-
-
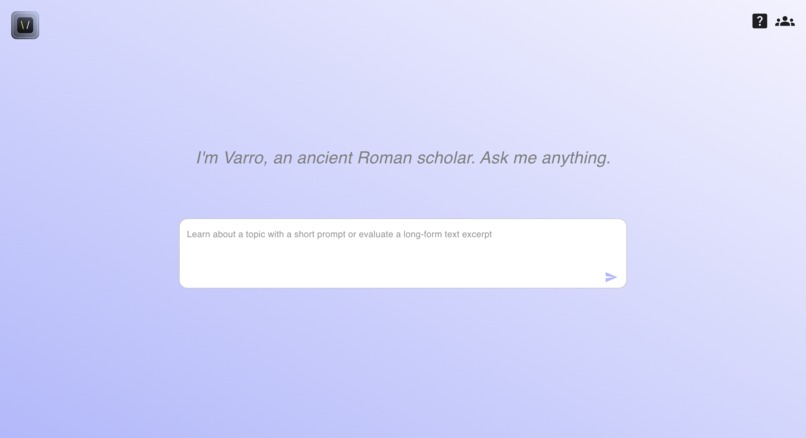
Varro Home Page
-

Varro Search Page
-

Varro Detailed Component Page
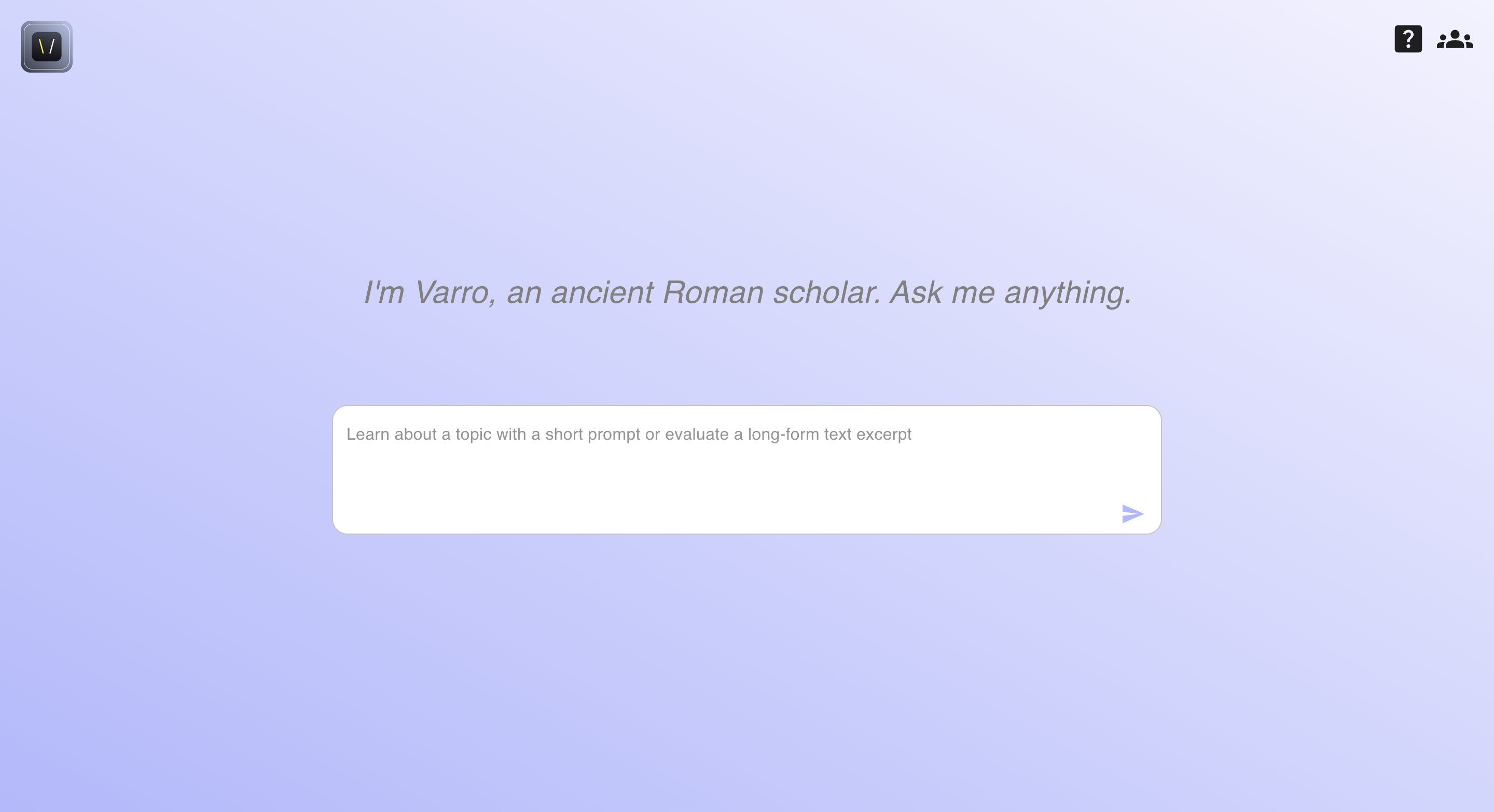


About Varro
Inspiration
In the past year, 77% of health-related information was found via general search engines like Google, Bing, or Yahoo. Only 13% of online health seekers referred to a site specializes in health information, and even even fewer relied on sources with data validation or peer review. As the pandemic showed us, this is a dangerously low number. Misinformation is a powerfully destructive force, especially as it relates to our health, but also as in its ability to incite political turmoil and misrepresent social movements. In a time marked by polarizing news sources and opinion-based posts, the importance of relying on data-driven, peer-reviewed insights cannot be overstated. Varro aims to address this issue by providing users with only research-backed information written by experts in a user-friendly and easily digestible format.
What it does
Varro is a search engine that allows users to paste long-form text from research papers into the website. The platform then uses AI, including the OpenAI API and Semantic Scholars API, to condense the text into a short, research-oriented, searchable query. Users can also receive contextual information about related articles, such as title, authors, journal, number of citations, readability difficulty score, and sentiment analysis. Varro's goal is to help users access credible health information on the internet efficiently.
How we built it
Varro was built using the following technology stack:
Backend
- Python
- Flask
- OpenAI API
- Semantic Scholars API
Frontend
- React
- Axios (for HTTP requests from React to Flask server)
- Material-UI (for design)
Data Processing
- Python (for Flesch-Kincaid Grade Level Formula and sentiment analysis using VADER)
Deployment
- Docker: To containerize the application for easier management and deployment.
- AWS Elastic Beanstalk or Heroku: These platforms were chosen for their support of both Docker and Python and their ability to automatically scale based on traffic.
Version Control
- Git & GitHub: Used for version control and collaboration.
Challenges we ran into
During the development of Varro, we faced some challenges, including:
- Decoding JSON objects and handling API calls.
- Ensuring the accuracy and reliability of the contextual information.
- Managing and scaling the application's deployment.
- Ensuring a seamless user experience and user interface.
Accomplishments that we're proud of
Some of the key accomplishments we're proud of include:
- Successfully creating a functional search engine for research-backed health information.
- Implementing AI-powered text condensation and contextual analysis.
- Designing an engaging user interface using Figma, React, and Material-UI.
What we learned
Through the development of Varro, we gained valuable insights and learned the following:
- How to utilize AI and machine learning in the field of healthcare information retrieval.
- Efficient text processing and sentiment analysis techniques.
- Containerization and deployment of applications using Docker and cloud platforms.
- Effective collaboration and version control with Git and GitHub.
What's next for Varro
The future of Varro includes the following plans and improvements:
- Expanding the database of research articles and sources.
- Enhancing the user interface for an even more user-friendly experience.
- Integrating advanced AI models for better text condensation and analysis.
- Exploring partnerships with healthcare institutions and professionals to ensure the credibility of information.
- Deploying the application on platforms that can handle scaling automatically.
- Adding user profiles, allowing the option to save relevant searches and favorite articles.
- Tailoring future search results to adhere to past user preferences in readability and number of citations/references.
- Additional metrics gauging credibility of articles, as it relates to impact factor of journal or publication history of author.





Log in or sign up for Devpost to join the conversation.