-
-

Landing Page
-

Media Lander
-
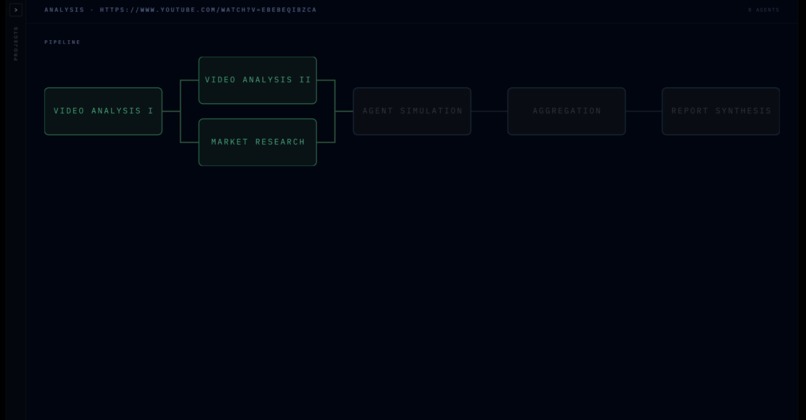
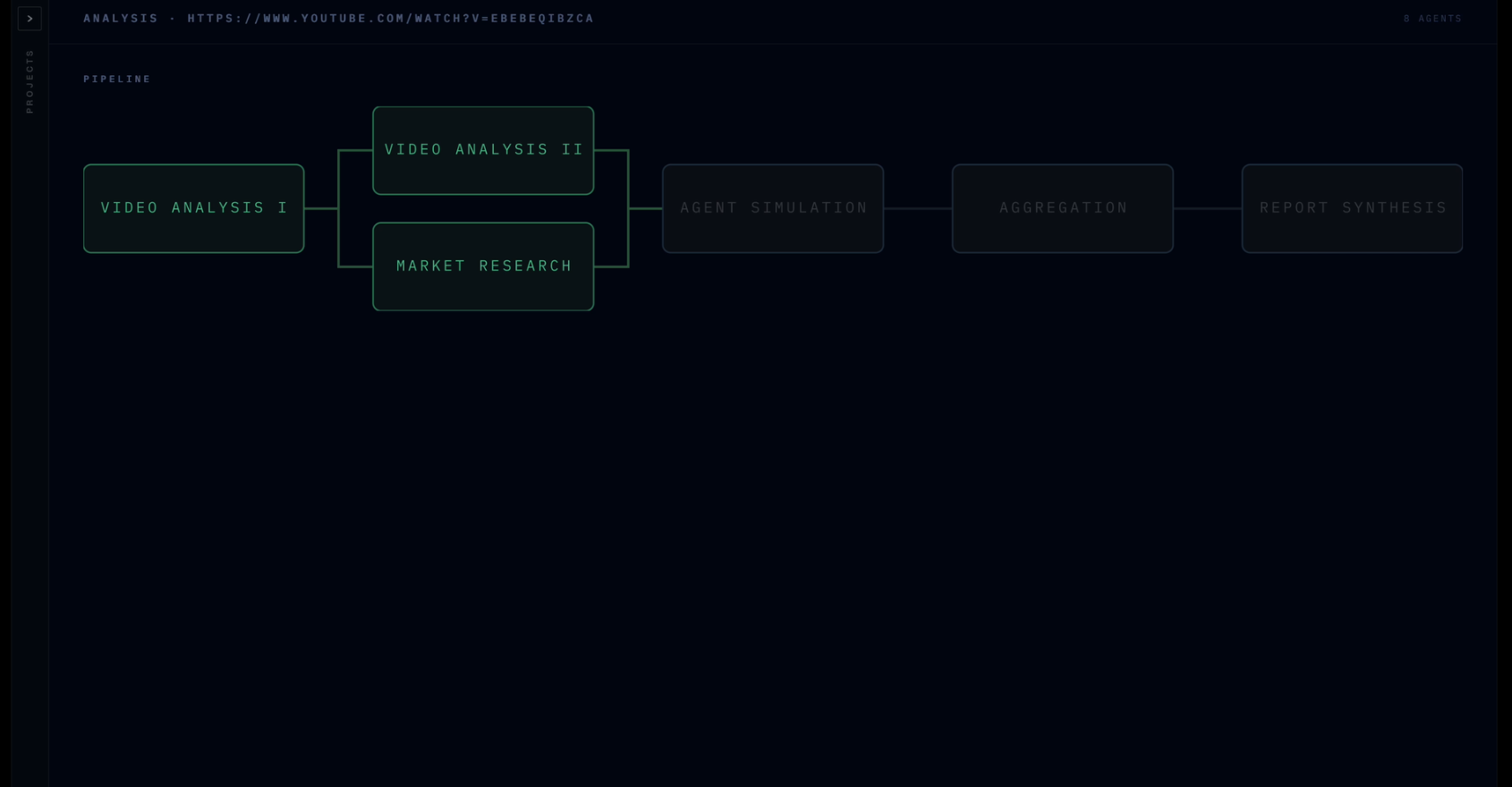
Live Progress Bar
-
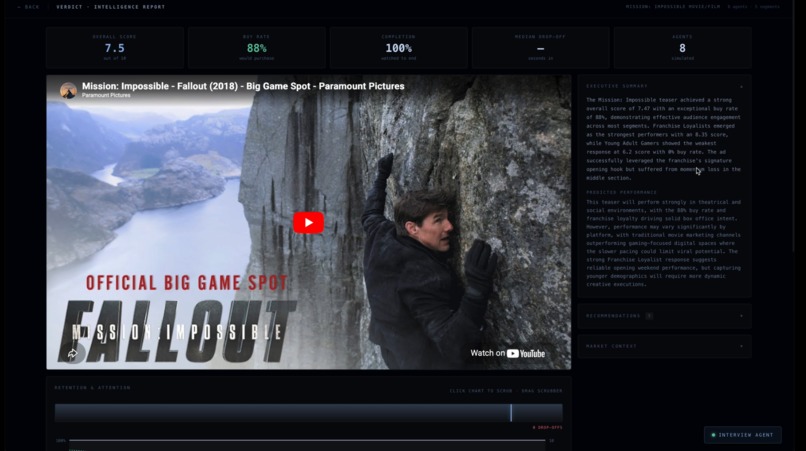
Analytics Timeline
-
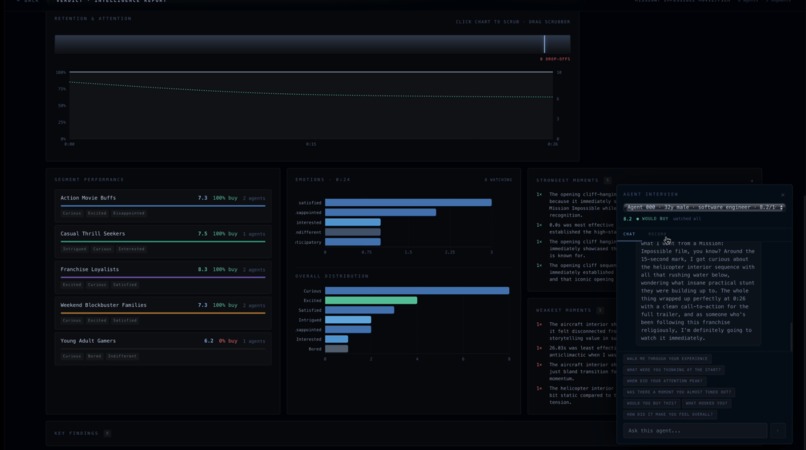
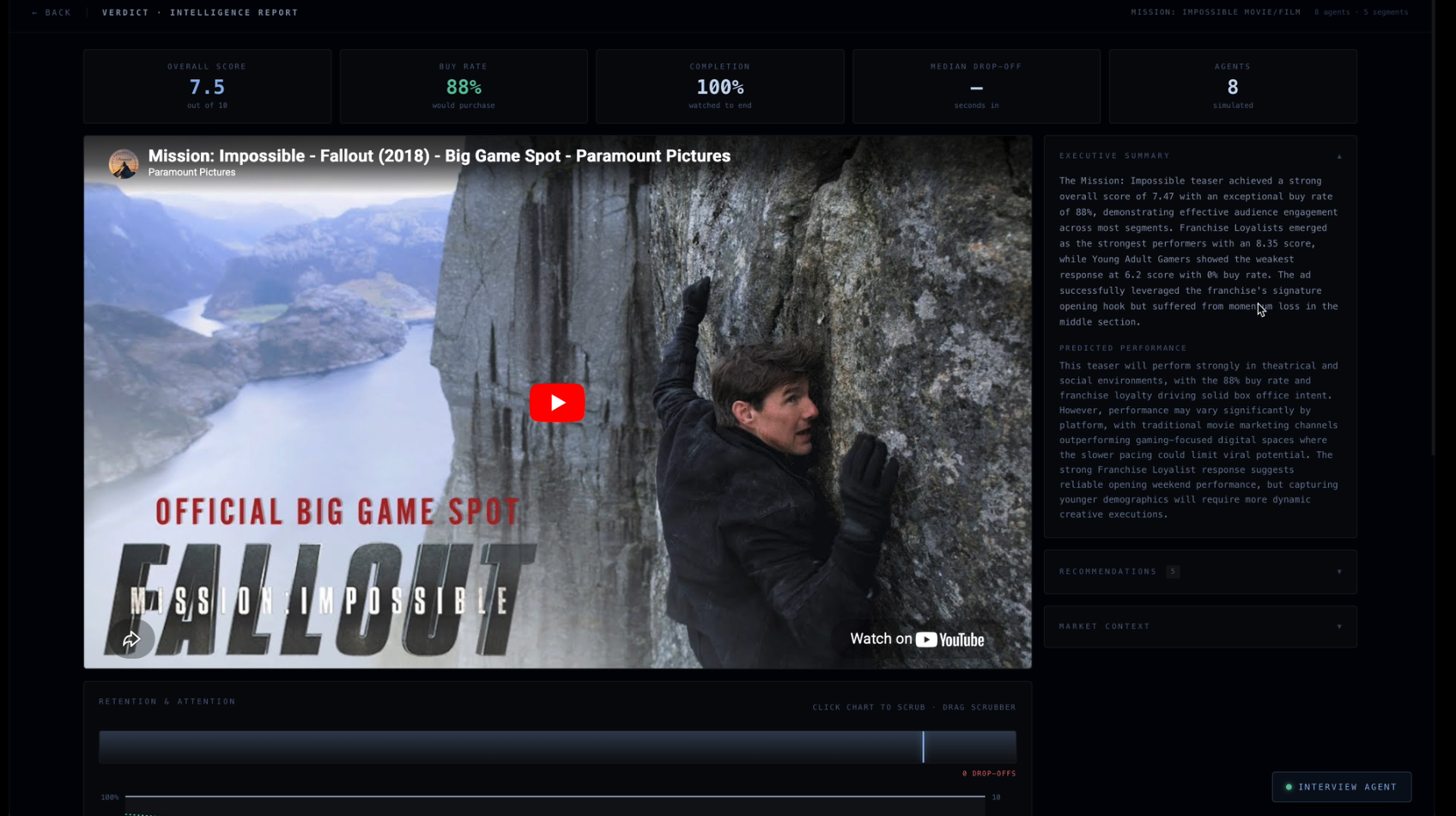
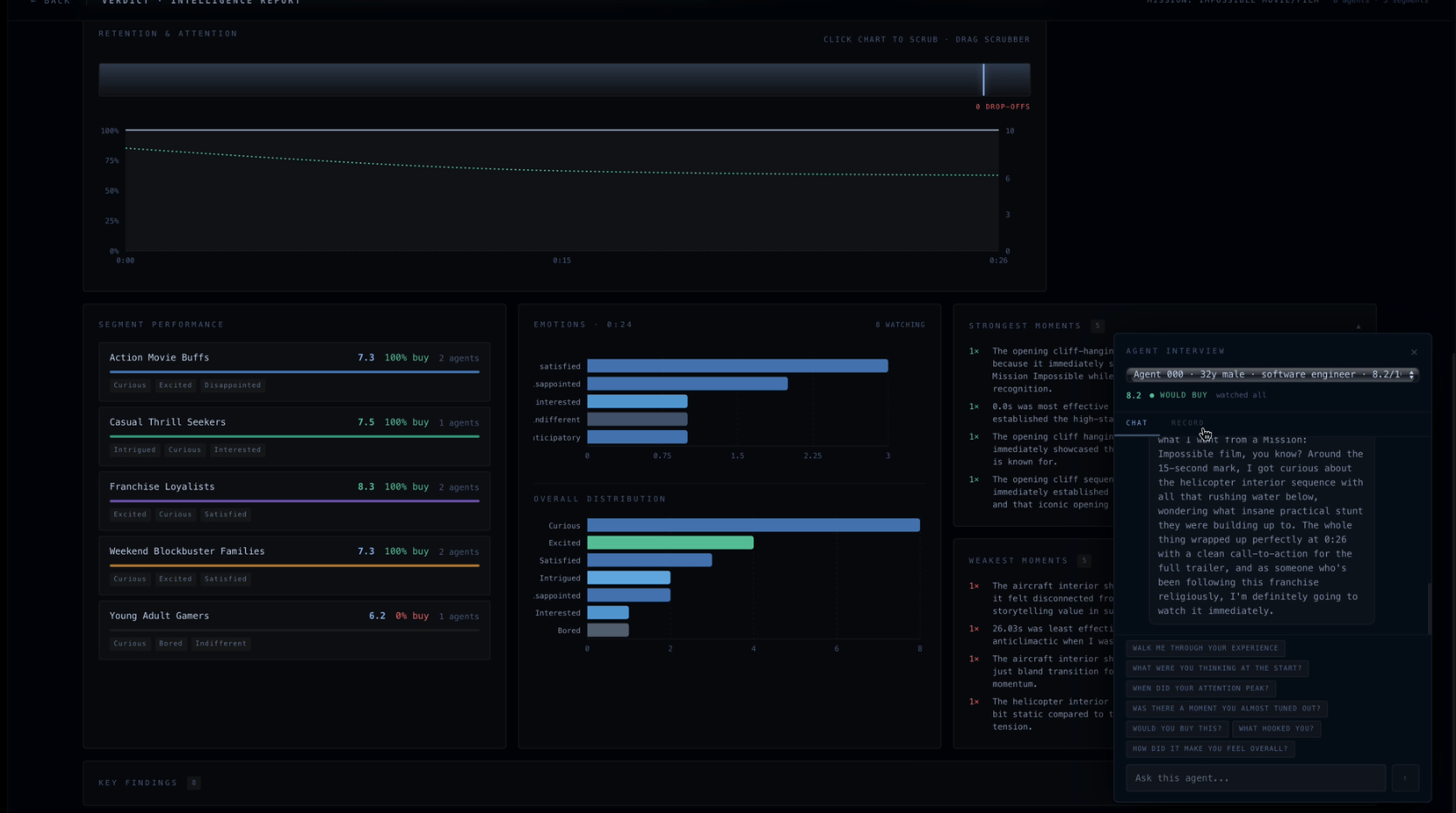
Analytics Screen (Emotions of Simulated Watches, Tips, etc..)
-
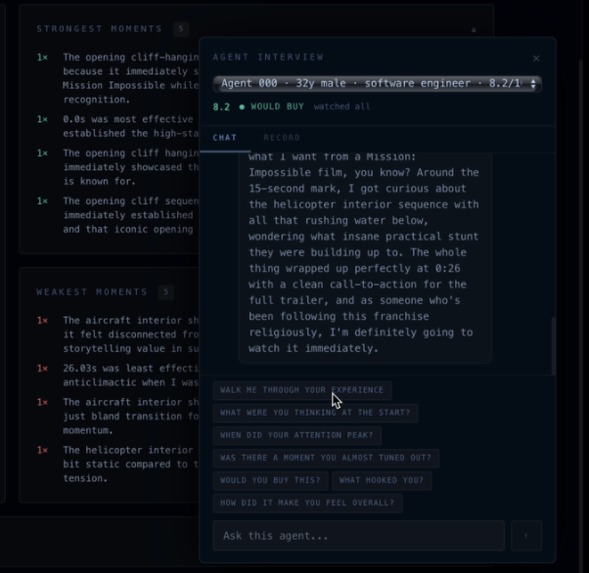
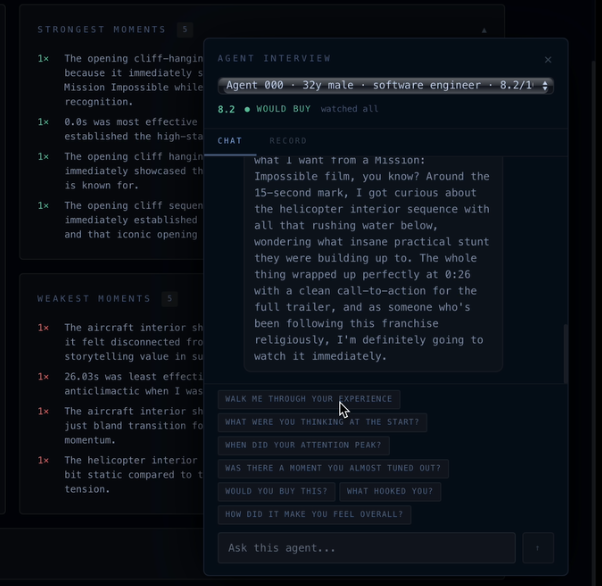
Interactive Simulated Persona


Inspiration
While making marketing content for a club, we unfortunately embarrassed ourselves on social media for very little views. We started wondering: what if we could create short-form content truly targeted to a desired audience? This is a question that is asked by large corporations, students giving presentations, entrepreneurs looking for their first contract, and many more. We hoped that the ability of language models to roleplay as different characters could enable market-like feedback for such content.
What it does
Verdict generates simulated insights on a short-form video based on a LLM-driven approximation of the target audience, providing key metrics such as retention rate and dropoff locations for fairly cheap. Verdict breaks an uploaded video into frames and a transcript, conducts market research to identify a target audience, and then feeds the content to up to 1,000 simulated users running in parallel for feedback on strengths and weaknesses. We can even interview any of the simulated users afterward about their experience, like a company might call back a surveyed respondent.
How we built it
Verdict extracts metadata from video content with clever prompting of Claude. This metadata guides a market research agent which evaluates the approximate breakdown of the target market. Verdict simulates entire consumer panels using Anthropic’s Claude API via Lava. Each persona watches your ad second-by-second, logging emotions, attention, and drop-off moments streamed live to a Next.js + Tailwind frontend backed by Django. The analytics dashboard syncs a draggable timeline scrubber across retention charts and a live emotion graph, with every simulated agent interrogable through a built-in Claude-powered chat with their full reaction log as context. Built end-to-end in VSCode and Zed, with Firebase handling authentication and a DigitalOcean server running the backend.
Challenges we ran into
We struggled with the tradeoff between accuracy, cost and speed. On the one hand, batched requests and large models produced qualitatively better results; on the other hand, parallelizing requests with weaker language models resulted in less heterogeneity. One major challenge was ensuring differentiated and representative personas in parallelized simulated agents while still being able to call them later in the program to ask questions about what they watched.
Accomplishments that we're proud of
Our ability to generate synthetic humans at massive scale is a novel idea. While large-scale world simulations exist, few focus specifically on determining how a video influences a population. We’re also proud of the UI design, especially the lander animation that lands and then takes off again as you drag up the analytics screen.
What we learned
We learned that AI is extremely effective at developing synthetic datasets, and there is huge potential for determining influence across populations, and even predicting large-scale decisions across a synthetic audience.
What's next for Verdict
Verdict is far from done. Our next step is closed-loop ad generation: critique a draft, provide constructive feedback, generate a new version, and repeat in a circular process. This would allow us to create highly optimized, hyper-targeted ads. As of now we have created a story board generated from the critique, and are using Veo 3 to create a synthetic ad. We truly believe that Verdict has potential to be a real company in the future and we plan to continue work into the summer!
Built With
- anthropic
- lava
- python


Log in or sign up for Devpost to join the conversation.