
Inspiration
We've all learned not to fully trust AI. It's confident, fluent — and it makes things up. That's a minor annoyance in a chatbot. It's genuinely dangerous when it's the tool meant to tell you what your customers think.
A wave of "synthetic user" research tools now promises to simulate your customers so you can interview them. The problem is they invent. Ask one why users churned and you'll get a plausible, well-written answer that no real customer ever gave you — and making product decisions on hallucinated feedback is worse than having no research at all.
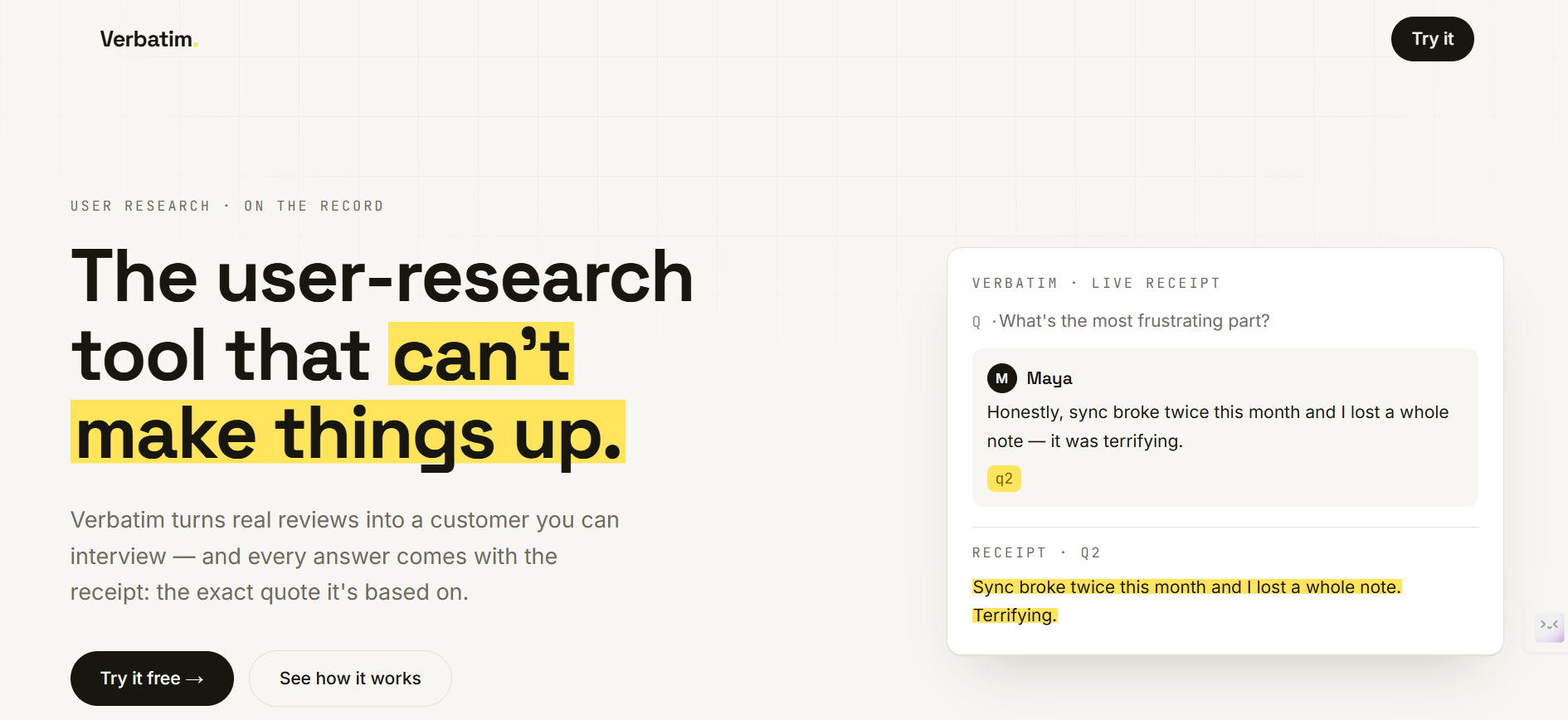
I wanted the opposite: a research tool that physically cannot fabricate. Everything it tells you has to trace back to something a real customer actually said, and you should be able to check every word.
What it does
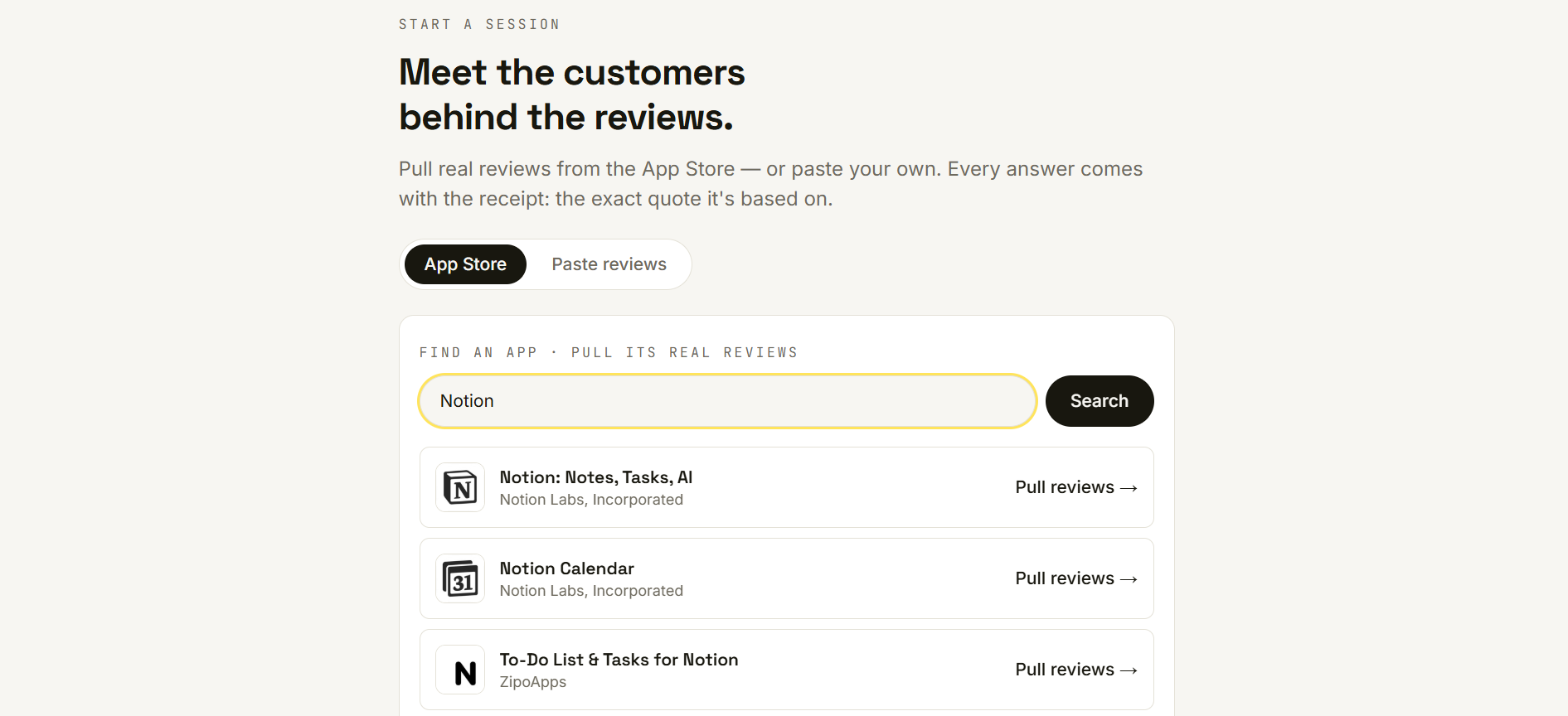
Verbatim turns real customer voice into a customer you can interview. You name a product, it pulls up to 100 real App Store reviews (or you paste your own), and from there you can interview the customers behind them and read a grounded strategic analysis — with every answer traceable to a real quote.
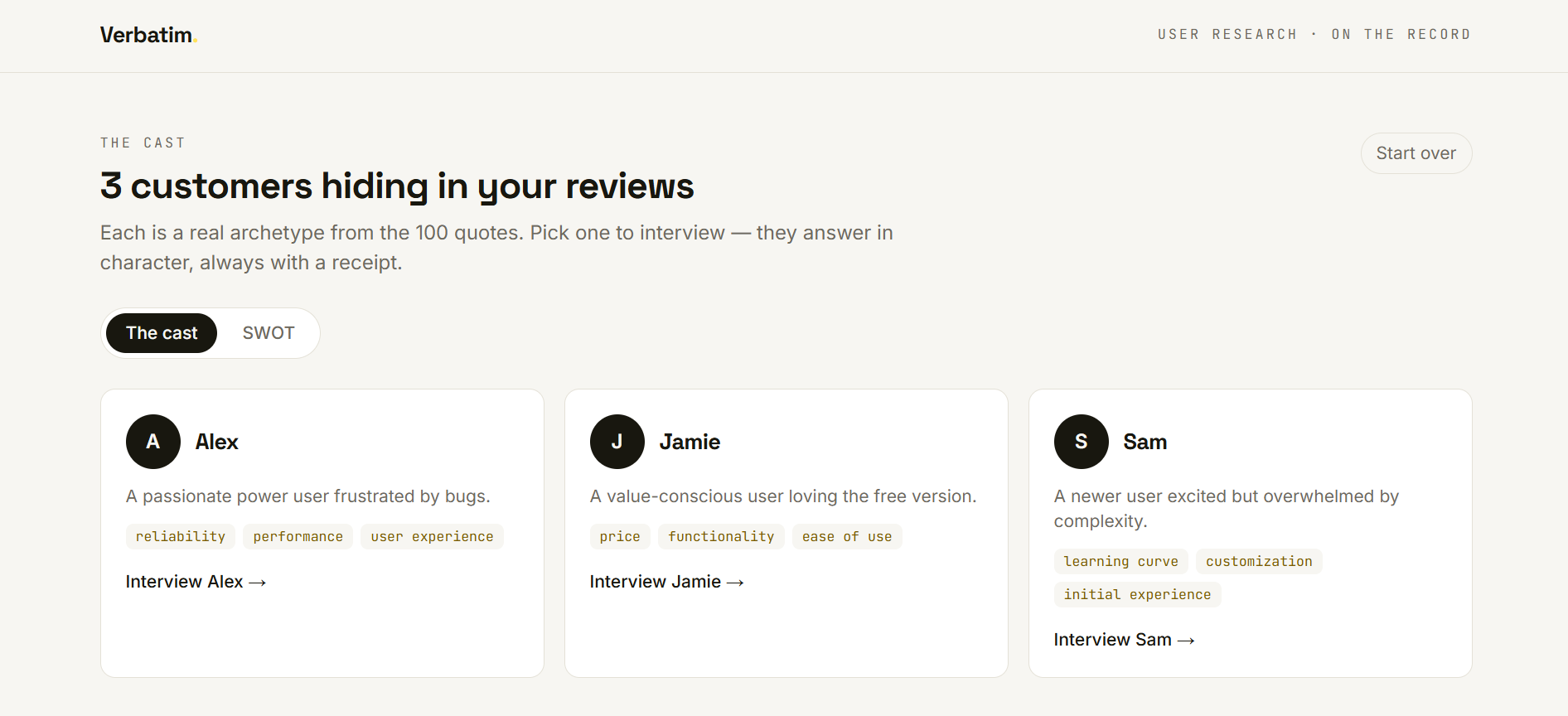
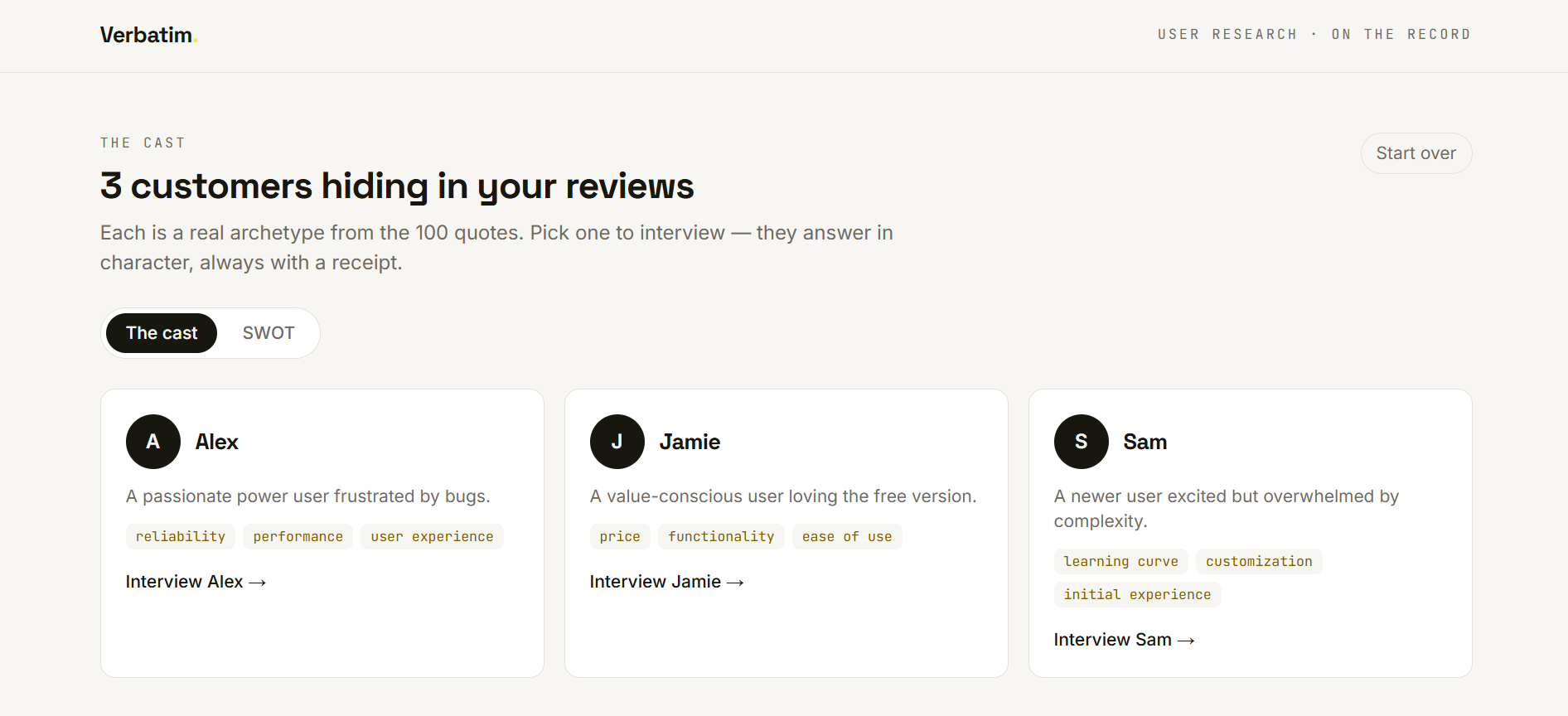
Meet the cast. Verbatim surfaces the 2–3 distinct customer archetypes hiding in those reviews — coherent individuals with their own priorities, not one averaged-out summary.
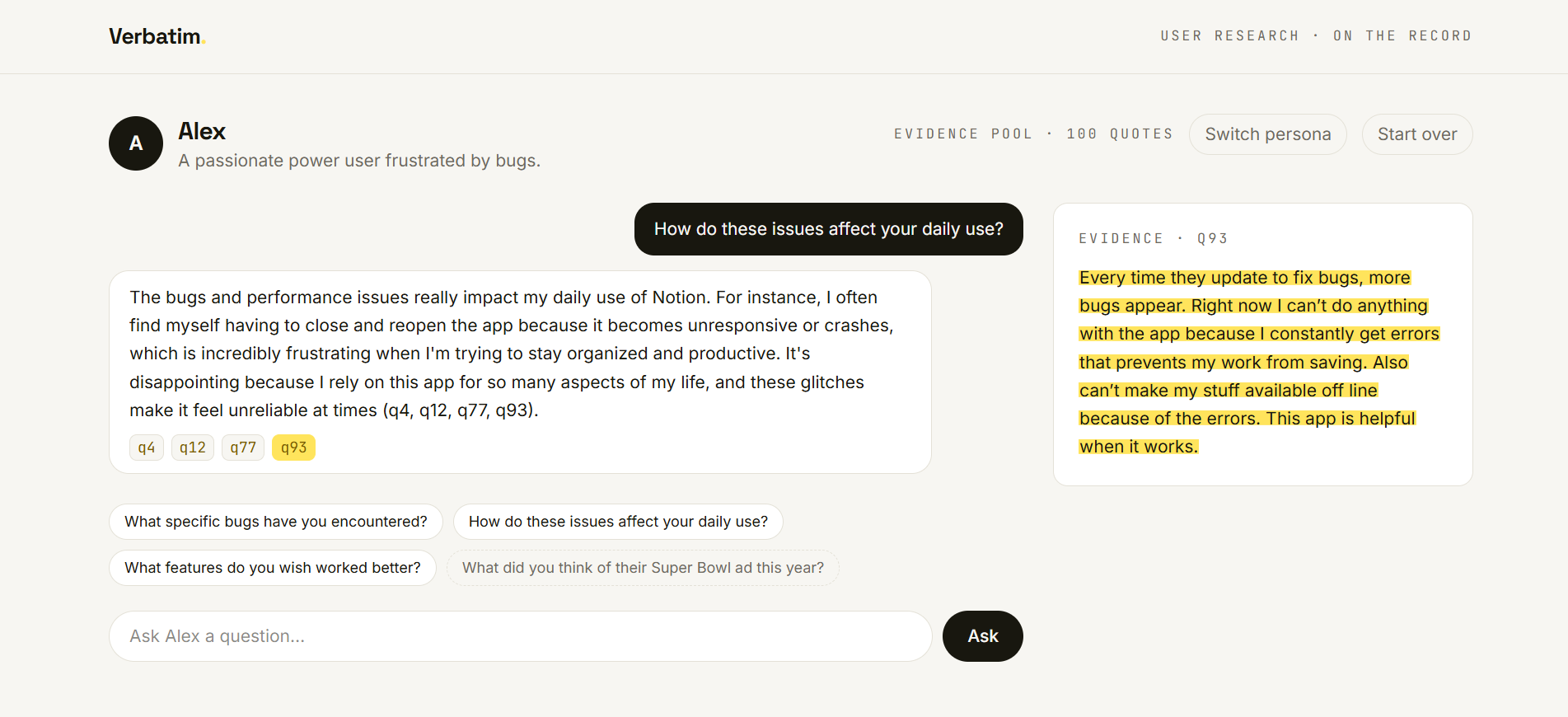
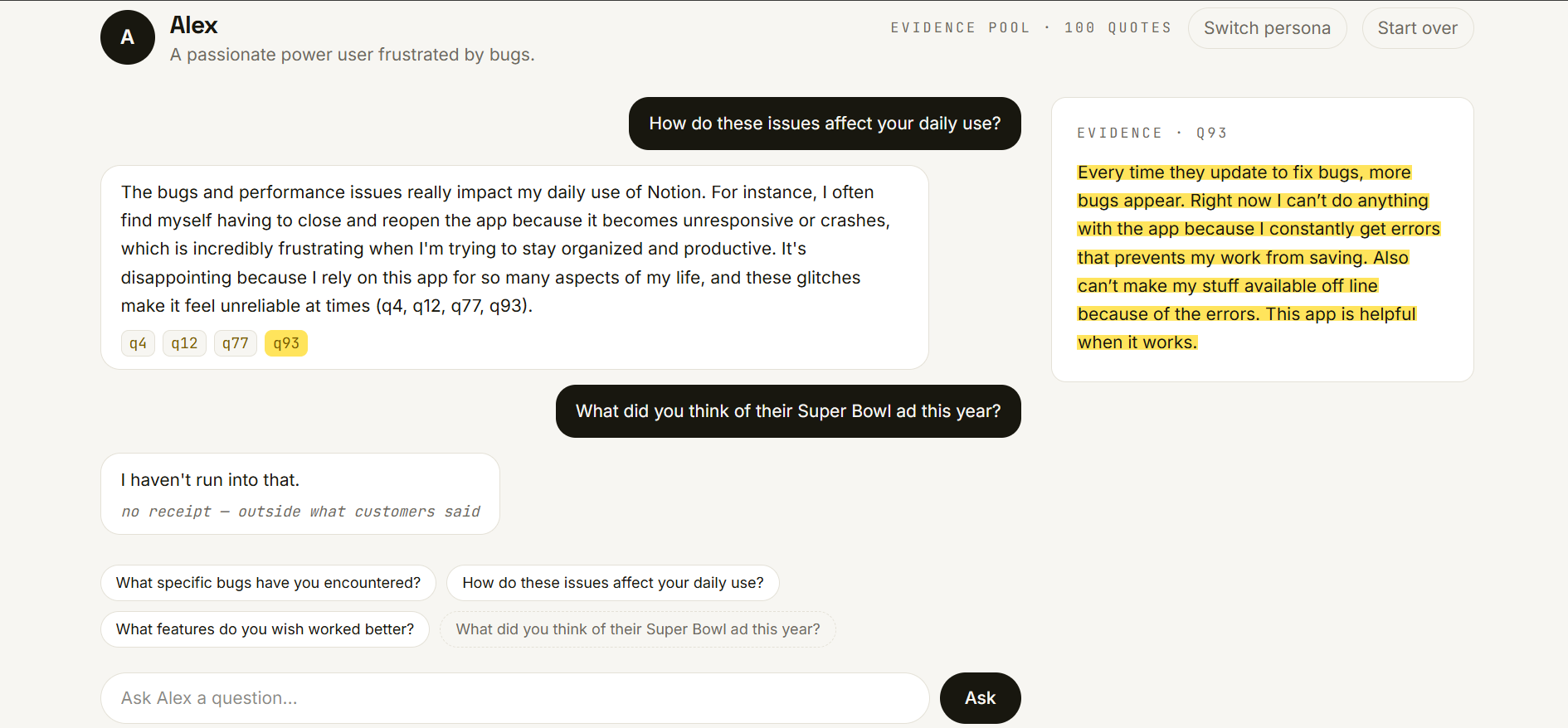
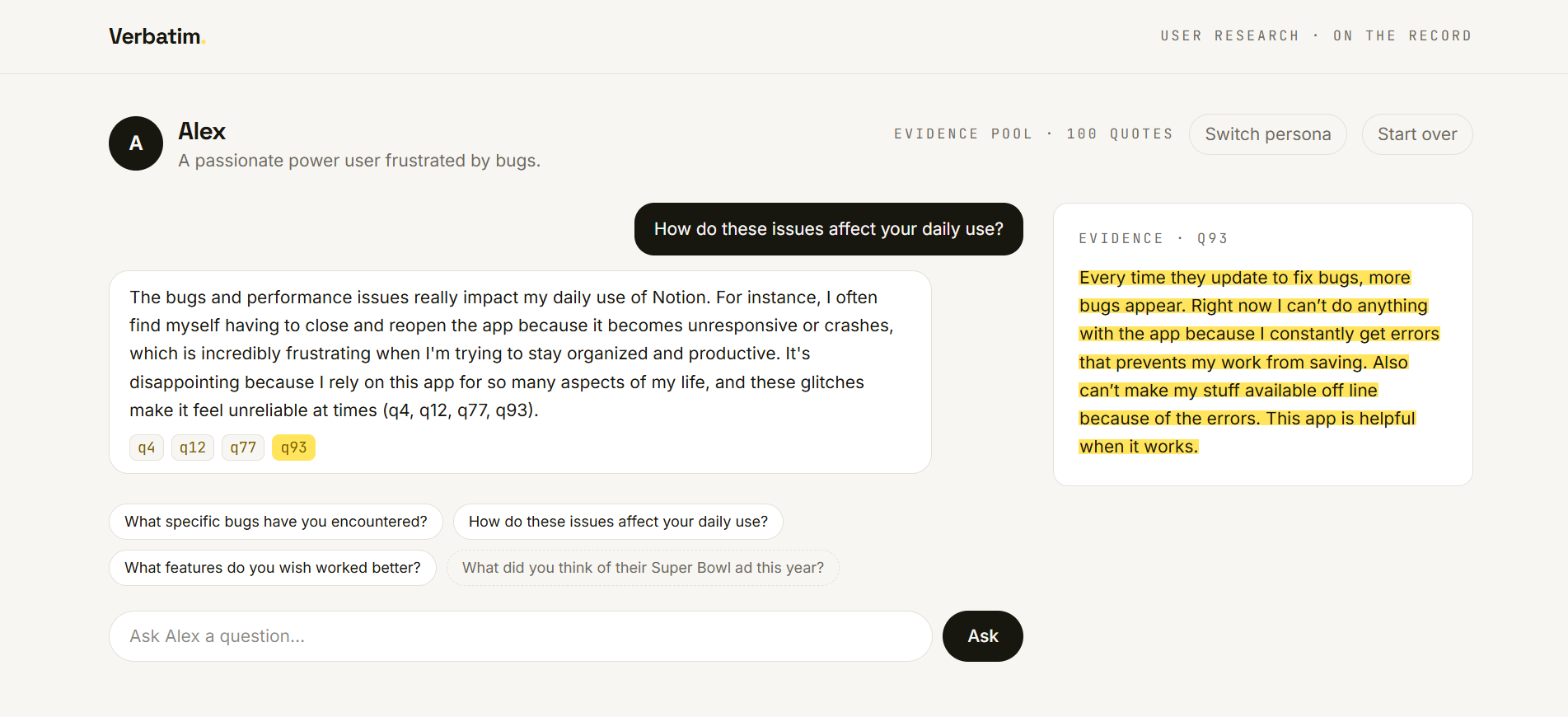
Interview them. Ask anything. Each persona answers in character, and every claim carries a receipt — click it and the exact source review lights up in amber. Color means proof.
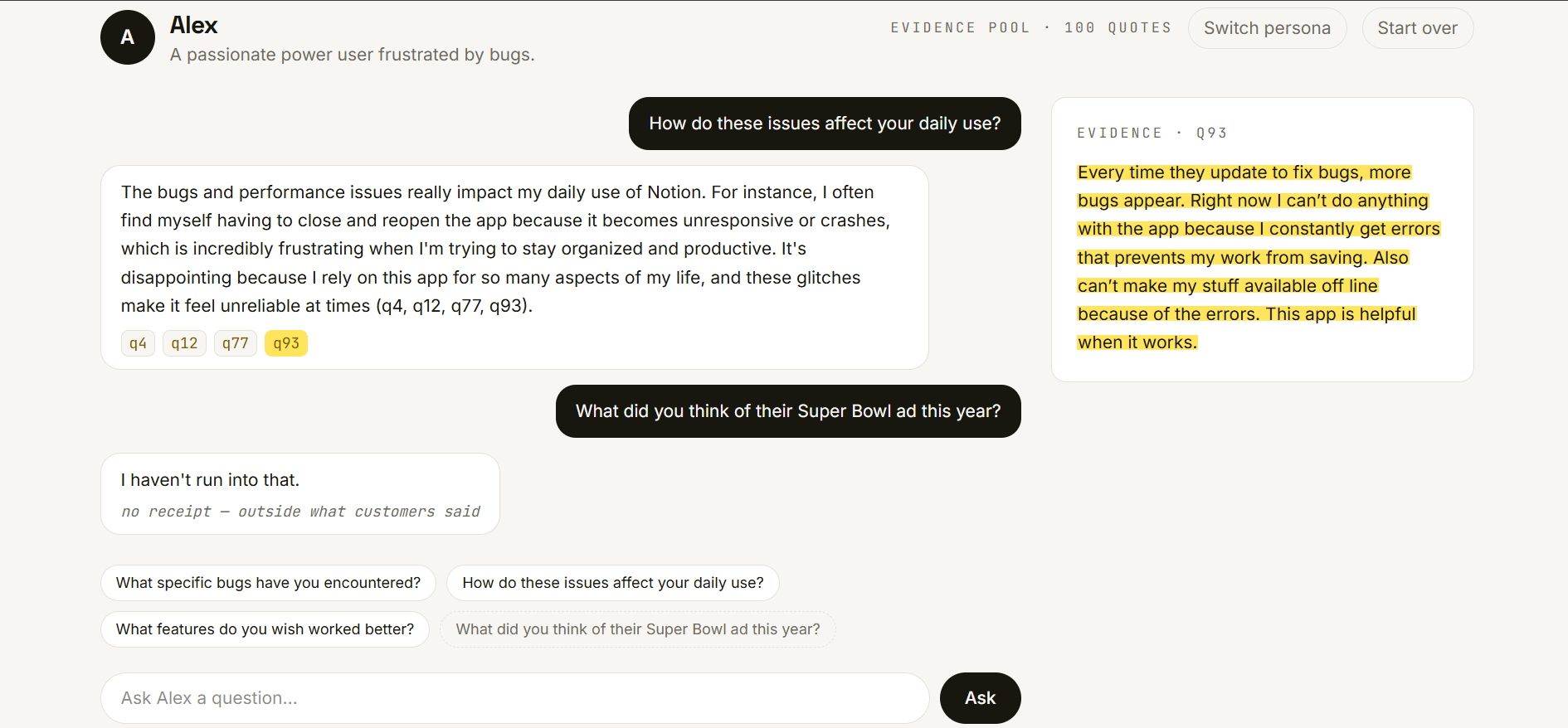
Watch it refuse. Ask about something the reviews never mention and it won't invent an answer — it tells you, honestly, that there's no receipt for that. The honesty is the product.
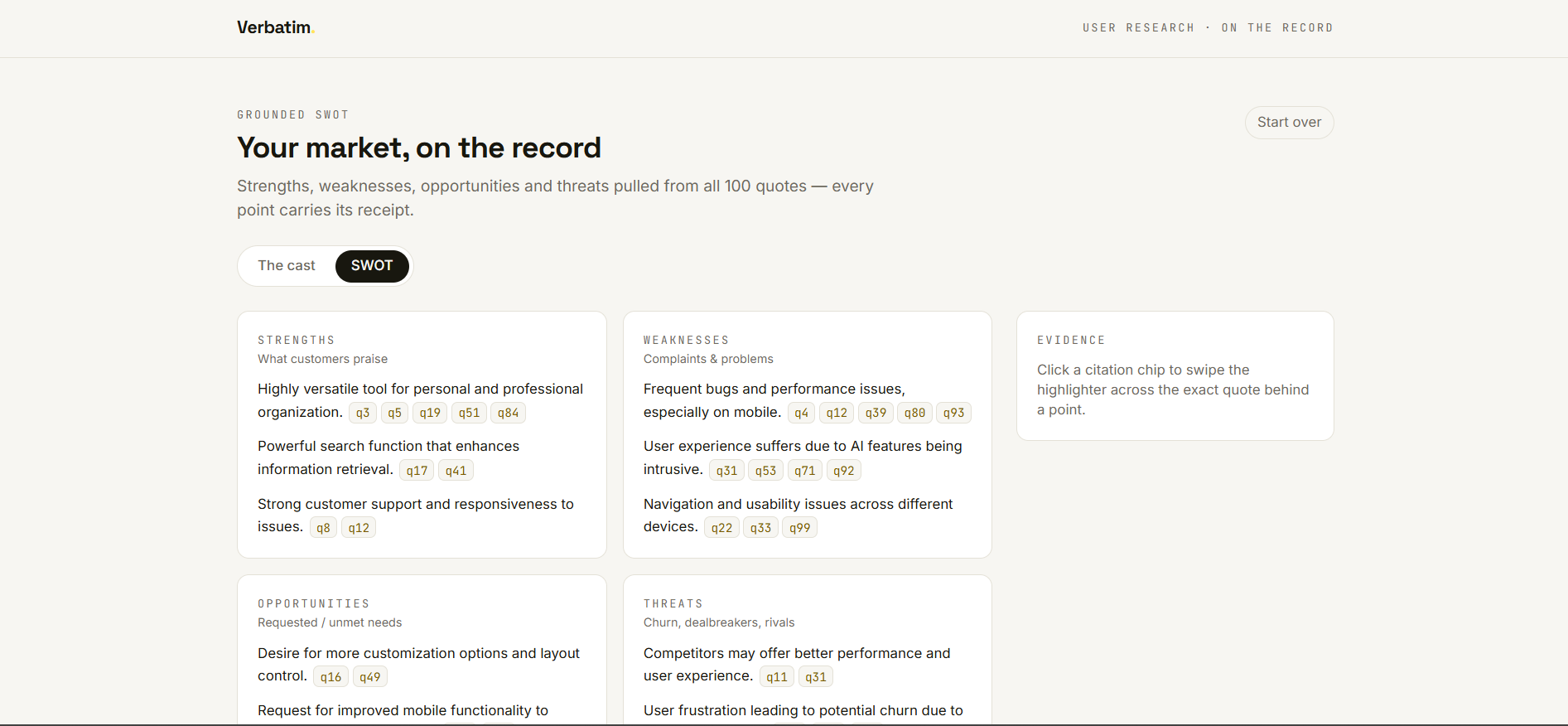
Read the grounded SWOT. From the same reviews, Verbatim builds a strategic SWOT where each point is synthesized from patterns across many customers — and every one still cites the real quotes behind it.
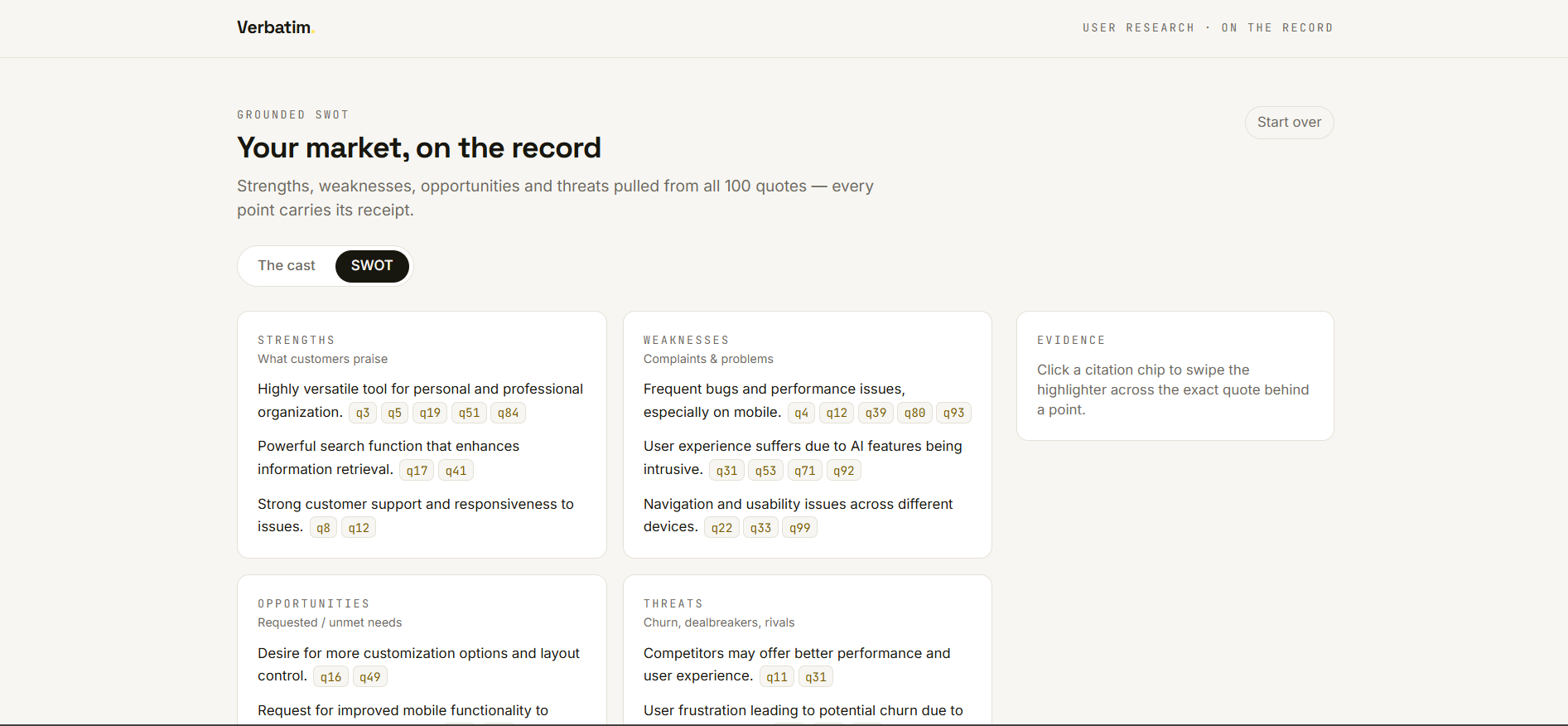
It's for product managers, designers, researchers, and founders — anyone who makes decisions from user feedback and needs to trust what they're hearing.
How I built it
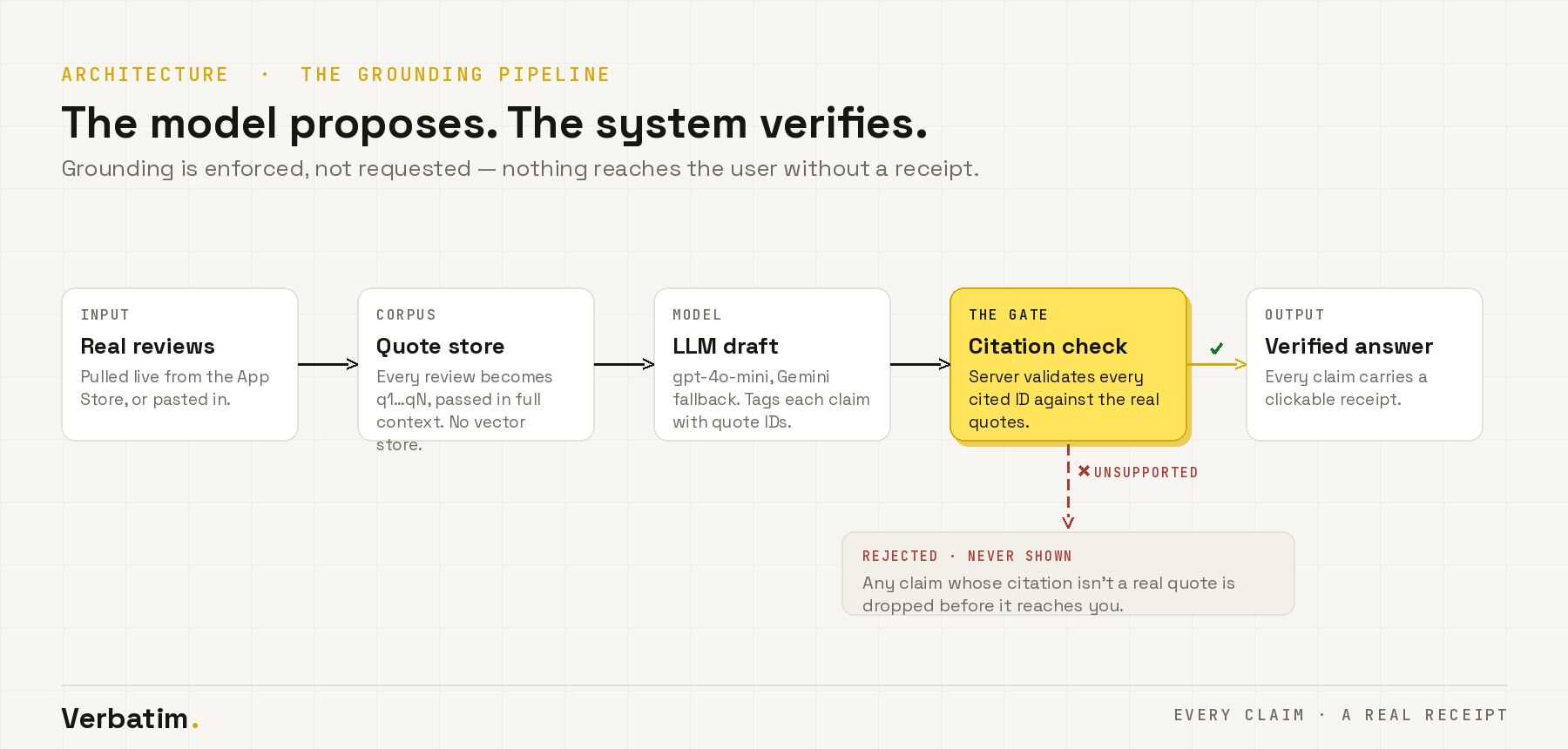
The whole product rests on one principle: grounding is enforced, not requested. The model proposes; the system verifies; nothing reaches the user without a receipt.
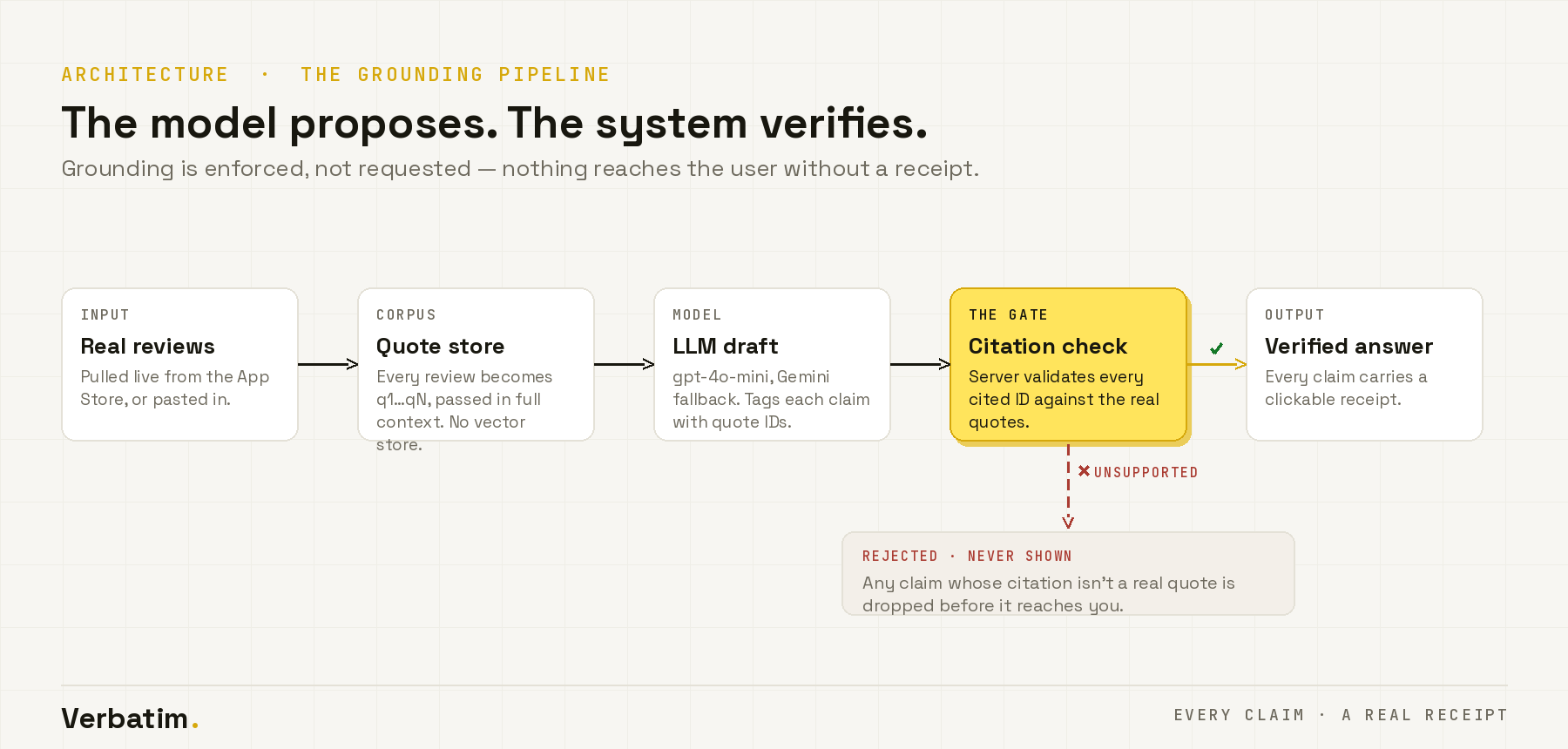
- Frontend: Next.js (App Router) on Vercel, Tailwind, and Framer Motion — built on one "evidence on the record" design system (ink on warm paper, a monospace for citations, amber used only to mark cited evidence).
- Engine: OpenAI
gpt-4o-minias the primary model with an automatic Gemini fallback, both driven by the same strict grounding contract. - The enforcement layer: the model must cite a quote ID for every claim, and the server then validates every citation against the real quotes, dropping anything it can't back up before it ever renders. A fabricated citation is structurally impossible, not just discouraged. No vector store — all quotes pass in context.
- Inputs: a public App Store reviews pipeline (search → fetch real reviews) plus manual paste, all feeding the identical grounding engine.
- Analytics: Novus (Pendo), tracking the full engagement funnel.
- Built solo, using Claude as strategist/architect and Claude Code as the implementer, with a single
CLAUDE.mdas the shared spec between them.
Challenges I ran into
- Proving it before building it. Before any UI, I ran a throwaway grounding "spike" to confirm a model would stay honest, cite real quotes, and refuse questions it had no data for. It passed — which is what greenlit the whole project.
- Prompting wasn't enough. Asking the model to "only use real quotes" still let the occasional invented citation slip through. The server-side validation layer is what turned a promise into a guarantee.
- Personas that sounded like summaries. Early versions dumped every complaint into one paragraph. The fix was a character-lens model: each persona has a distinct archetype and leads with its own concerns, but answers from the full set of reviews — so two personas asked the same question lead with different priorities and cite different real quotes.
- SWOT that was transcription, not synthesis. The first version produced one point per review — useless at scale. I forced it to cluster many reviews into a handful of themes, each backed by multiple representative receipts.
- Reliability. Gemini's free tier threw intermittent 503s mid-demo, so I made OpenAI primary with Gemini as automatic fallback — the interview never dies.
What I learned
- You can't ask a model to be trustworthy — you have to enforce it. The validation layer, not the prompt, is what makes the guarantee real.
- The most powerful moment in the product is when it says "I don't know." An AI that refuses to make things up is genuinely novel right now, and that honest refusal turned out to be the entire pitch.
- Narrow and polished beats broad and half-built — one trustworthy loop, executed cleanly, is a stronger product than a pile of features.
What's next
- More real sources — Google Play, support tickets, and CSV import, all feeding the same grounding engine.
- Scaling the corpus — representative sampling across ratings so it stays grounded and fast on thousands of reviews.
- Shareable grounded reports — export a persona interview or a SWOT where every claim is still clickable back to its receipt.
Across all of it, the rule never changes: nothing reaches you without a receipt.
Built With
- claude-code
- framer-motion
- gemini
- github
- next.js
- node.js
- novus
- openai
- pendo
- react
- tailwindcss
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.