The Challenge
BILL.com subscribers are able to make purchases with their corporate card solution. When a purchase is made, users fill in information about the purchase such as the date of the purchase, the amount, and vendor name. To validate the purchase, a receipt must be attached. Therefore reconciling all transactions is a time consuming process. To alleviate this time consuming task of matching uploaded receipts with past transactions we were challenged to design a Receipt Matching algorithm to save customers’ time.
Plan of Attack
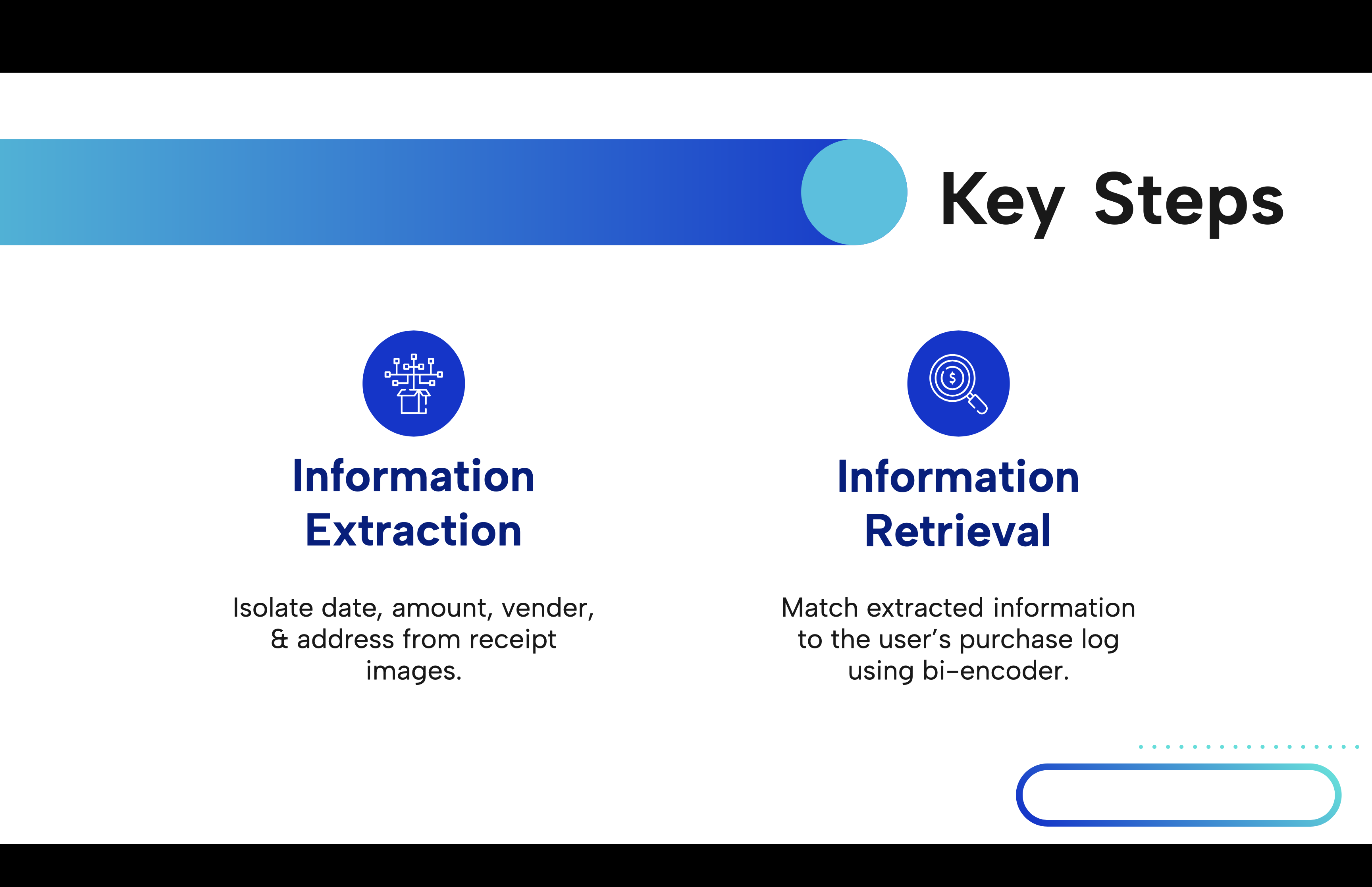
Our approach involves two main steps– Information Extraction and Information Retrieval.
(1) Information Extraction
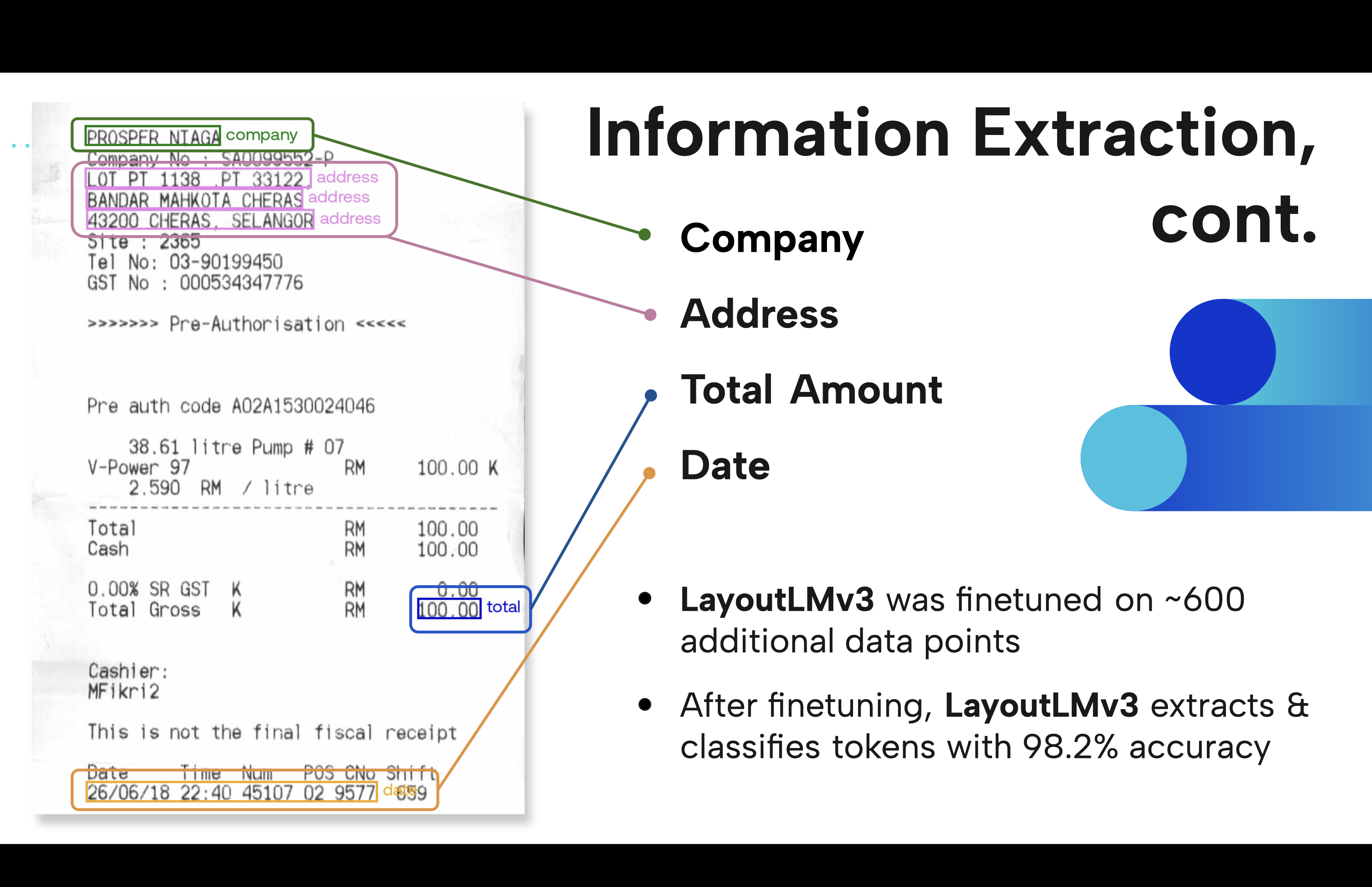
Given images of the receipts, we performed key information extraction to isolate the date, transaction amount, vendor, and vendor address. We used a state-of-the-art model (LayoutLMv3) and fine tuned it on an open source labeled receipt dataset, to make the problem more achievable by using supervised learning. We tokenized and extracted the key information with an accuracy of around ~98%.
Main resource/inspiration: https://arxiv.org/pdf/1912.13318.pdf
(2) Information Retrieval
Matching the extracted information from the receipts to the user inputted transaction logs.
We tried two different approaches, as detailed below, with the second approach producing the best results.
(1) Approach 1
Our initial approach was based on semantic similarity. Essentially, we wanted to embed the user logs (queries) and the receipts (answers) in the same n-dimensional vector space and then obtain matches for the queries using cosine distance. The answer with the closest cosine distance from a query would be the “match” for the query. Similarly, the top k closest answers would be the top k matches for a query. We used off-the-shelf language models similar to BERT to embed text.
One of the things we noticed right off the bat was that performance drastically increased as k increased. Many times the algorithm would find the correct match but would rank it as the 5th closest or 10th closest etc. match. In order to fix the rankings, we decided to use a second model to rerank retrieved matches from the first step. In order to be effective, we reasoned that this second model should use a different architecture than the first (in order to provide “new reasoning”). For the second model we ended up using a cross-encoder to rerank potential matches. Taken together, we called this approach retrieve and rerank. This approach has been shown to be successful in other sentence similarity tasks.
Unfortunately, while this approach showed initial promise on the training dataset (n=1 match accuracy of 43%), it was difficult to improve via tuning and it performed very badly on the test data (accuracy at n=1 of just 10%). We therefore decided to move to a completely different approach detailed below.
Source/Inspiration: https://www.sbert.net/examples/applications/retrieve_rerank/README.html
(2) Approach 2
To match the extracted information to the user input, we created a ranking algorithm using matching scores from the FuzzyWuzzy library. The algorithm was functionally weighted sum of the matches between total, date, vendor, and address.
For performance, the ideal scenario is to immediately match the logged purchase to the correct receipt. Without an extensive labeled training set and given the time restrictions we were operating under, this was not a reasonable goal. Instead, we considered the use-case. When matching logs to receipts, it is still extremely helpful to avoid making the user search through every receipt to find a match. Instead, giving them only 3 or 5 receipts to choose from would still improve their experience with Bill.com significantly. Therefore, our target metric was "matching accuracy in top 1 guess, top 3 guesses, top 5 guesses." We aimed to always identify the correct receipt in 5 or fewer guesses. Ultimately, the best results came from our ranking algorithm with test accuracy of 59.5% for top 1 guess, 73% for top 3 guesses, and 75.4% for top 5 guesses.
Challenges we ran into
For the images, some of the receipts were difficult to read, had writing scribble over some of them, and across the board contained inconsistent formatting, all of which posed problems with unsupervised feature extraction (ultimately leading us to explore what open source labeled datasets were available). The user inputted data was also riddled with typos and other errors, making standard matching procedures less effective, hence complicating the problem.
Accomplishments that we're proud of
Completing this complex challenged in such a short span of time.

Log in or sign up for Devpost to join the conversation.