-
-
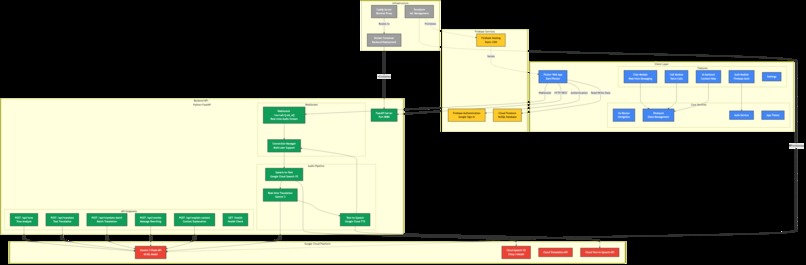
System Overview
-
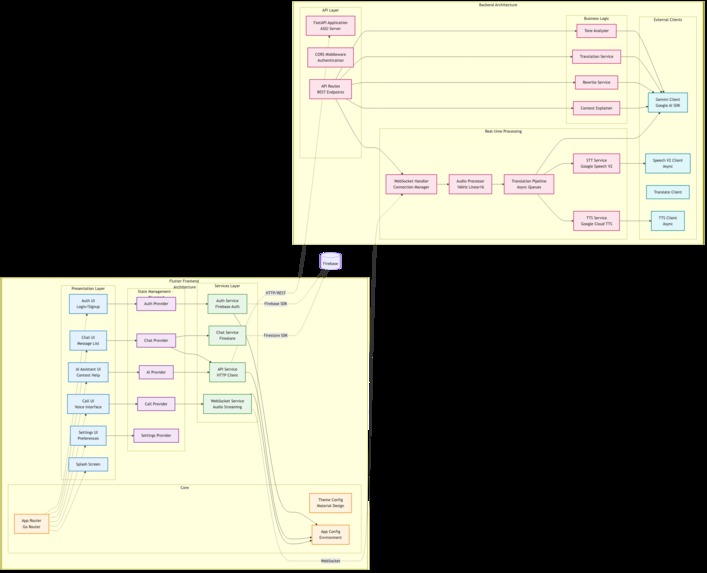
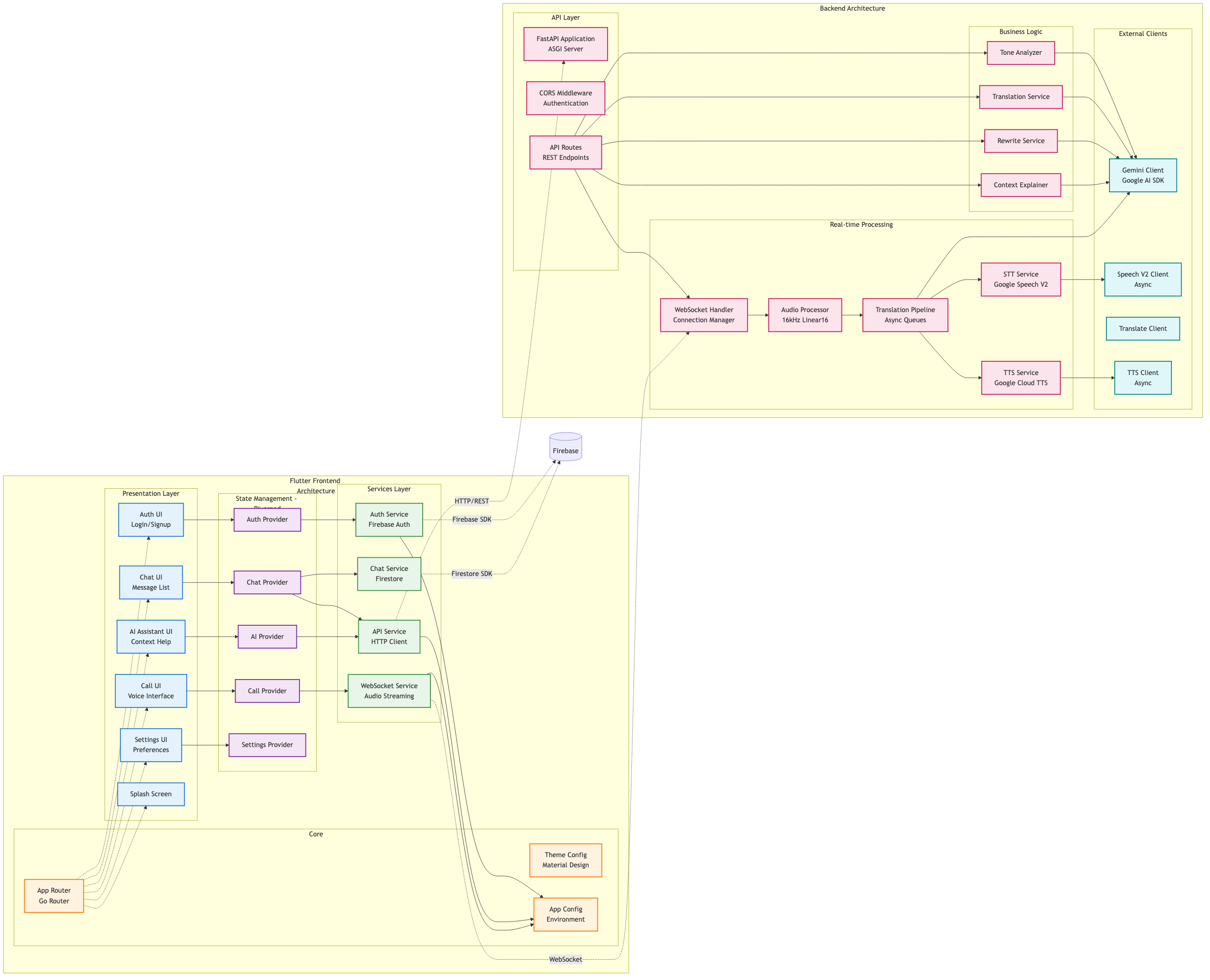
Component Architecture
-

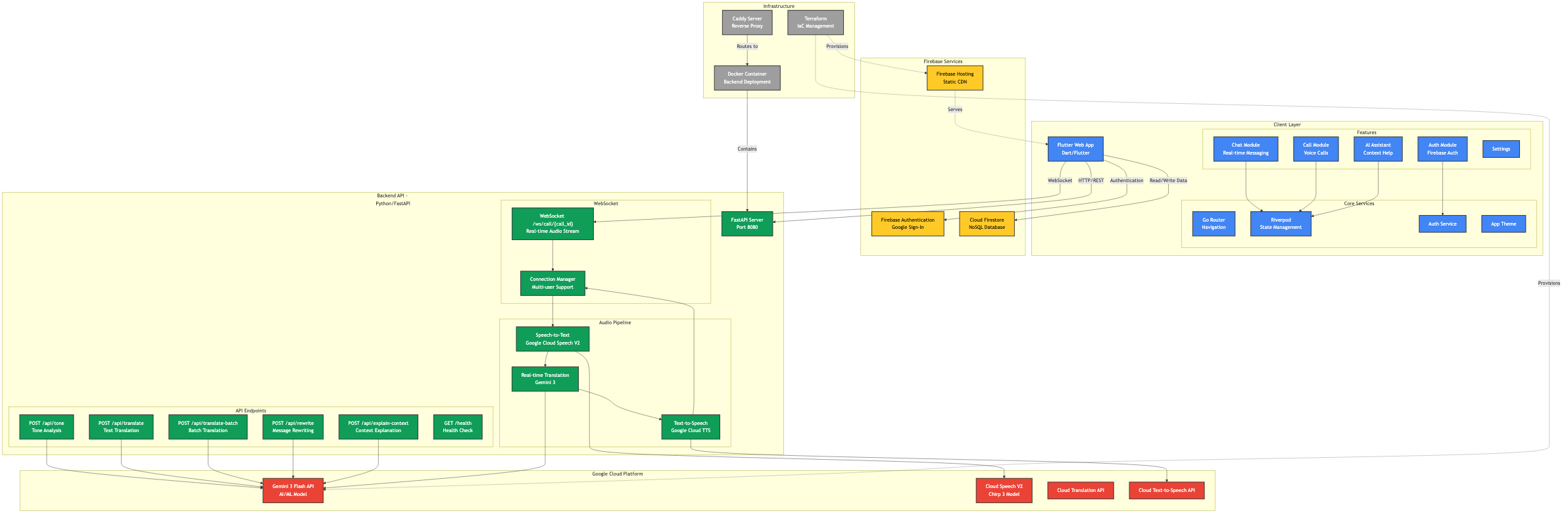
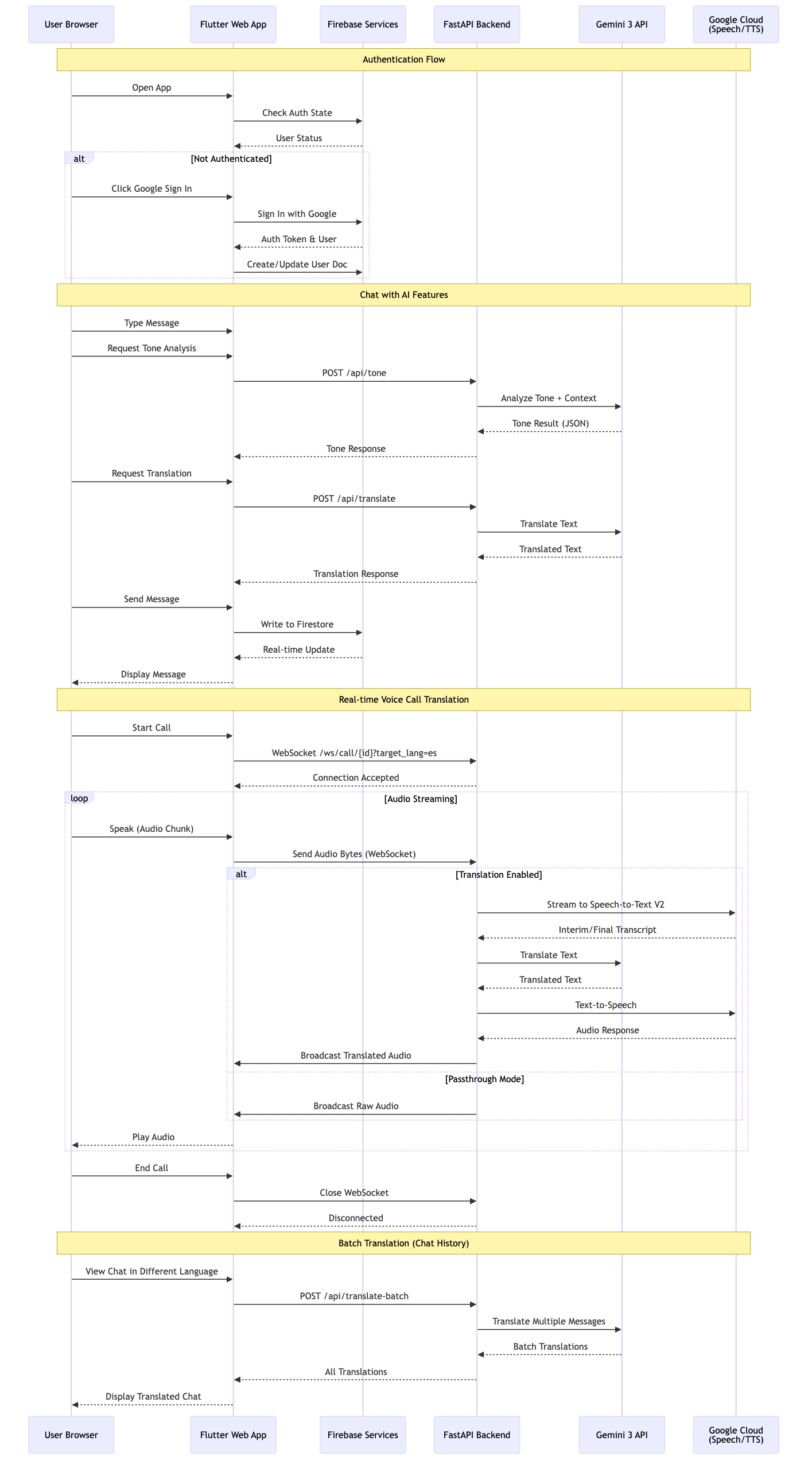
Data Flow
-
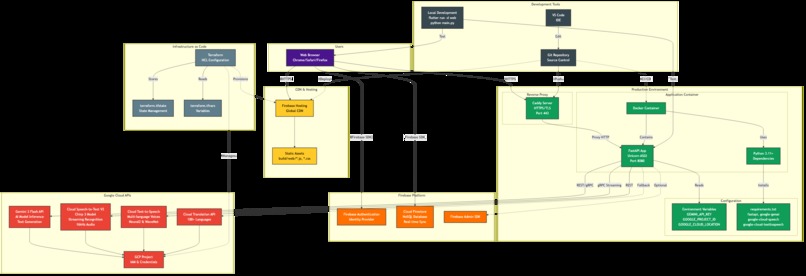
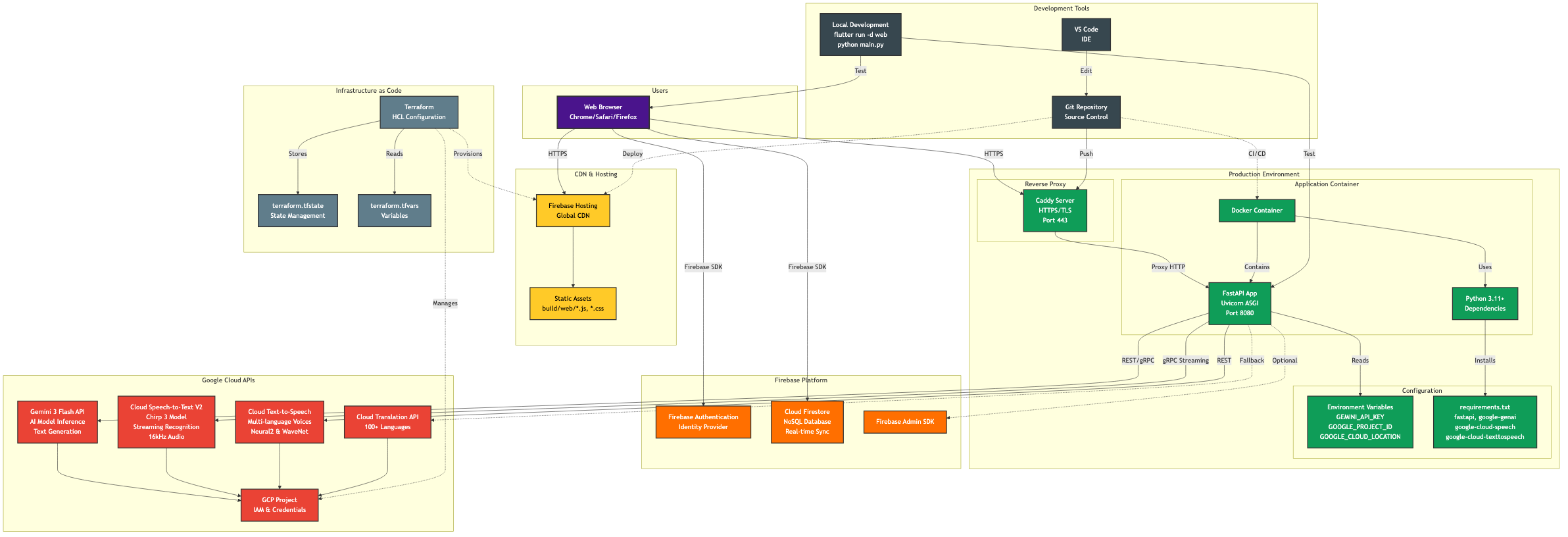
Deployment Infrastructure
Inspiration
In our increasingly globalized world, collaboration often breaks down because of language barriers and lost context. We have all been in calls where polite phrasing masks urgent deadlines or complex vocabulary alienates team members. We wanted to build a bridge that translates not just words but intent. We realized that true understanding requires more than just a dictionary; it requires a system that remembers your history and simplifies complexity.
What it does
Vayu is a real-time communication copilot powered by Gemini 3. In chat, it analyzes conversation history to detect tone and clarify context. This allows users to rewrite messages for clarity before sending. In voice calls, Vayu acts as an invisible interpreter. It listens to incoming audio containing complex jargon or foreign languages and translates it into the listener's native language in real time while preserving the flow of natural conversation.
How we built it
We integrated the Gemini 3 Multimodal API to handle both text analysis and real-time audio streams. We utilized Gemini’s context window to maintain a memory of previous messages. This ensures the AI does not hallucinate when referencing past projects.
Challenges we ran into
The core challenge was routing live audio calls through our custom backend without relying on any external APIs. We had to architect a robust pipeline that handles parallel processing for Speech-to-Text (STT), Translation, and Text-to-Speech (TTS). Managing these three distinct processes simultaneously required precise synchronization to ensure the output audio remained intelligible.
Accomplishments that we're proud of
We are proud of building a fully functional audio pipeline from scratch. Achieving the parallel execution of transcription and translation without external calling SDKs was a significant technical hurdle. We successfully demonstrated that complex inputs can be simplified instantly for the listener.
What we learned
We learned that latency is the enemy of natural conversation. We discovered how to optimize prompt engineering to handle specific personas and maintain context over long conversations. We also gained deep insight into handling raw binary audio data and the complexities of real-time stream processing.
What's next for Vayu
We plan to optimize our backend to reduce the processing time further. We also aim to integrate video analysis so Vayu can interpret non-verbal cues alongside audio and text.
Built With
- fastapi
- firebase
- flutter
- gemini
- google-cloud
- google-web-speech-api
- python
- terraform

Log in or sign up for Devpost to join the conversation.