Inspiration
Modern dating apps have become visual catalogs where connections rarely go deeper than a high-resolution photo. We’ve optimized for "the swipe" but lost "the soul," leading to a digital landscape defined by surface-level interactions and high burnout.
What it does
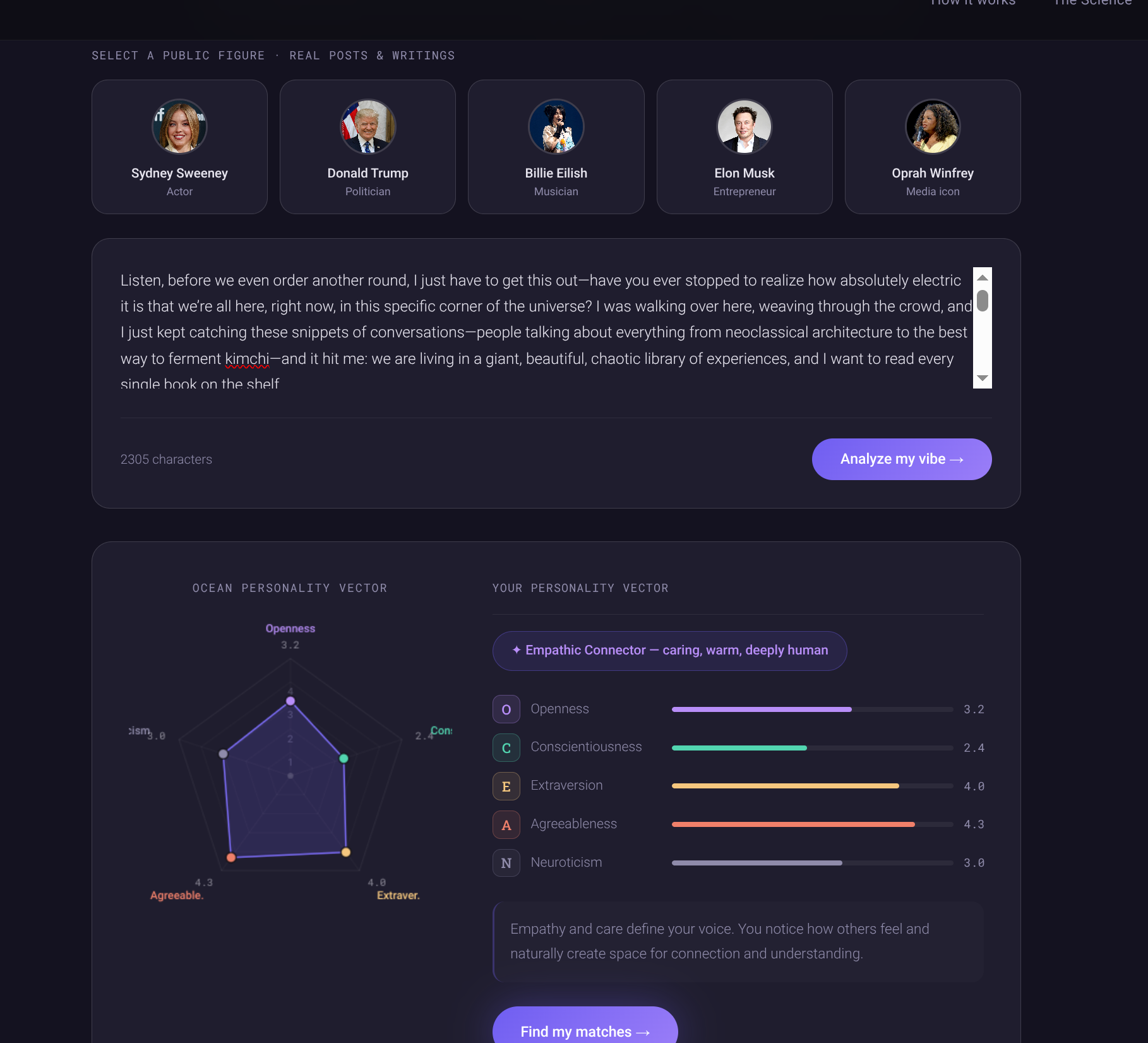
VectorVibe is a personality-first connection platform that replaces the photo-first gallery with a Natural Language Processing (NLP) engine. Instead of scrolling through images, users provide snippets of their own writing, journal entries, social posts, or even a quick rant. Our system instantly maps these inputs into a high-dimensional OCEAN personality vector.
How we built it
System Architecture: RAG-Enhanced Personality Inference Pipeline This system implements a multi-staged pipeline designed to quantify personality traits from unstructured text, such as social media activity and long-form blog posts. The architecture combines Retrieval-Augmented Generation (RAG) principles with Natural Language Inference (NLI) to move beyond simple keyword matching toward deep semantic understanding.
Neural Document Processing and Segmentation The pipeline begins by ingestive diverse text sources, which are subjected to a sliding-window chunking strategy. This ensures that the local semantic context remains intact while adhering to the token constraints of the transformer-based encoders.
Semantic Filtering via Bi-Encoder RAG To isolate trait-relevant evidence, the system utilizes a Bi-Encoder architecture powered by the intfloat/e5-base-v2 model. The personality inventory is structured into five primary indices, each mapped to 10 specific diagnostic questions.
Text chunks and these diagnostic questions are projected into a high-dimensional latent space. A similarity search is then performed to retrieve the most semantically relevant text segments for each question, effectively filtering out noise and non-descriptive content.
- NLI-Based Behavioral Inference Once relevant chunks are retrieved, the system performs zero-shot classification using a Cross-Encoder NLI model (MoritzLaurer/DeBERTa-v3-large-mnli-fever-anli-ling-wanli).
In this framework, the retrieved text chunk serves as the Premise, and the diagnostic question serves as the Hypothesis. The model computes the probability of entailment, providing a high-fidelity signal of whether the text actively manifests the specific personality characteristic described in the question.
Challenges we ran into
Optimizing the retrieval hyperparameters, specifically the similarity thresholds required to isolate contextually relevant text segments, presented a significant technical challenge. To ensure the highest degree of inference accuracy, we conducted an extensive comparative analysis across various transformer-based architectures, benchmarking several model configurations to identify the optimal framework for aligning unstructured prose with our diagnostic personality indices.
Accomplishments that we're proud of
We aren't just building another app; we are moving the foundation of online connection from the surface to the mind. VectorVibe allows you to meet a person’s thoughts before you ever see their face, fostering relationships built on stable, scientific compatibility.
What we learned
Built With
- fastapi
- gcp
- html5
- huggingface
- javascript
- transformers

Log in or sign up for Devpost to join the conversation.