-
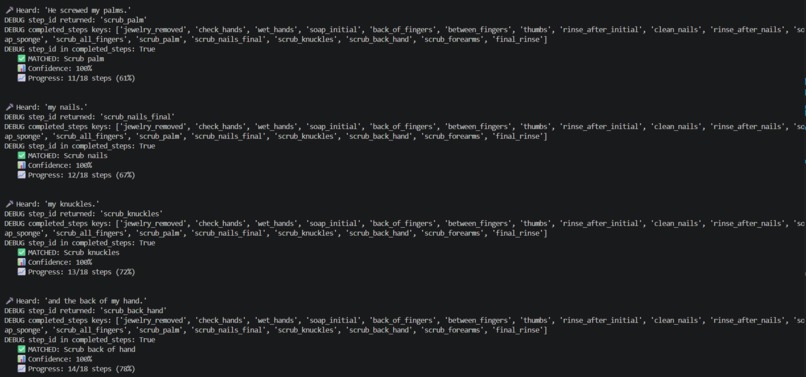
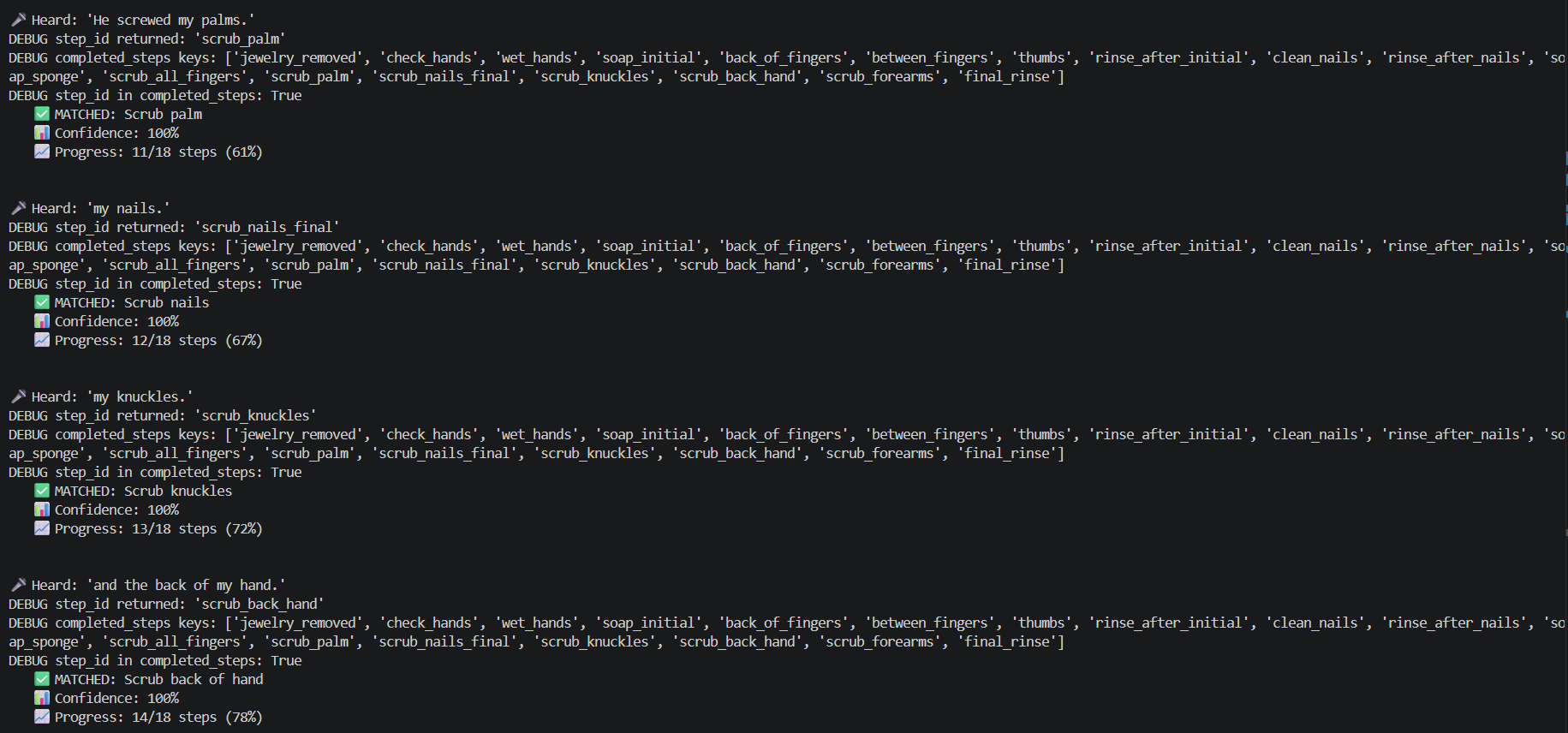
Example Checklist detection
-
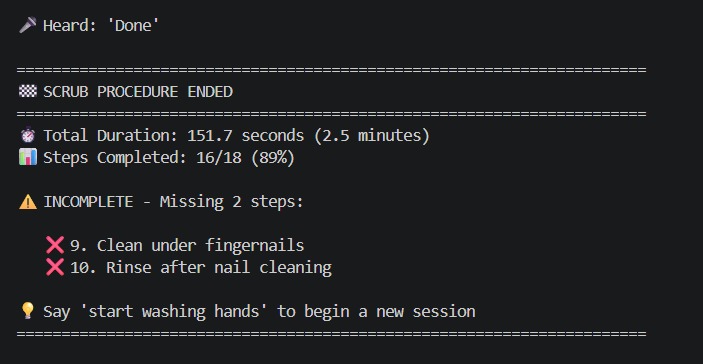
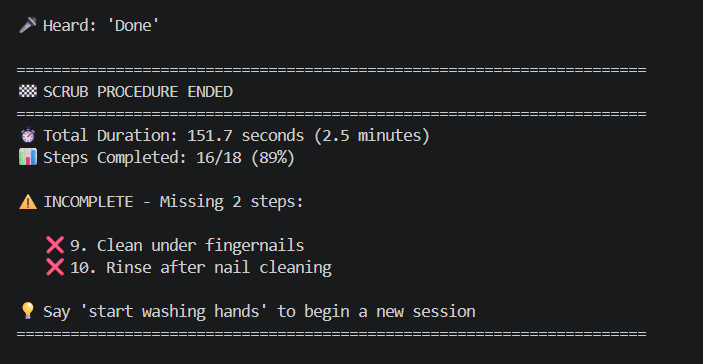
Example final output
-
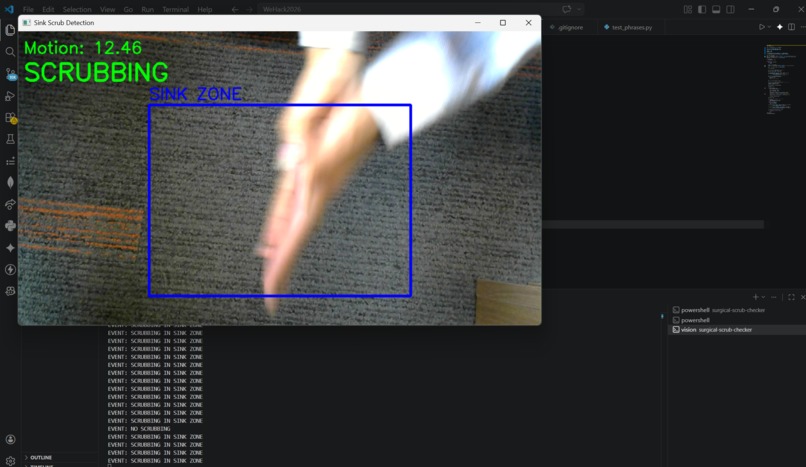
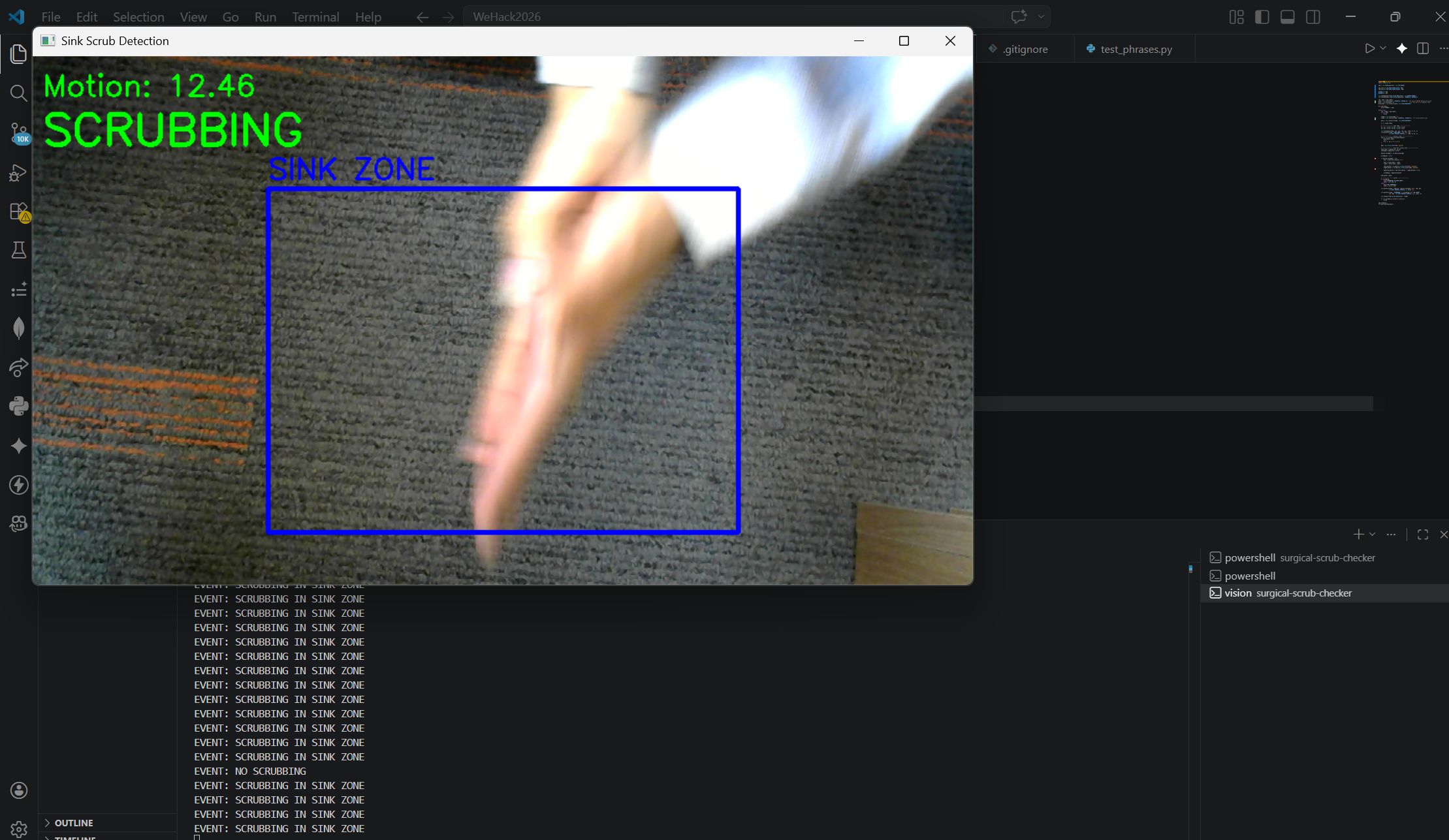
Computer Vision Scrubbing
-
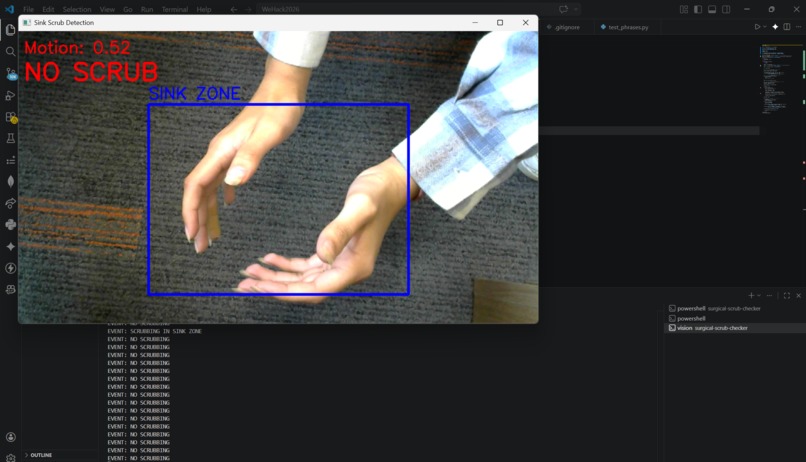
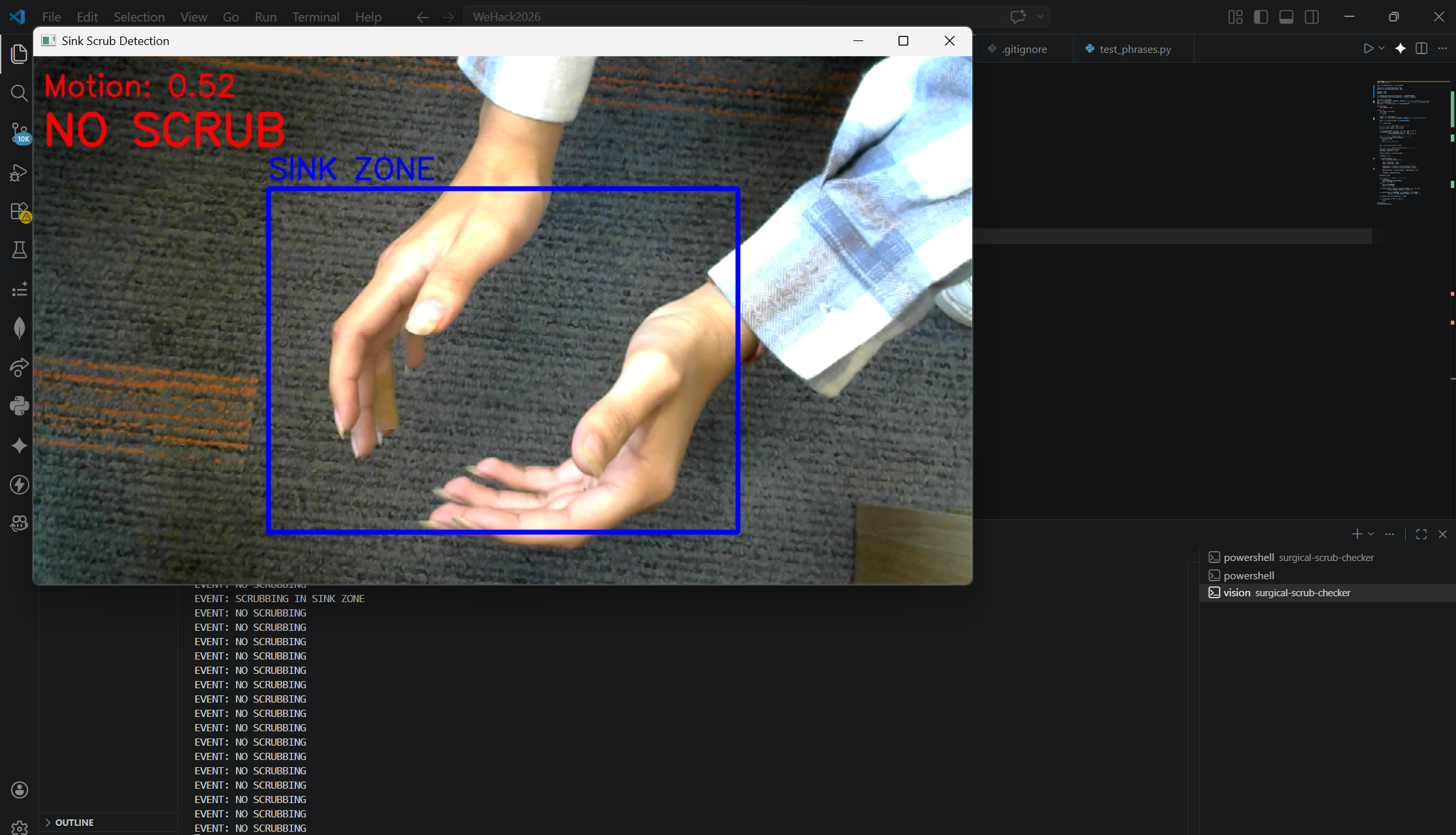
Computer Vision Not Scrubbing
Inspiration
Surgical site infections affect roughly 1 in 24 hospital patients, and most are preventable. Semmelweis figured out that handwashing saved lives in the 1840s and was laughed out of medicine for it. Lister was dismissed too. Thousands died waiting for the medical establishment to accept something that turned out to be simple. We have the protocols now — but compliance is still tracked manually, by people, under pressure, in environments where shortcuts happen.
One of our team members read about a case where a post-op infection was traced back to a break in scrub protocol that nobody caught. The surgeon thought every step was done. The checklist was signed. The patient still got infected — not because anyone was careless, but because the whole system relied on memory and self-reporting. That story stuck with us. We wanted to build something that never forgets a step, never assumes, and never lets something that critical slide by unverified.
What it does
ScrubAI listens to a surgeon as they wash their hands and checks off each step as it's spoken out loud. The surgeon just says what they're doing, like 'scrubbing between fingers', and the system understands it, even with accents or mumbling. It tracks progress through all 18 steps, and when they say 'done,' it reports exactly what was completed, what was missed, and whether they're cleared to enter the operating room.
The system transcribes speech offline using OpenAI's Whisper model and matches it to the correct step using three layers at once: keyword matching, AI embeddings for meaning, and fuzzy matching for errors. Saying 'taking off my bracelet' correctly identifies the jewelry removal step even though those exact words aren't in the protocol. If a match isn't confident enough, the system asks the surgeon to rephrase instead of guessing. Everything shows up on a screen in real time — the matched step, the confidence level, and current progress — readable even with wet hands.
On top of the voice system, ScrubAI also uses a camera that monitors the sink zone and uses optical flow analysis to detect scrubbing motion. If the motion strength exceeds a threshold and that pattern is detected, the system confirms active scrubbing is occurring.
How we built it
We built the system in Python across three layers. The first captures audio from the microphone and detects when someone is speaking. The second runs OpenAI's Whisper model locally to transcribe speech with no internet needed. The third is our custom ScrubChecker engine, which checks the transcribed text three ways at once: exact keyword matching, AI embeddings to understand meaning, and fuzzy matching to catch mumbled or mispronounced words. The clinical protocol lives in a JSON config file, so the procedure can be updated without touching any code.
We started with just keyword matching and quickly realized it couldn't handle the way people naturally talk. Adding AI embeddings helped a lot, but created a new problem. Words like 'rinse' and 'nails' appear in multiple steps, and the model had no way to tell which one was meant. That's what led us to build the context-aware scoring system from scratch, which tracks where you are in the procedure and uses that to figure out what the user actually means. That was the breakthrough that made everything work reliably.
The computer vision component was built using OpenCV and the Farneback optical flow algorithm. Every frame from the live camera feed is compared to the previous one to calculate motion vectors across the image. We defined a sink zone as a percentage of the frame and masked the flow analysis to only look inside that region. The zone is then split into left and right halves and we compare the average motion magnitude on each side, opposing movement between the two halves is the signature of hands scrubbing against each other. A motion strength threshold filters out background noise and minor movements, so only genuine scrubbing triggers a positive detection.
Challenges we ran into
The microphone alone took a few tries to get right. The device index we assumed was correct was wrong, so audio was coming in from the wrong source entirely. We had to write a utility just to figure out which mic was which. Once that was sorted, the sensitivity was too low and it was picking up keyboard clicks and background noise. We tuned that, then found it was cutting off the ends of sentences. Every single setting required real testing with actual speech to dial in.
Our screen situation was its own separate disaster. We started with a 4-inch ESP32 touchscreen that never turned on. We moved to a Grove LCD on a Raspberry Pi that we couldn't control because the Pi wouldn't connect to any network no matter what we tried — hotspot, ethernet, manually pre-loaded WiFi credentials, nothing. We then tried a 0.96 inch OLED on an Arduino Uno, but it wouldn't work either . After hours of debugging an intermittent connection we decided the screen wasn't worth the remaining time and cut it from the project entirely. The core AI and vision system was more important to get right.
On the software side, the newest version of Python broke two of our key libraries, so we had to roll back to get everything working. We also accidentally pushed our entire virtual environment to GitHub, which included files way over the size limit, and had to rewrite our commit history to fix it.
Another situation was getting the AI to handle words that show up in multiple steps. We had to build a system from scratch that tracks where you are in the procedure and uses that to figure out what you actually mean. Getting it tuned to work reliably took a lot of trial and error.
Accomplishments that we're proud of
The part we're most proud of is that the matching actually works in real conditions. Saying 'taking off my bracelet and earrings' correctly matches 'Remove all jewelry.' A misspoken phrase like 'scribbing around my thumbs' still matches the right step because the fuzzy matching catches the typo. And 'running my hands underwater' matches 'Wet hands and forearms' even though the two phrases share no words in common. We also got computer vision working to visually detect whether a surgeon is actually scrubbing. All of that was built without training a custom model or calling any external API.
We're also proud that everything runs completely offline — no API keys, no internet, no data leaving the device. In a hospital setting that actually matters, since patient data stays local and the system works even on restricted networks. The context-aware matching engine was also built from scratch during the hackathon, the idea that the system should know where it is in the procedure and use that to understand ambiguous phrases is what took it from something that sometimes worked to something that reliably works.
What we learned
The biggest thing we learned is that the hard part of building an AI system isn't the AI, it's everything around it. The matching engine came together pretty smoothly. The real grind was audio tuning, serial timing, version conflicts, and git disasters. Making something work in theory is very different from making it work when talking at it in a noisy room.
We also learned a lot about how AI language understanding actually works and where it breaks down. Embeddings are great at matching meaning, but they have no sense of order or context. That realization is what led us to build the sequential scoring system, and it changed how we think about using AI for step-by-step tasks.
On the practical side, never commit a virtual environment to git, and don't assume the latest Python version works with everything. Both of those mistakes cost us real time.
We also got a much deeper understanding of the scrub procedure itself. Encoding 18 steps into the system forced us to think carefully about which words were unique to each step and which ones showed up everywhere. Language is way more ambiguous than it looks until you try to teach a machine to follow it.
What's next for ScrubAI
The same system could work for gowning, gloving, and patient site prep just by swapping the config file. Long term, we want to build a dashboard that tracks compliance over time and shows which steps get missed most — patterns across thousands of sessions could reveal systemic problems no individual observer would catch. On the AI side, instead of presenting a list of missed steps at the end, we want the system to intervene in real time — pausing the session to say something like "You missed the back of your left hand" at the exact moment it's relevant. The surgeon acknowledges it, completes the step, and the computer vision system confirms the motion before the session continues. On the hardware side, the goal is a purpose-built waterproof unit that mounts next to a scrub sink. We'd also want to work with actual clinical staff to tune the system, since the protocol was encoded by engineers, not clinicians. And we'd like to release the matching engine as open source, since the problem of understanding natural language in step-by-step tasks applies well beyond surgical scrubbing.






Log in or sign up for Devpost to join the conversation.