-
-
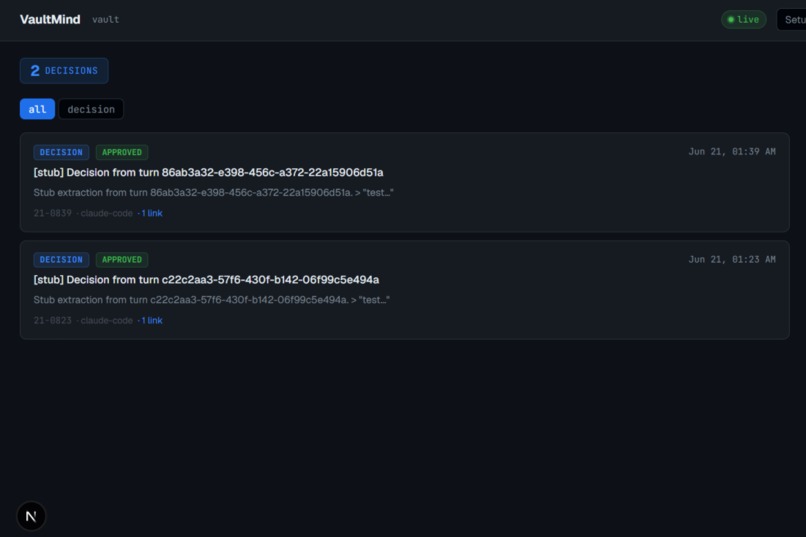
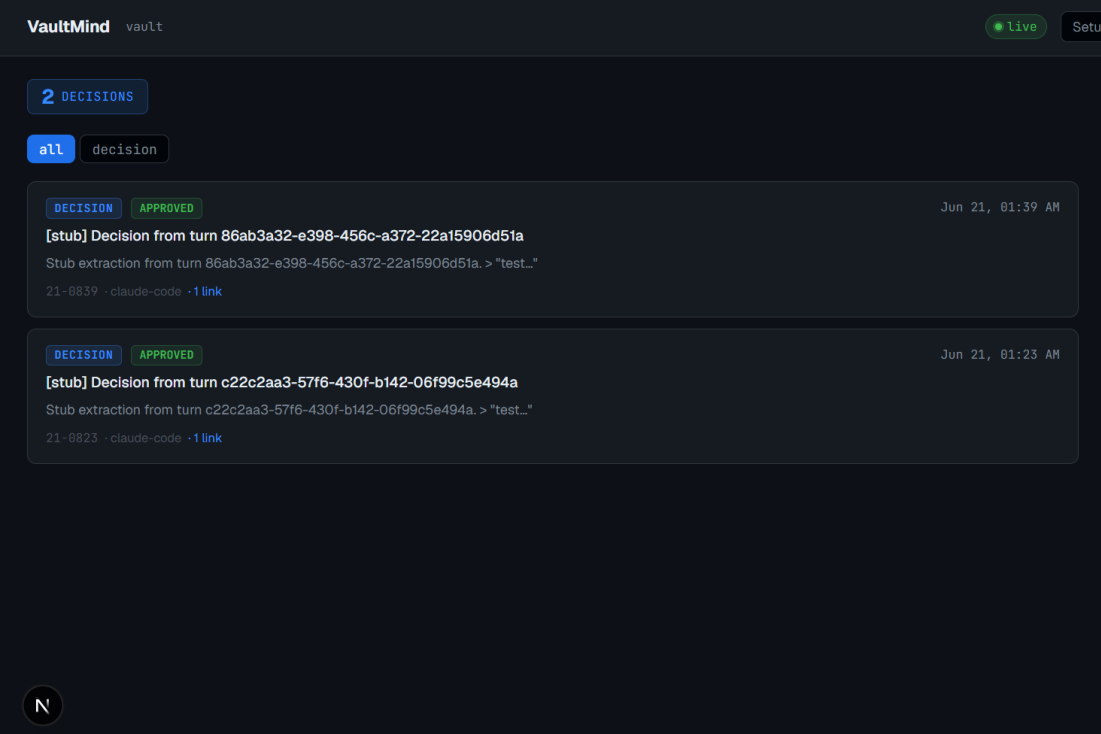
Home Page
-
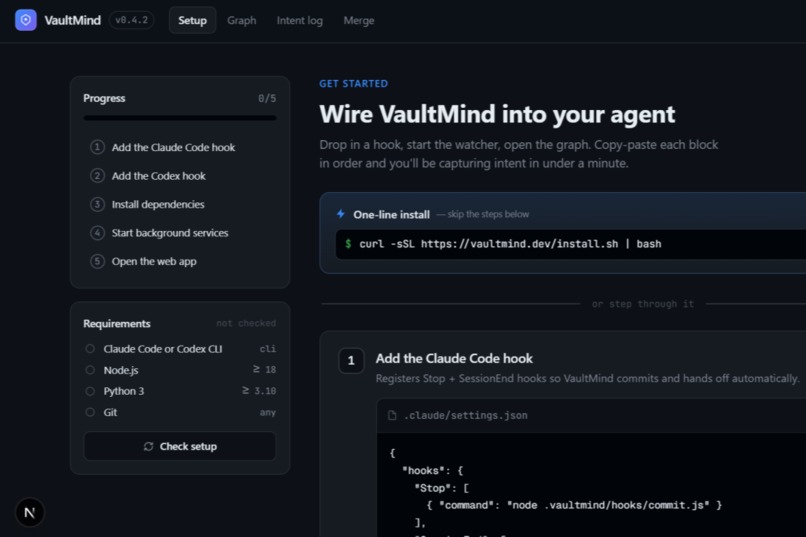
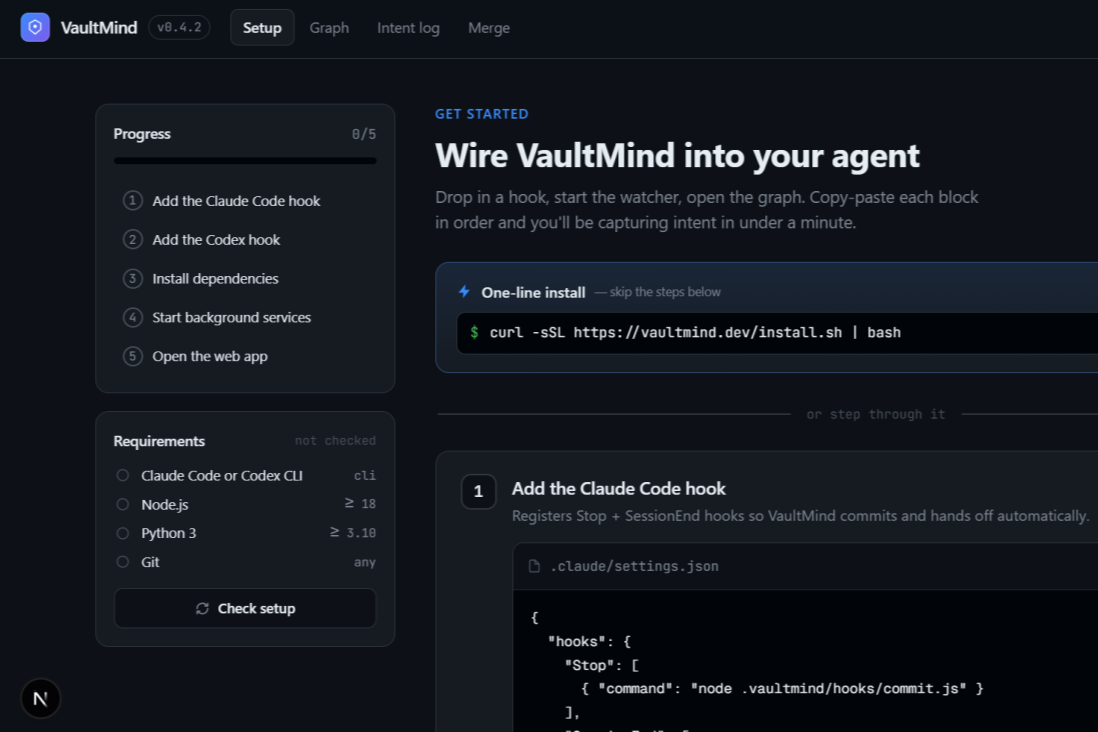
Set Up Page
-
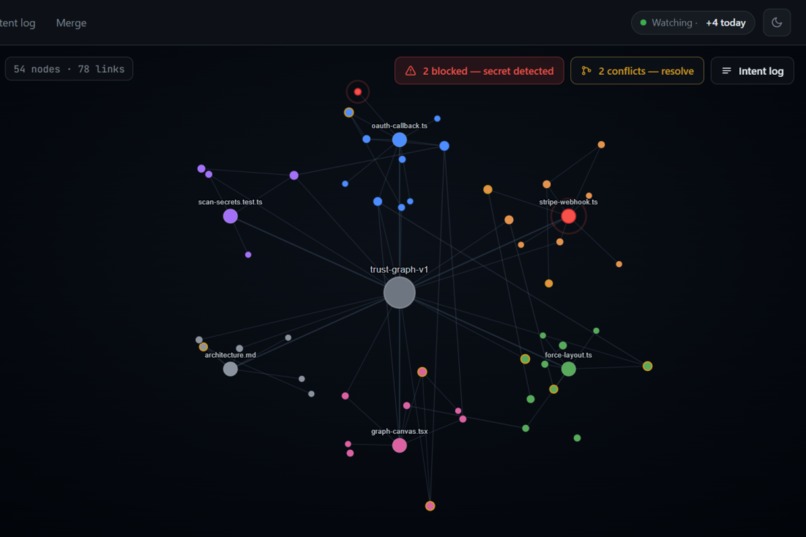
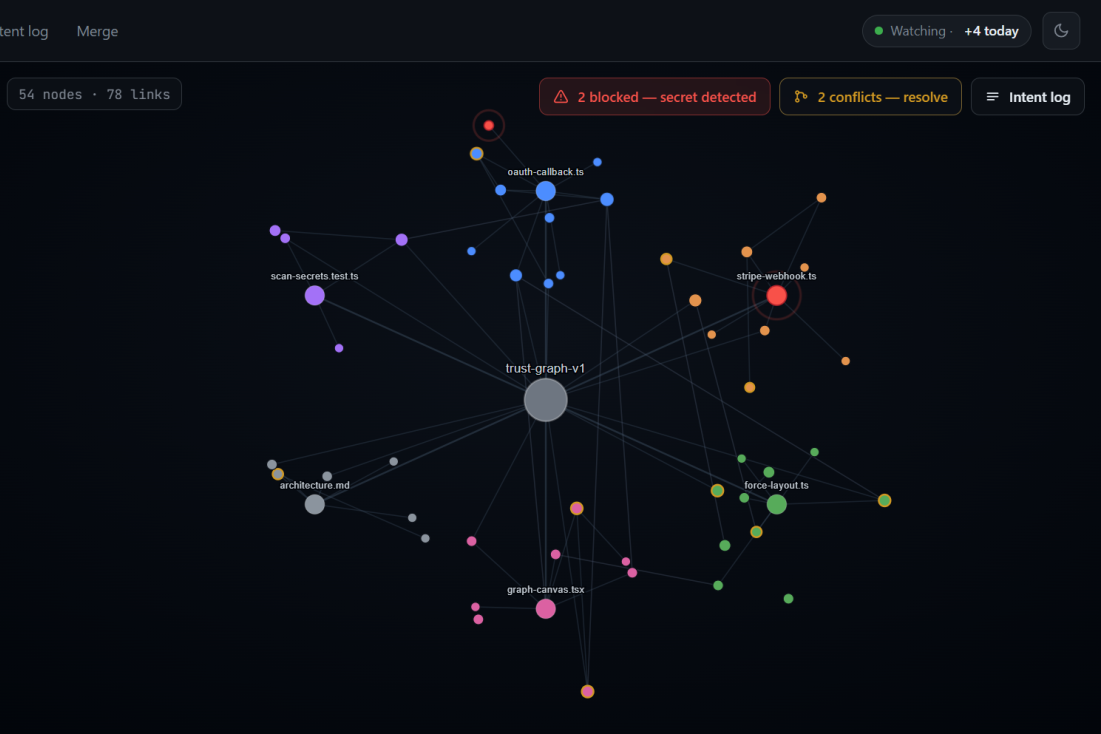
Graph
-
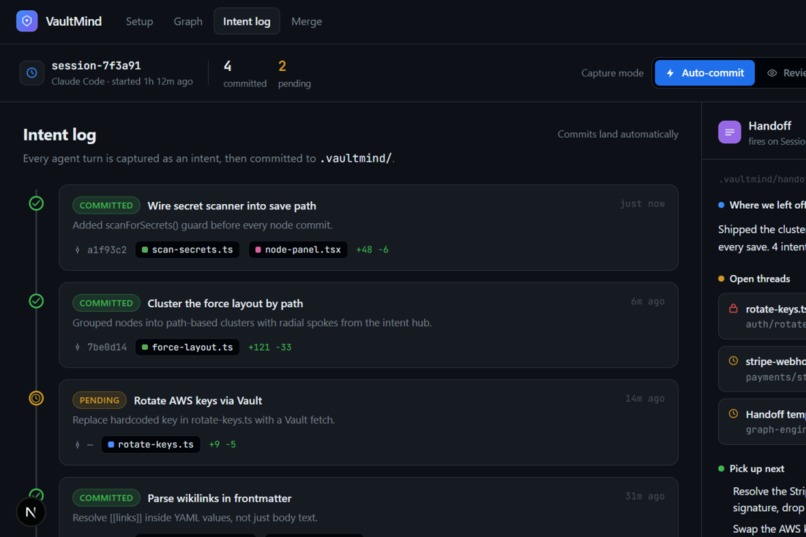
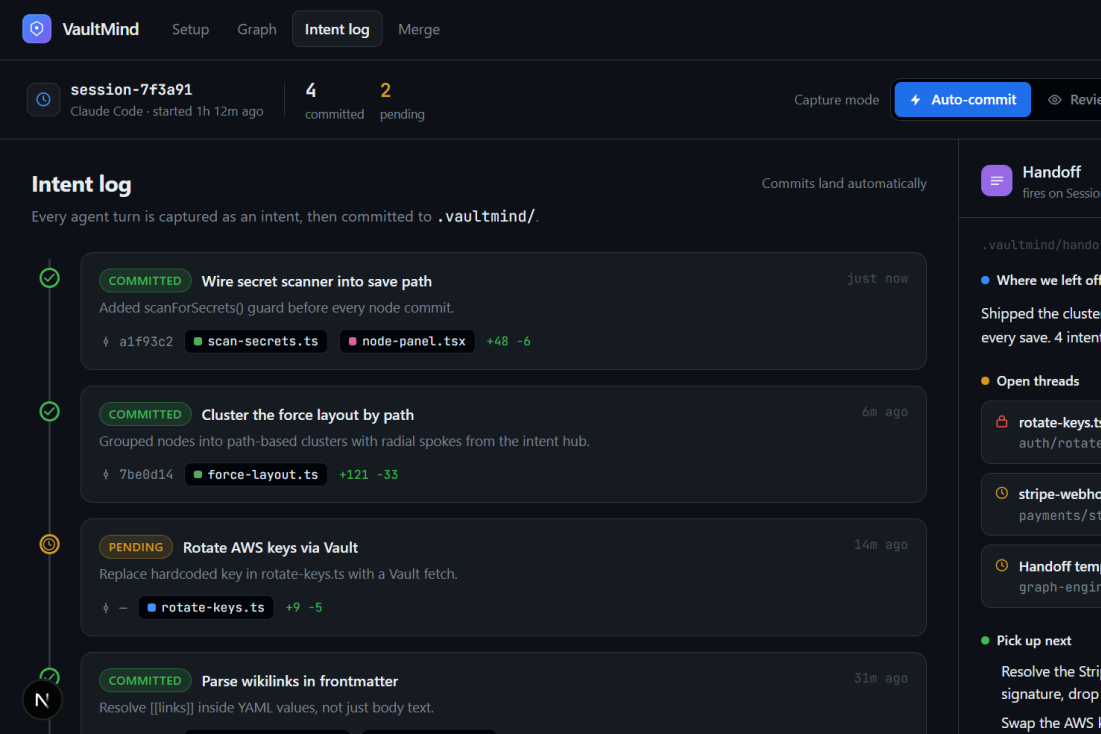
Intent Log
VaultMind
Inspiration
Every developer who juggles multiple LLM subscriptions has hit the same wall: you're deep in a Claude Code session, you've made dozens of decisions, debugged a subtle constraint, and established a clear direction, and then the session limit hits. The standard fix is asking the model to "summarize what we discussed," but that summary is generated at the worst possible moment: late, under context pressure, from a degraded view of its own history. LLMs attend well to the start and end of long contexts; the middle (often where the most important reasoning happened) gets fuzzy. The summary becomes a prediction about what probably happened, not a reliable record of what did.
We built Vault Mind because there is no clean, reliable way to hand off a working session from one LLM to another, and we wanted to fix that at the infrastructure level, not just paper over it.
What it does
VaultMind gives any LLM a persistent, structured memory that is fully transferable to any other LLM, without late-stage summarization.
As a developer works in Claude Code or Codex CLI, a lightweight background watcher picks up each completed turn via Stop/SessionEnd hooks. After every turn:
- A Scribe Agent extracts what just happened (decisions, constraints, goals, open questions) while the content is still fresh, before any context decay sets in.
- A Note Creator Agent structures that extraction into a Markdown node and writes it to an Obsidian-compatible vault living directly in the project git repo.
- A Connector Agent links related nodes together, building a real knowledge graph.
- A Fetch.AI uAgent Orchestrator coordinates the pipeline and exposes project state and handoffs over ASI:One.
When the developer hits a session limit or wants to switch to Gemini (or a fresh Claude Code session), they open the VaultMind web app, review the live graph in a trust interface, and confirm. The receiving agent reads the vault's .md files directly from disk. No serialization, no synthesis, no re-summarization. It picks up with the same structured context the first agent built.
Two small deterministic files anchor every handoff: VaultIndex.md (a map of the vault structure) and IntentLog.md (a running, append-only log of what the developer wants each session to accomplish, in their own words).
How we built it
We approached this as an infrastructure problem first, and engineered the seams before writing a single line of production code.
Stack:
- Python -- Stop/SessionEnd hooks, the agent pipeline (Scribe, Note Creator, Connector),
scanForSecrets()regex utility - Fetch.AI uAgents -- the Orchestrator, published on Agentverse with the Agent Chat Protocol, usable via ASI:One
- Redis Streams + Pub/Sub -- the hook-to-watcher queue and the pipeline-to-web-app live event bus; same Redis instance also serves Redis vector search for semantic memory
- Claude API -- structured tool use across all three generative agents
- Next.js (App Router) -- full-stack web app with SSE for live graph updates, no separate Express server
- React-force-graph -- the live knowledge graph visualization
- Arize -- tracing across all three LLM call sites (Scribe, Connector, Orchestrator) feeding one end-to-end evaluator that checks the full chain: did the extracted node accurately reflect the source turn, are the links relevant, does anything downstream drift from what's in the vault?
- Devin Cloud -- the three backend streams (P1 ingestion, P2 extraction/writing, P3 linking + Orchestrator) ran as parallel Devin Cloud sessions against the frozen spec seams, with human checkpoint review at every bucket boundary via Devin Review. P4 (the web app) stayed human-driven throughout.
Challenges we ran into
The late-summarization trap is subtler than it looks. Our earliest instinct was to have agents summarize more aggressively, but every time we pulled on that thread, we ended up recreating the exact failure mode we were trying to eliminate. The insight that unlocked the design: compressing a small fresh thing well is a fundamentally easier problem than compressing a large stale thing well. Per-turn extraction from a fresh, verbatim turn is a tractable problem; one big compression of a degraded context window is not.
Claude Code's own auto-compaction. Claude Code marks a compact_boundary event in its transcript when it runs low on context. Our Scribe Agent reads from the literal transcript, not Claude Code's internal context, so compaction doesn't corrupt the vault directly. But nodes extracted from turns shortly after a compaction boundary may accurately reflect what Claude said while Claude was already working from a thinner-than-usual memory. Our solution: flag, never infer or repair. A warning: Context compacted at [timestamp] entry goes into SessionState.md, and affected nodes get a subtle marker in the trust interface. We deliberately do not try to reconstruct what Claude may have lost. That would mean asking an AI to fill another AI's memory gap, which is exactly the generative risk this architecture is designed to avoid.
Secret protection had a real gap. An early version claimed secrets "always block both the commit and any handoff," but the only mechanism described was a git pre-commit hook, which by definition cannot fire on a handoff (no commit is involved). In Auto Mode specifically, a developer could hit Handoff without ever running git commit. The fix: scanForSecrets(content) is one shared regex utility called from three independent call sites: write-time, commit-time, and handoff-time. All three use the same pattern list. All three are deterministic and instant. The handoff trigger itself runs the check before proceeding, independent of git entirely.
Orchestrator round-trip latency. An early draft had every step bouncing back through the Orchestrator after each stage, creating multiple sequential network round-trips before a single node was even visible. The fix was not collapsing Scribe, Note Creator, and Connector into one call (which would re-concentrate exactly the unverifiable judgment we split them apart to avoid). Instead, Note Creator and Connector chain directly to each other for the fast, deterministic steps; the Orchestrator is invoked to kick off the pipeline and handle cross-turn coordination, not to broker every single hop.
IntentLog.md authorship. The intent log is meant to carry the developer's own words with zero hallucination risk. Allowing the AI to detect mid-session focus shifts and write to this file in Auto Mode is a real tradeoff: the developer trades the no-AI-writes guarantee for less friction. We resolved this by making it explicitly mode-dependent (consistent with the Auto/Review split that already governs the rest of the system) and being direct about the tradeoff in the pitch rather than glossing over it.
Accomplishments that we're proud of
- A handoff that actually works. A developer can be mid-session in Claude Code, hit a session limit, confirm the handoff, and have Gemini (or a fresh Claude session) pick up with full structured context, no re-explanation, no copy-pasting summaries.
- Honest architecture. Every design decision in VaultMind has a documented rationale and a documented tradeoff. We caught our own gaps (the secret protection hole, the Orchestrator latency problem, the IntentLog authorship question) before they became bugs.
- Sponsor integrations that reinforce the product. Redis vector search is the actual semantic search feature we needed. The Orchestrator's Agentverse registration is a real secondary interface, not a token integration. Arize tracing feeds one evaluator watching the whole pipeline end-to-end, verifying the system meets its own stated bar rather than just asserting it. Devin Cloud literally built the three backend streams in parallel against the same frozen seams that make VaultMind's own architecture safe.
- The Devin meta-story. VaultMind's premise (careful, structured, verifiable handoff beats one big unverifiable one) is exactly the discipline that makes Devin's parallel cloud sessions safe to run unattended. The project doesn't just use Devin; it demonstrates the same principle Devin's own architecture is built on.
What we learned
The most durable lesson: the failure mode that makes context handoff unreliable isn't compression per say. It's one large, late, unverifiable compression of an entire degraded conversation. Replace that with many small, immediate, high-fidelity extractions from fresh single turns, and the whole character of the problem changes. A single imperfect node doesn't sink the handoff; the surrounding nodes and links still carry real signal, and the user can see and fix any node before it reaches a receiving agent.
We also learned that externalizing plan and progress state to deterministic files that survive compaction (SessionState.md, IntentLog.md) is already established practice among heavy Claude Code users. VaultMind formalizes that pattern rather than inventing it from nothing, which is a feature, not a limitation.
And practically: frozen byte-level contracts at every seam boundary aren't just good practice for a four-person team under time pressure. They're the literal precondition for safely handing work to autonomous parallel agents. An ambiguous spec is fine when a human can ask a clarifying question mid-build. It's a real risk when cloud sessions run unattended against a shared repo.
What's next for VaultMind
- Dynamic
VaultIndex.md-- a deterministic graph traversal (breadth-first from the most recently active node) surfacing the 3-5 most connected/recent nodes, giving receiving agents a sharper entry point than a static vault map. - Team support -- the vault already lives in the shared repo, so multiple developers naturally contribute to the same knowledge graph. The merge conflict UI exists; we want to polish the multi-author experience into a first-class feature.
- Broader CLI support -- extending hooks beyond Claude Code and Codex to any tool that exposes a session transcript.
- Arize feedback loops -- the one end-to-end evaluator we shipped covers the full pipeline; we want to use what it surfaces to drive automated prompt refinement across sessions, closing the loop between tracing and improvement systematically rather than manually.
Built With
- arize
- asi:one
- claude
- claude-api
- claude-code-cli
- css
- devin
- fetch.ai
- gemini-api
- javascript
- next
- python
- react
- redis
- tailwind
- typescript








Log in or sign up for Devpost to join the conversation.