-

-
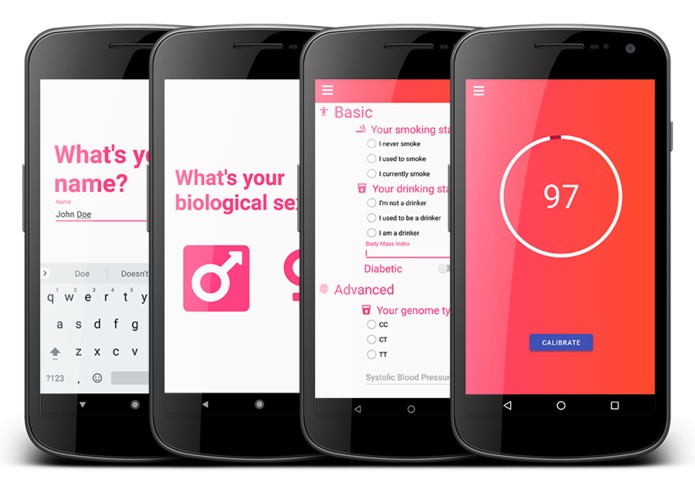
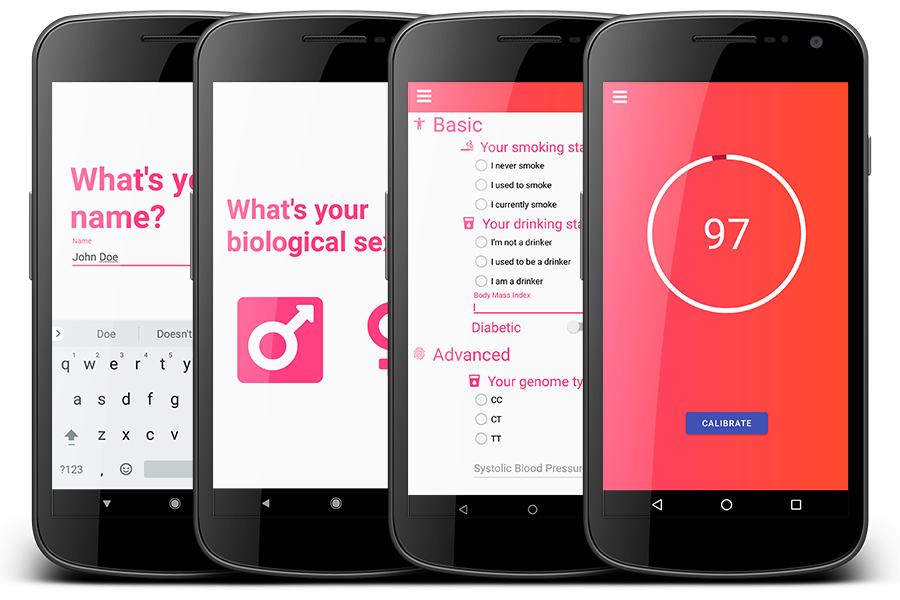
Vanguard intelligently rates the user's health using advanced algorithms and machine learning methods.

Vanguard
The personal intelligent health adviser
Team Members: Xi Pu, Siddhant Khanna, and Benjamin Xu
Why did we make Vanguard?
There is a stunning lack of health awareness that is prevalent even in developed countries like the United States. Many individuals who seem outwardly healthy are actually already at high risk for future cardio-cerebrovascular events, one of the most significant causes of mortality worldwide. This "faux-health" is a reflection of both the lack of widespread health education regarding important modifiable bio-markers and their impact on human health and longevity, as well as the lack of accessibility of more specialized health assessments to the general public. While sources for clinical reference ranges of these bio-markers exist online, individuals without access to their own biometric data are unable to use this information. We therefore wanted to integrate an intelligent risk assessment model with a way to accurately and precisely "fill in the blanks" in user data so all users could enjoy the benefits of increased health conscientiousness.

According to the WHO, in 2016, the top 3 causes of mortality globally were all cardio-cerebrovascular events.[6]
What does Vanguard do?
Vanguard uses a scientifically verified high-accuracy algorithm based on clinically selected human bio-marker data to generate an estimate of the user's level of health based on their risk of future cardio-cerebrovascular events. Vanguard does this through imputation-augmented user-inputted health data; many users will not have access to the full battery of bio-markers, so missing values will be resolved through data imputation powered by machine-learning methods in order to provide accurate user profiles despite incomplete data.
Understanding Your Risk Score
After inputting your biometric data, Vanguard's algorithm calculates a standardized "health score" that compares how healthy you are to the average population. It is scaled from 1-100, and the higher your score, the healthier you are.
How did we do it?
Front End
Material Design
Google's Material Components is an open-source drop-in replacement for Android's Design Support Library, and provides us with an adaptable system of guidelines, components, and tools facilitating the implementation of the best practices of UI design.
Back End
Risk Model
Framingham Risk Score
The Framingham Risk Score is a powerful and surprisingly accurate tool for the assessment of 10-year cardiovascular risk, and was developed on the basis of data from one of the largest and longest-running cohorts in clinical research.[1] We used this model as reference, and as inspiration as we borrowed upon the methods that the scientists used to create this model, and adapted them to our context.
CSPPT Risk Score
The CSPPT is one of the most famous recently conducted clinical trials, for both its ingenuity of design and the powerful implications of its findings. We were fortunate enough to have access to a dataset of over 20,000 individuals from this trial, including important information for a substantial amount of significant bio-markers. Using this data, we developed our own risk model based on the Cox Proportional Hazards Model, adapted it to better accommodate our target user base, and augmented it with additional statistical transformations in order to produce a standardized scoring system.
Data Imputation
While science has provided clinicians with a plethora of bio-markers for common diseases and overall health, these bio-markers are often unable to be applied in a useful way due to many individuals not having access to the examinations and assays that would produce this data. As a result, classical models for estimating risk which rely on all this data being present often fall flat in practice when most of this data is missing. As a result, we decided that in order to effectively implement a risk model, a central aspect of our technology would involve a powerful and accurate method for imputing these missing values so that our risk algorithms could function at the highest degrees of specificity and sensitivity possible. Thus, we turned towards data imputation, which is a general term for methods to fill in missing or invalid data.
Machine Learning
While classical heuristics for imputation methods exist, they rarely provide accurate estimations as to the missing values. We therefore turned towards the more advanced and powerful, but also more difficult to implement strategy of using machine learning as an imputation tool.
There are a plethora of machine learning methods when it comes to any application, and imputation is no exception. Several of the popular groups of methods include Nearest Neighbors, Self-Organizing-Maps (i.e. Kohonen Maps), Decision Trees, and Bayesian Networks. Each of these methods has its own advantages and drawbacks, but it has been shown that there isn't necessarily a clear winner or best method among them; that is to say, the choice of the method would be unlikely to significantly impact the accuracy of the product.[3]
While many of these methods also exist in the form of different algorithms, we decided to base our design on the well-documented open-source implementation SOM-Toolkit, which provides utilities for the creation and training of Self-Organizing-Maps, a neural-network based structure, that can be used after training with a sufficiently sized dataset to impute missing values from a given input vector.[4]
More on Self-Organizing-Maps
"Self-organizing-map (SOM) neural networks offer a robust multivariate method for data analysis, capable of modeling the nonlinearities of a system thus providing good possibilities to estimate missing values in environmental data sets, taking into account relationships among pertinent variables in the vector-profile of the data record. In comparison with other data driven models such as multilayer perceptron ANNs, likelihood based approaches and classical multiple regression analysis, the SOM has been proved to have the best performance for imputation of missing values, in terms of both the correlation coefficient between the observed and predicted values as well as the mean square error of prediction. A further advantage of the SOM is that the same map can be used to predict any missing value in any variable, whereas new regression and multilayer perceptron ANN models have to be developed for each variable that contains missing values." [5]
What challenges did we encounter?
The Polylingual Conundrum
Matlab to Java
While earlier it was mentioned that an open-source implementation of SOM-based imputation was available for Matlab, the caveat that was not mentioned was that due to our Android-centric app development, we were working in a Java-powered environment, id est there was a literal language barrier preventing us from using the available implementation. This incompatibility necessitated the re-implementation of the Matlab algorithm in a Java environment, which was by no means a trivial feat, given that Matlab is a high-level language designed for ease-of-use such as Python or R, not to mention its matrix-based semantics, which stand in stark contract to Java's object-oriented design.
Dataframes R Cool
In addition to Matlab, Java, Git shell commands, there was yet another set of syntactic rules we had to learn for our project: the statistical analysis language R. Since a core element of our project revolved around machine-learning using a large dataset as a training matrix, a programmatic way of handling any manipulations to the raw dataset was required. Of course, we opted for the financially optimal open-source solution. In addition to complex matrix-wide operations, R also allowed us to construct our risk model through its support for statistical packages enabling us to compute a Cox Proportional Hazards Model from our data. Despite the addition of yet another language that we had to learn, R allowed us to develop the core back-end behavior necessary for our application to exist.
What did we learn?
As a team, we knew next to nothing about anything that was involved in creating this app. In short, all the skills that were required to implement our product were learned on the spot as we were working. App development in android was completely alien; trying to decipher Matlab, a language none of us had ever learned, was ludicrously and unnecessarily involved; creating appealing and functional user interfaces and user experiences was a deceptively complex. In short, in order to put together Vanguard from scratch, all of us were forced to not only step out of our comfort zone, but blast out of it at terminal velocities.
Limitations
User Characteristics
Due to the nature of the data we had to work with, our algorithms work best with individuals who are more similar to the individuals present in our data; in practical terms, this means that adults and elderly would be more likely to receive more accurate results compared to younger users, for example.
Relative Risk & Age
The currently implemented algorithm considers age to be a variable affecting health just like other variables such as blood pressure or serum total cholesterol levels. This produces a more accurate absolute estimation of risk, it does not provide users with an age-adjusted score. While more accurate, the downside of this choice is that user score will inevitably decrease as they age, even if they maintain their health in all other aspects, leading to a frustrating user experience over the long term.
References
- "NHLBI, Estimate of 10-Year Risk for CHD". Nhlbi.nih.gov. Retrieved 2018-10-12.
- Huo, Y., Li, J., Qin, X., Huang, Y., Wang, X., Gottesman, R. F., ... & Fu, J. (2015). Efficacy of folic acid therapy in primary prevention of stroke among adults with hypertension in China: the CSPPT randomized clinical trial. Jama, 313(13), 1325-1335.
- Liu, Y., & Gopalakrishnan, V. (2017). An overview and evaluation of recent machine learning imputation methods using cardiac imaging data. Data, 2(1), 8.
- J. Vesanto, J.E. Himberg, E. Alhoniemi, J. Parhankangas Report A57 SOM Toolbox for Matlab 5, Helsinki University of Technology, Finland (2000)
- L. Folguera, J. Zupan, D. Cicerone, J.F. Magallanes Self-organizing maps for imputation of missing data in incomplete data matrices Chemom. Intell. Lab. Syst., 143 (2015), pp. 146-151
- "Global Health Estimates 2016: Death by Cause, Age, Sex, by Country and by Region, 2000-2016". Geneva, World Health Organization; 2018






Log in or sign up for Devpost to join the conversation.