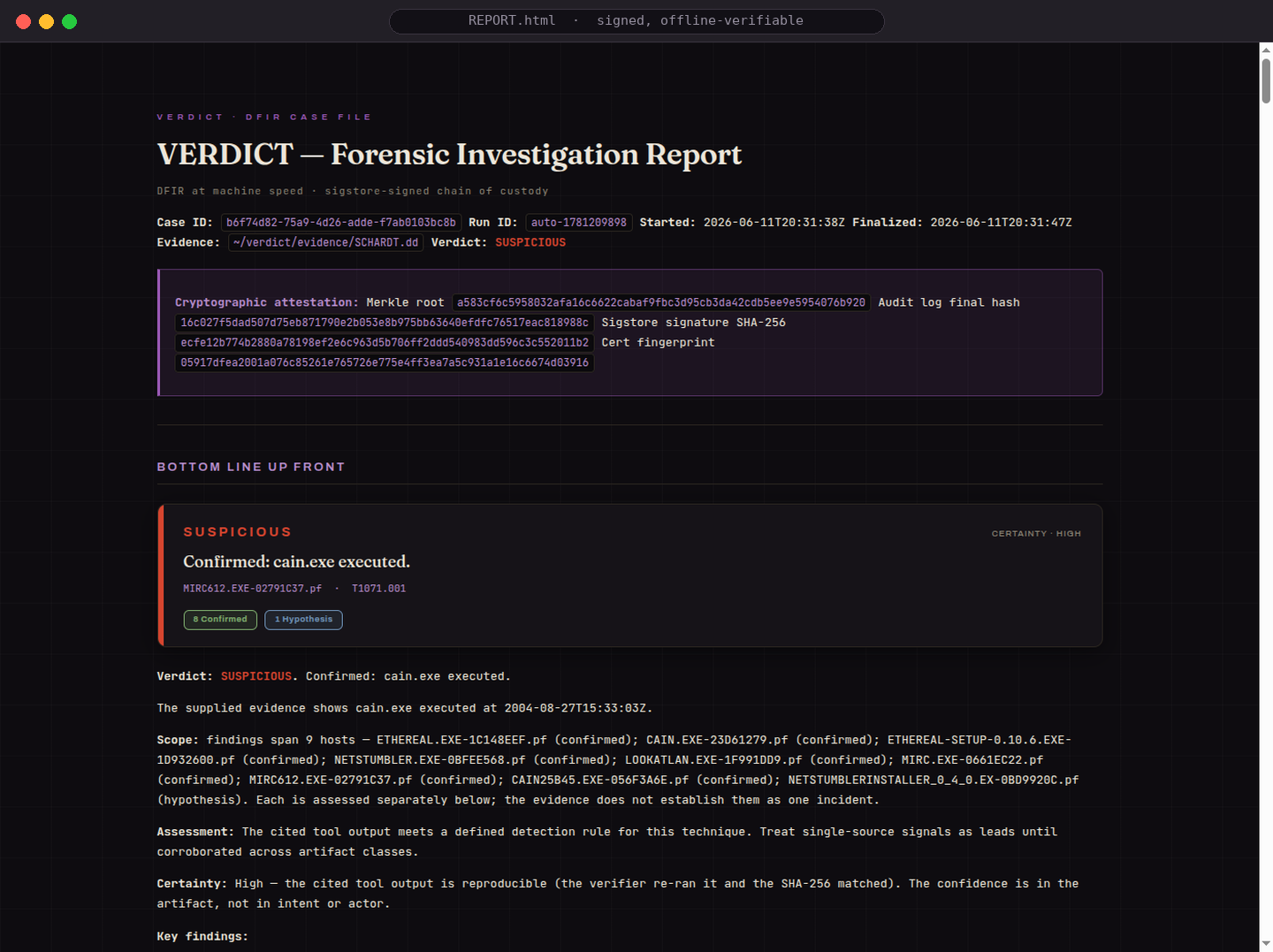
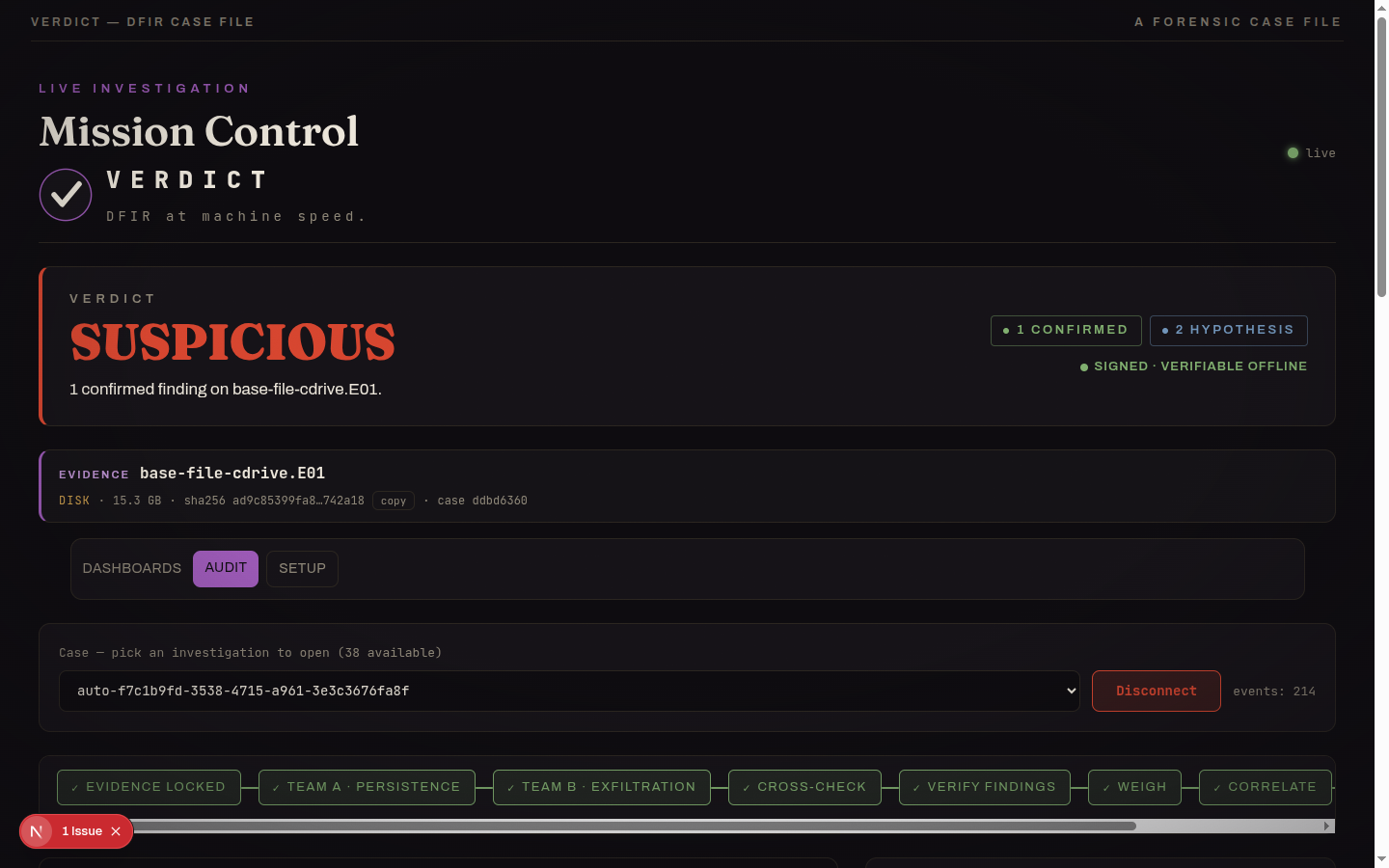
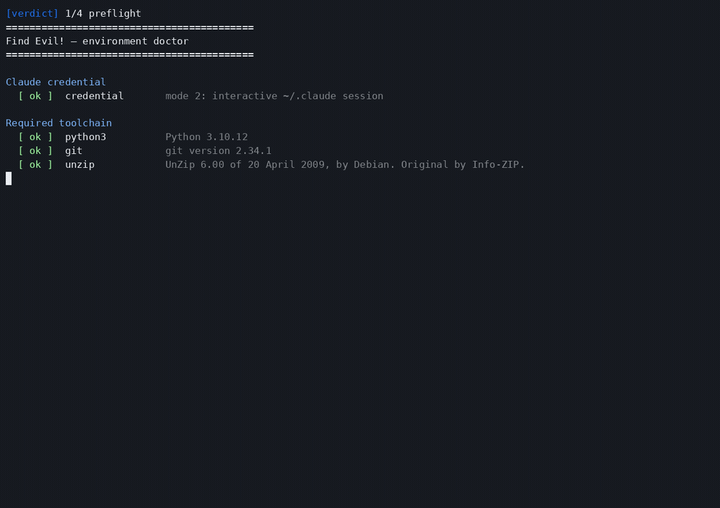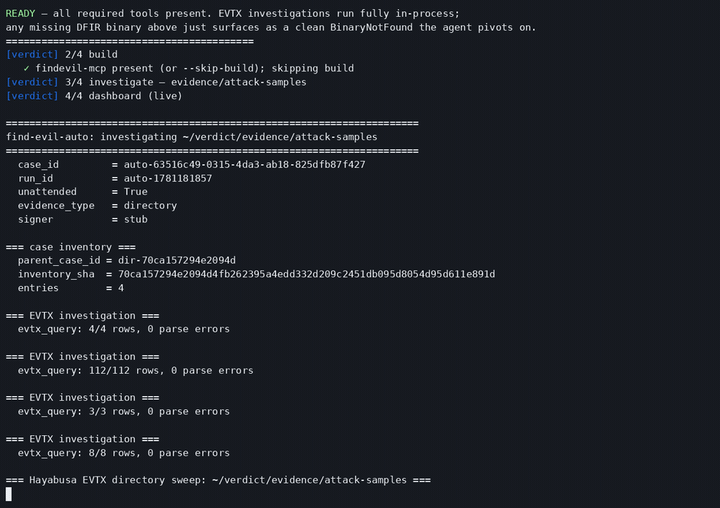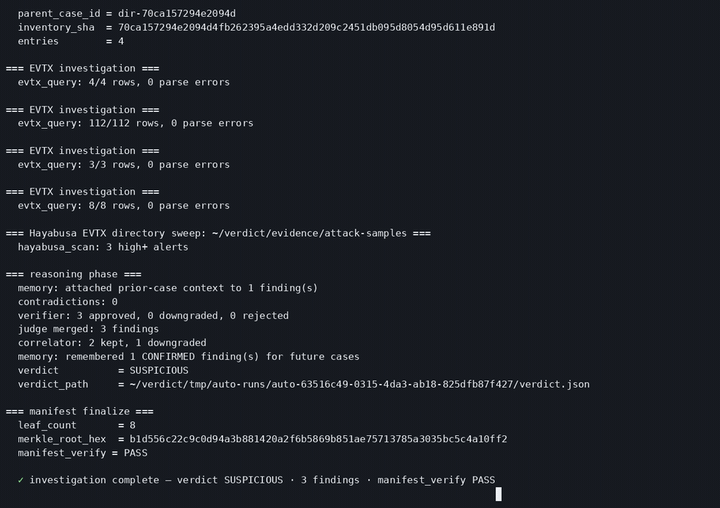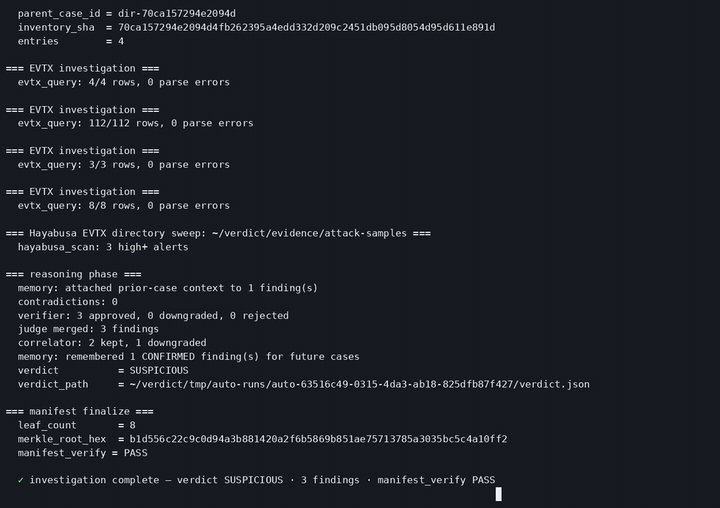
SUSPICIOUS, 8 confirmed findings on the NIST hacking case, signed and verifiable offline.
-
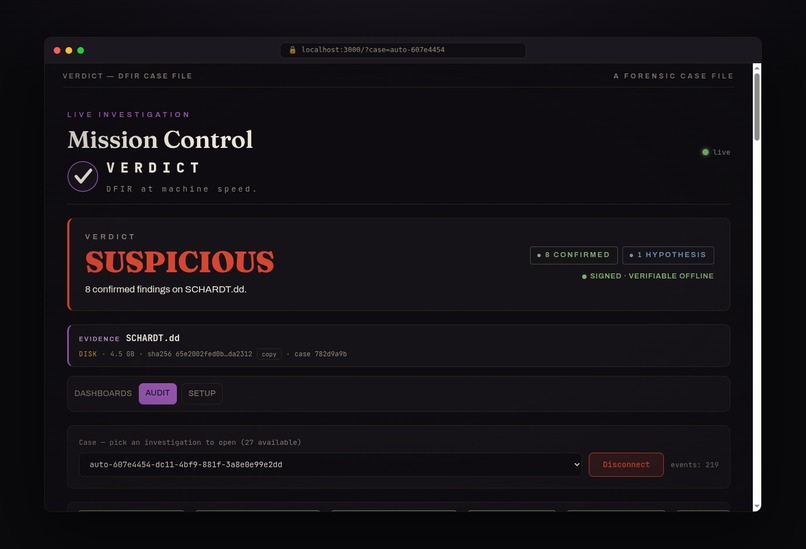
Every finding cites the exact tool call (tool_call_id + SHA-256) and a MITRE ATT&CK technique.
-
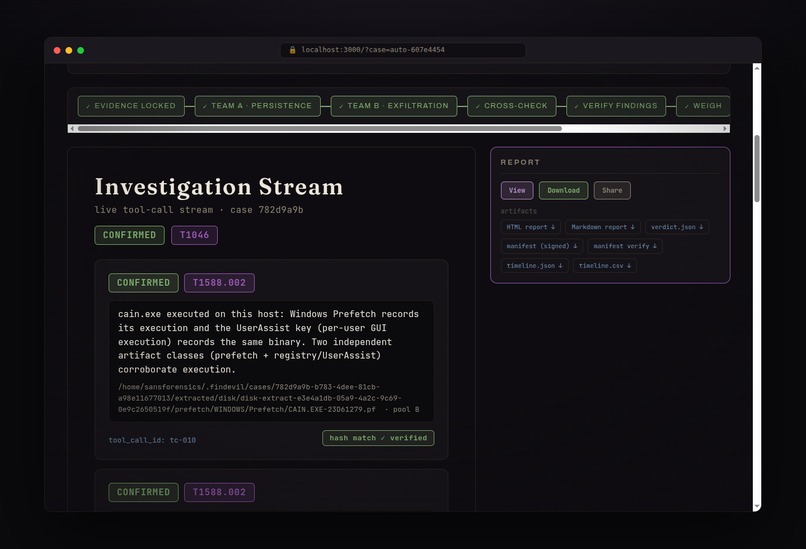
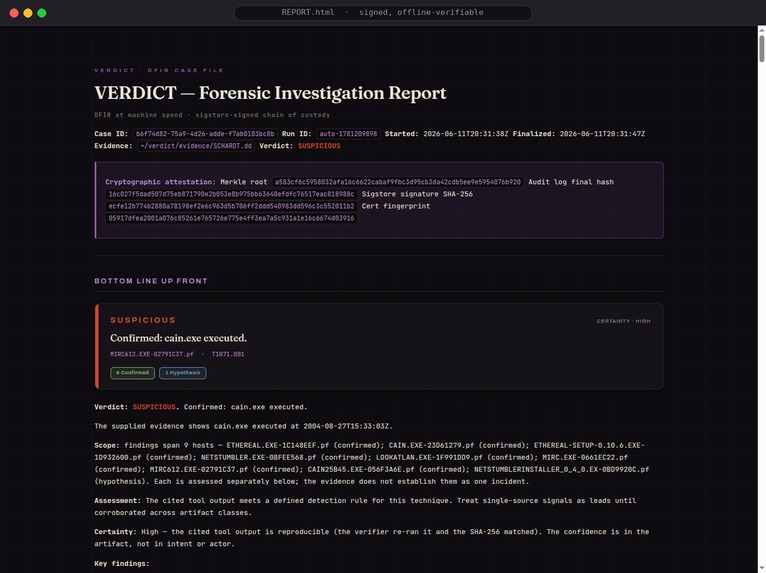
The signed analyst report: findings, ATT&CK coverage, a normalized timeline, and next analyst actions.
-
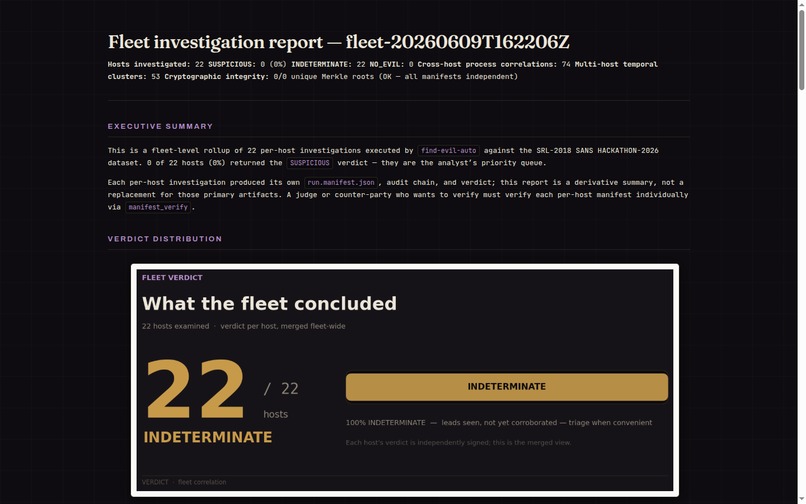
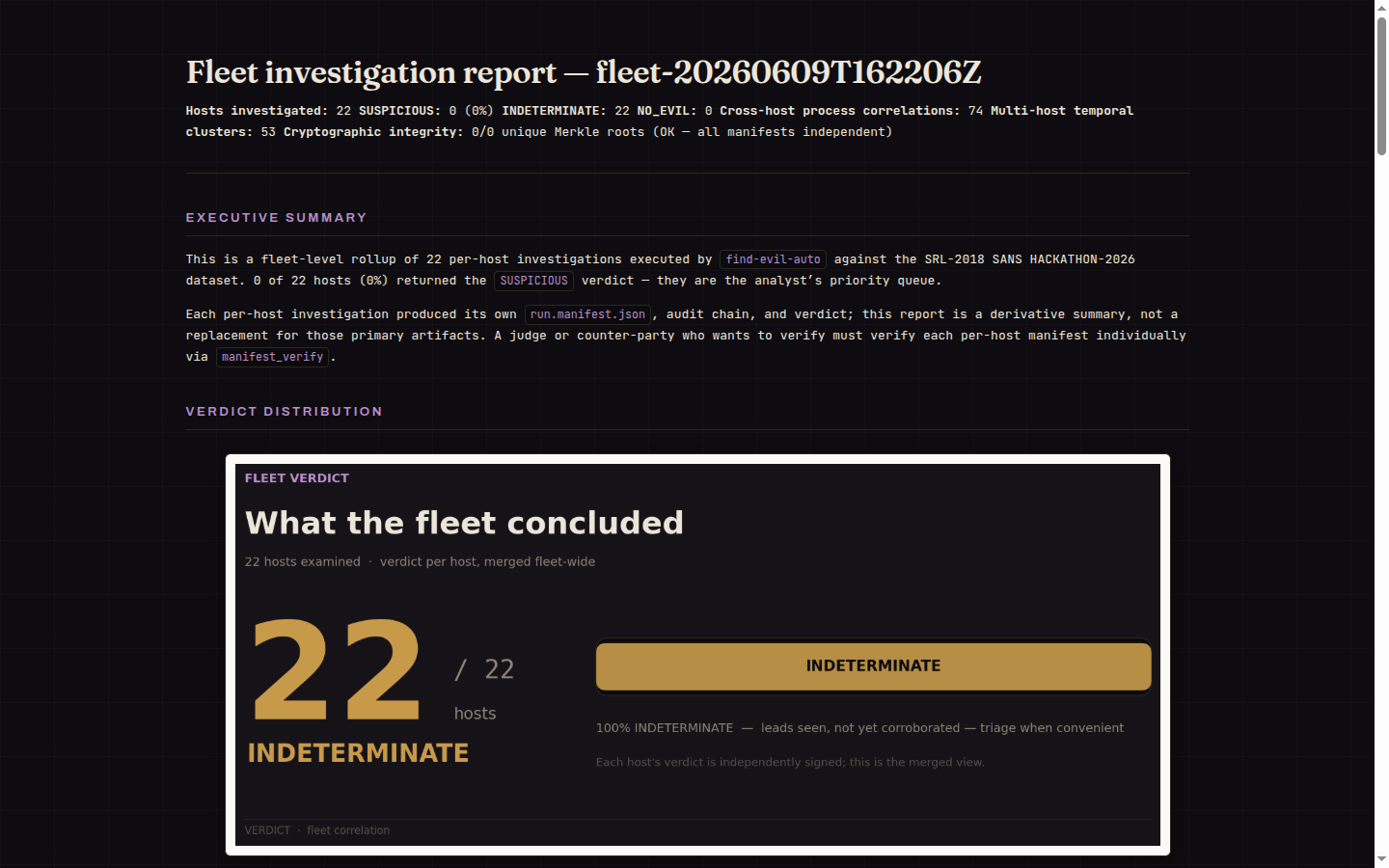
Scales to a fleet: 22 hosts, cross-host correlations and near-simultaneous process waves surfaced as leads.
-
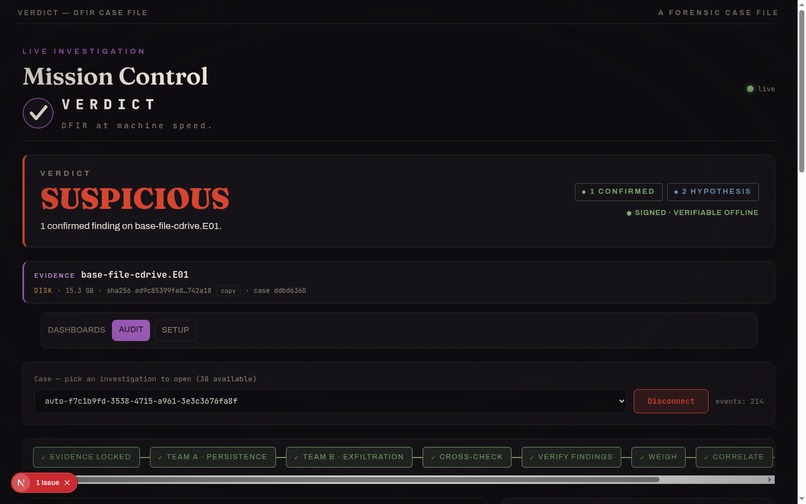
A second host flagged SUSPICIOUS: a confirmed Windows Security-log wipe (Event ID 1102).
-
 GIF
GIF
The whole workflow in one command: case_open, two competing agent pools, the verifier, the judge, and a signed verdict.
▶ The embedded video is the feature deep-dive — the agent live, with a real on-screen self-correction (plaso unavailable → adapts to mft_timeline). Prefer a 4-minute overview? https://youtu.be/4RQnVden6L8
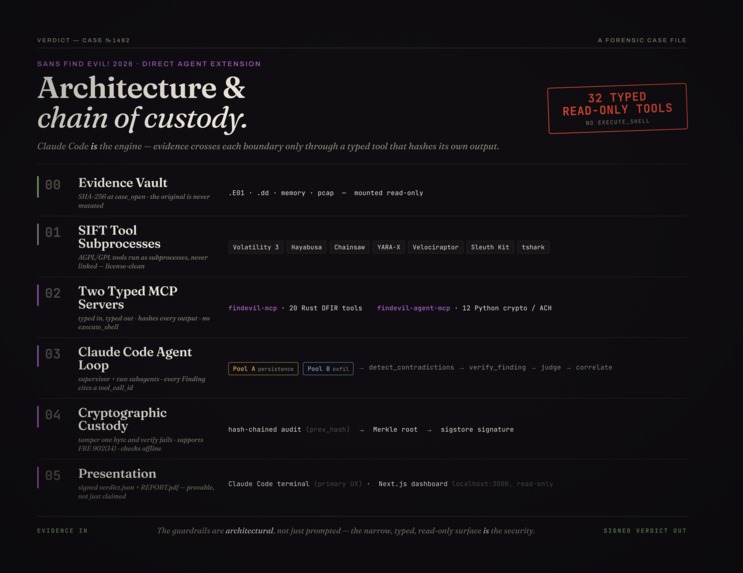
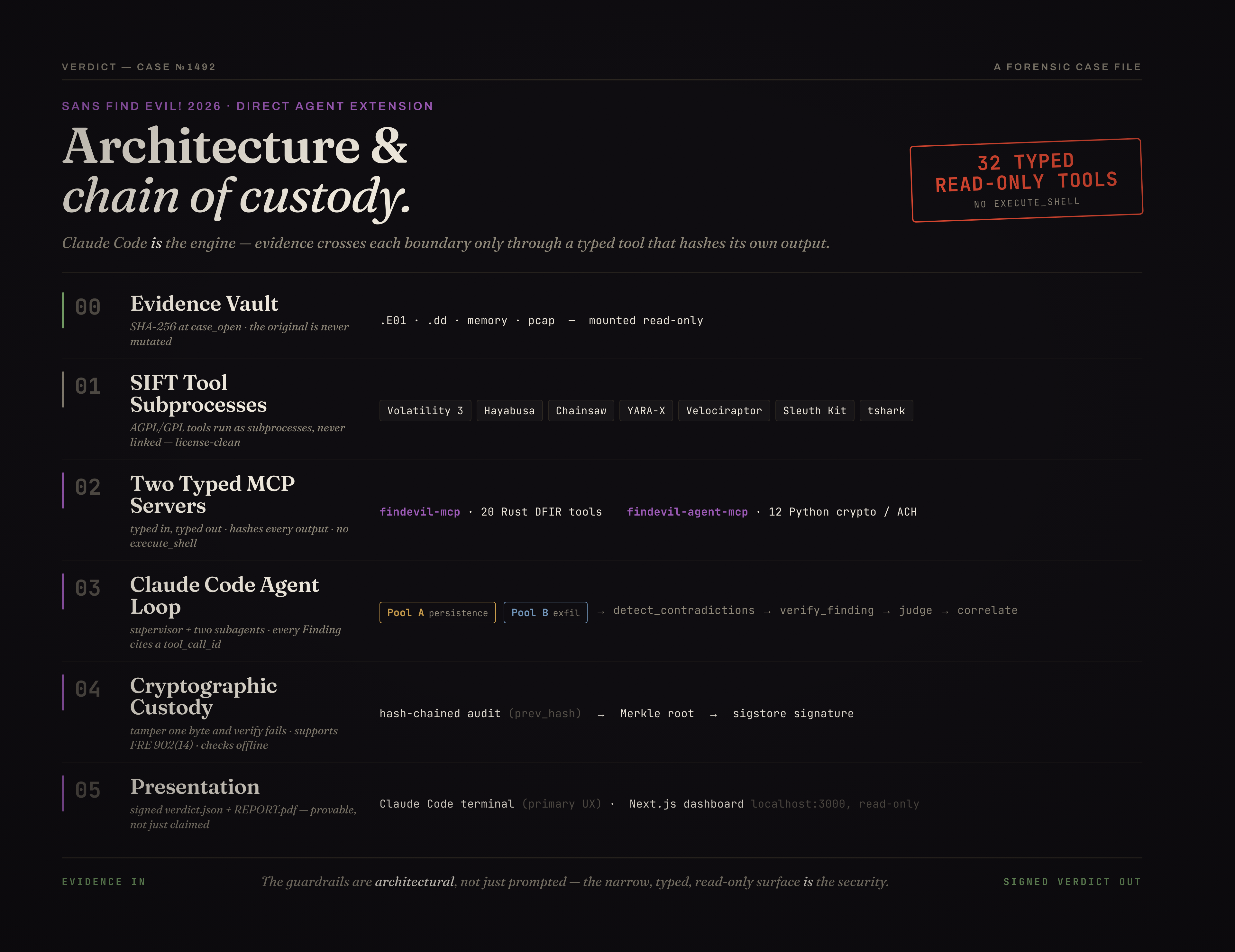
Built with Claude Code (Anthropic). The agent loop is Claude Code driving 43 typed, read-only MCP DFIR tools. A Claude credential (free or standard tier) is all you need for a live run.
VERDICT is a forensics agent. Point it at evidence from a compromised machine and it gives you a one-word verdict — SUSPICIOUS, INDETERMINATE, or NO_EVIL — and every finding links back to the exact tool call that produced it. The whole run is signed and hash-chained, so anyone can re-check the work offline later without taking our word for it.
Inspiration
When a Windows box gets popped, spotting a clue is the easy part. The hard part is proving what the attacker actually did, in a form that holds up when someone pushes back. By hand it's days of the same mechanics: mount the image, parse $MFT, walk Prefetch, query the event logs, scan memory. You finish with a pile of notes, not proof. We wanted something that would do the repetitive grind and hand back a verdict we could defend.
What it does
You run one command, scripts/verdict <evidence>, inside Claude Code, and that session turns into the analyst. There's no server to deploy and no separate API. It opens the case read-only and hashes everything with SHA-256 before touching it, runs a small fixed set of typed forensic tools across disk, memory, and network, checks every finding back against the raw tool output, and seals the result into a signed manifest with an analyst report. Feed it a single image or a folder of 22 hosts; the process is the same.
How it works
1. No shell, by design. There are 43 schema-validated tools, 31 in Rust for the DFIR work and 12 in Python for crypto, custody, and analysis, and not one of them is execute_shell. Four convenience MCP servers sit outside the audit chain and can't produce findings. A narrow surface is the security argument: an agent with no way to open a shell can't be talked into opening one.
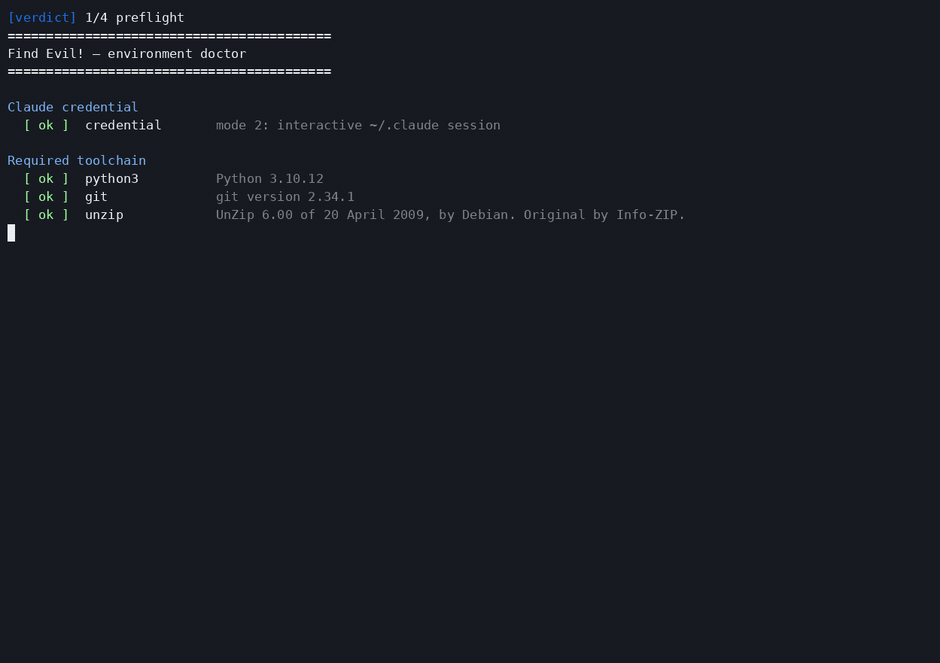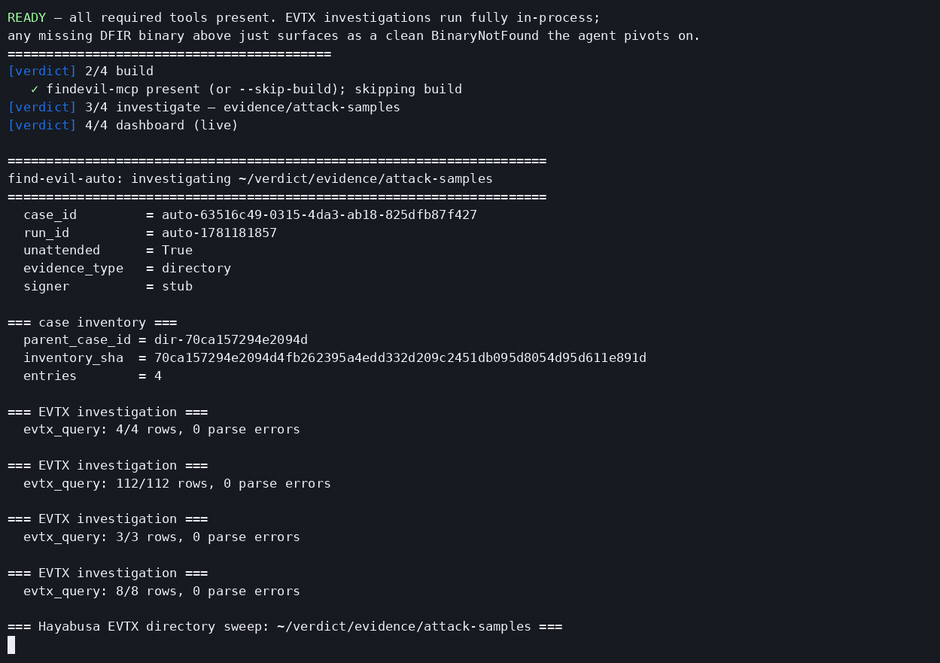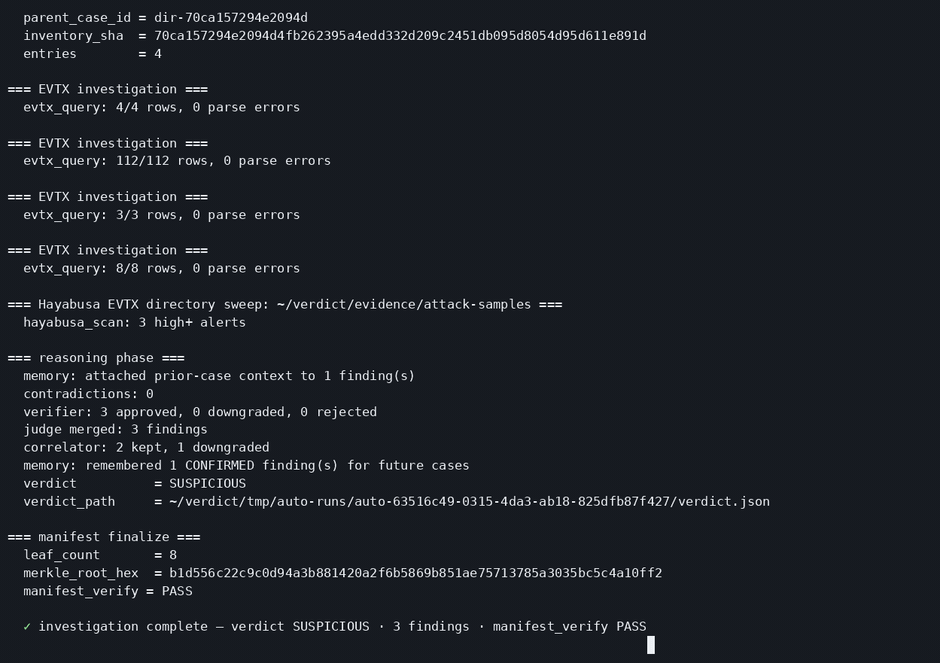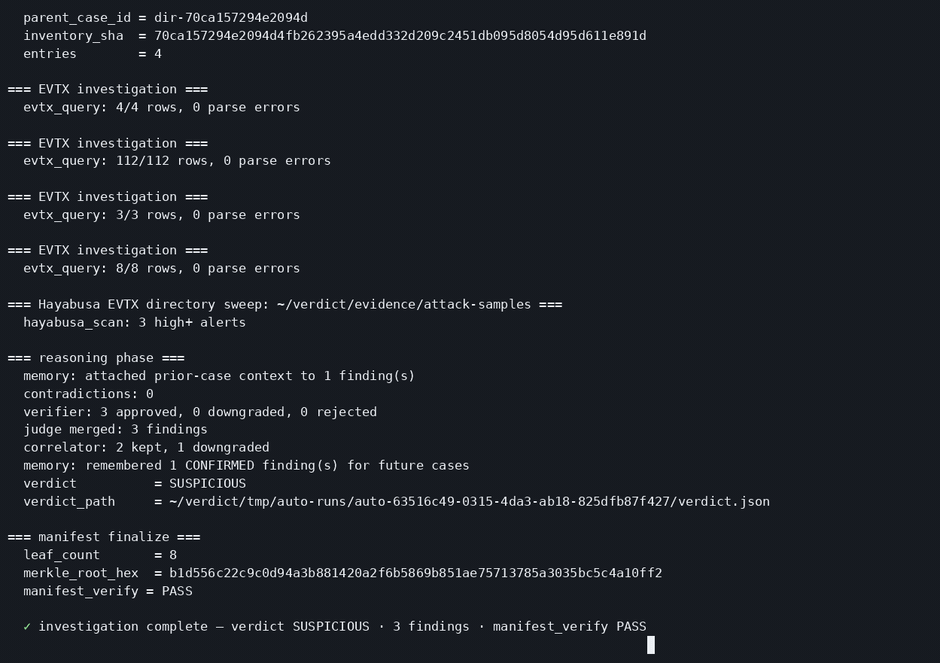
2. Two teams that disagree out loud. This is Heuer's Analysis of Competing Hypotheses built as agent structure. One pool works the evidence persistence-first; the other works it exfil-first. When they reach different conclusions, that disagreement is written down as its own contradiction record, and a credibility-weighted judge settles it afterward. You can see where the two sides clashed instead of getting a single conclusion handed down as fact.
3. A chain of custody you can break on camera. Every tool output is hash-chained, Merkle-rooted (rs_merkle over canonical JSON), and signed, and manifest_verify checks the whole thing offline. Change one byte in the audit log and verification fails and points at the record that moved. You check the integrity yourself instead of trusting us for it. We've framed it for FRE 902(14) self-authenticating evidence.
4. Verdicts that stay inside the evidence. Calling something "executed" takes at least two corroborating artifact classes, because Amcache on its own is catalog time, not run time. The verifier re-runs each cited tool and throws out any finding whose output hash has drifted. NO_EVIL only ever means "clean in what we examined," not "definitely safe." We'd rather hand back an honest INDETERMINATE than a confident wrong answer.
5. It drives the SANS SIFT VM. It boots the VM, finds its IP, and runs every forensic tool over SSH so disk images extract fully. With no VM around it falls back to the host's local tools, and you get the same offline-verifiable trail either way.
What it actually caught
We scored it against published answer keys instead of grading our own homework.
- Nitroba (network): 5 of 5 expected findings, 100% recall, reproducible offline with
scripts/score-recall.py docs/sample-run/nitroba --golden goldens/nitroba. - NIST hacking case (disk): we took disk-artifact recall from 1 to 5 of 14 by teaching it to read the SAM "Mr. Evil" account, USB and OpenSaveMRU activity, the shellbag trail to a
\\4.220.254\Tempstaging share, and hacking-tool files in the MFT. We published the recall we still miss rather than rounding it up, and kept the verdict scoped toSUSPICIOUS. - 22-host estate: it caught six machines running the same admin tool in the same second, a lateral-movement pattern you would never see one host at a time, and surfaced it as a lead for an analyst to confirm rather than an automated "response."
What was hard
Covering disk, memory, and network from one deliberately narrow typed surface, without ever adding the shell escape hatch that would have made the rest of it pointless. Keeping the copyleft and source-available engines (Hayabusa, tshark, pandoc) plus Volatility 3 and Velociraptor as subprocesses only, so the codebase stays Apache-2.0. And making "verify offline" literally true: a binary you compile fresh years from now, with the network unplugged, still checks the chain.
What we learned
The Tier-1 DFIR caveats are easy to get wrong. Amcache LastModified is not execution. ShimCache ordering changed in Windows 8.1. EVTX Logon Type 3 and Type 10 mean different things. Rather than hope the model remembers all of it, we pushed corroboration into the architecture. The bigger lesson was simpler: a verdict should never claim more coverage than the evidence supports, so we built for that from the start.
What's next for VERDICT
More disk parsers (LNK files, recycle bin, browser history) to close the NIST recall gap, deeper cross-host correlation for fleet cases, and post-verdict automation kept strictly outside the audit chain — never evidence, never a finding.
Built With
- anthropic
- claude-code
- claude-opus
- hayabusa
- model-context-protocol
- next.js
- node.js
- python
- react
- rust
- sans-sift
- sigstore
- the-sleuth-kit
- typescript
- velociraptor
- volatility-3
- wireshark
- yara

Log in or sign up for Devpost to join the conversation.