-
-
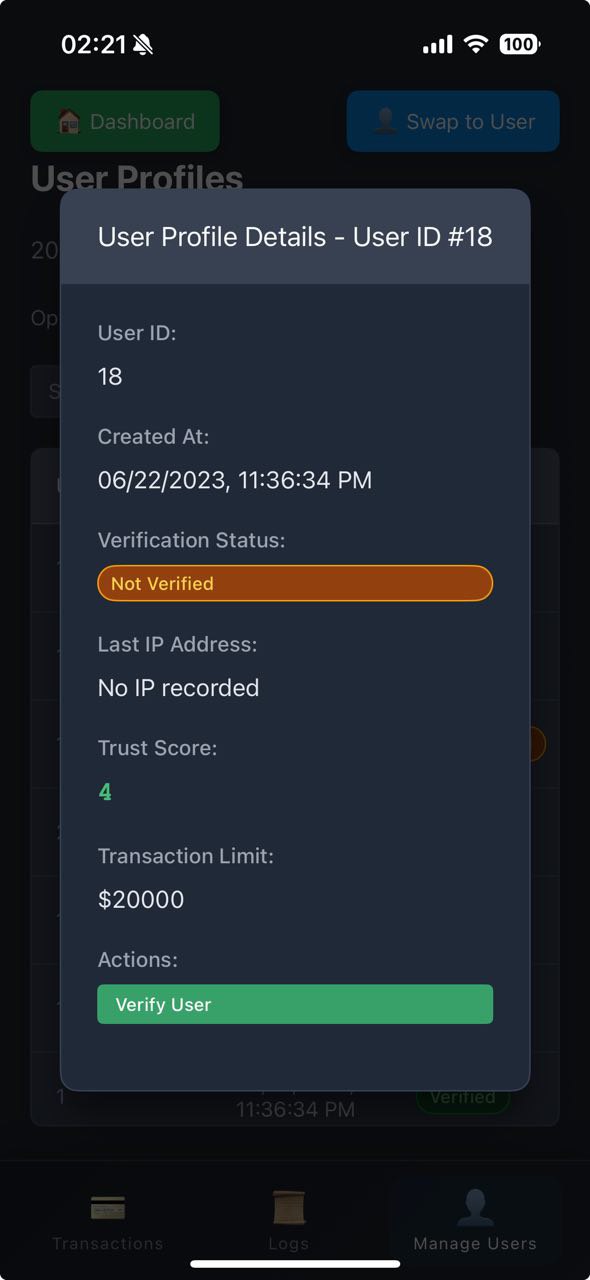
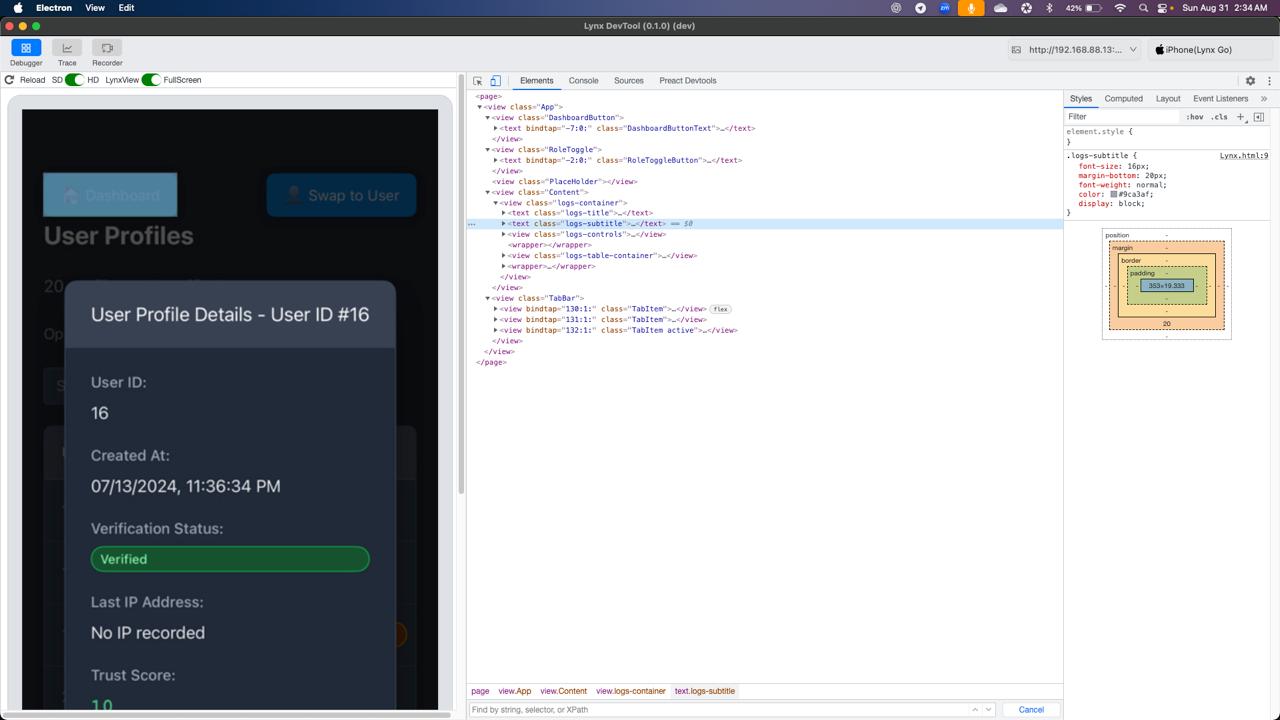
View User Details
-
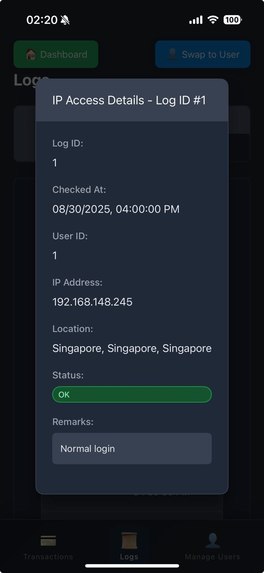
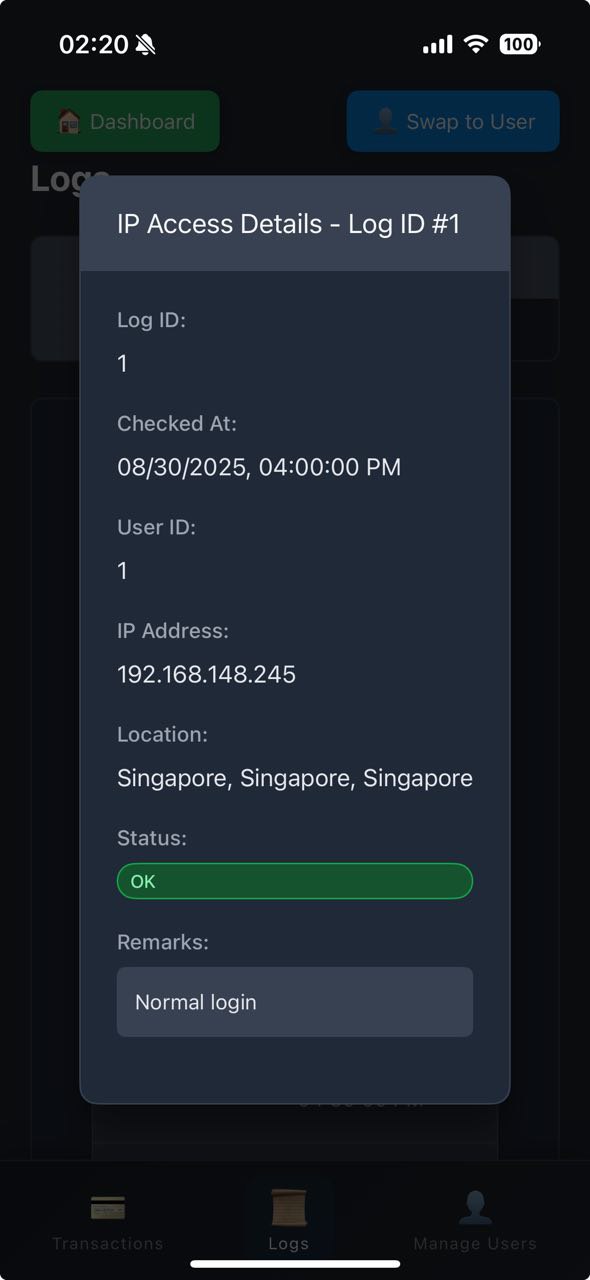
IP Access Details
-
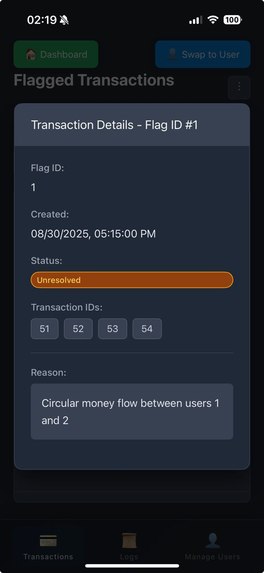
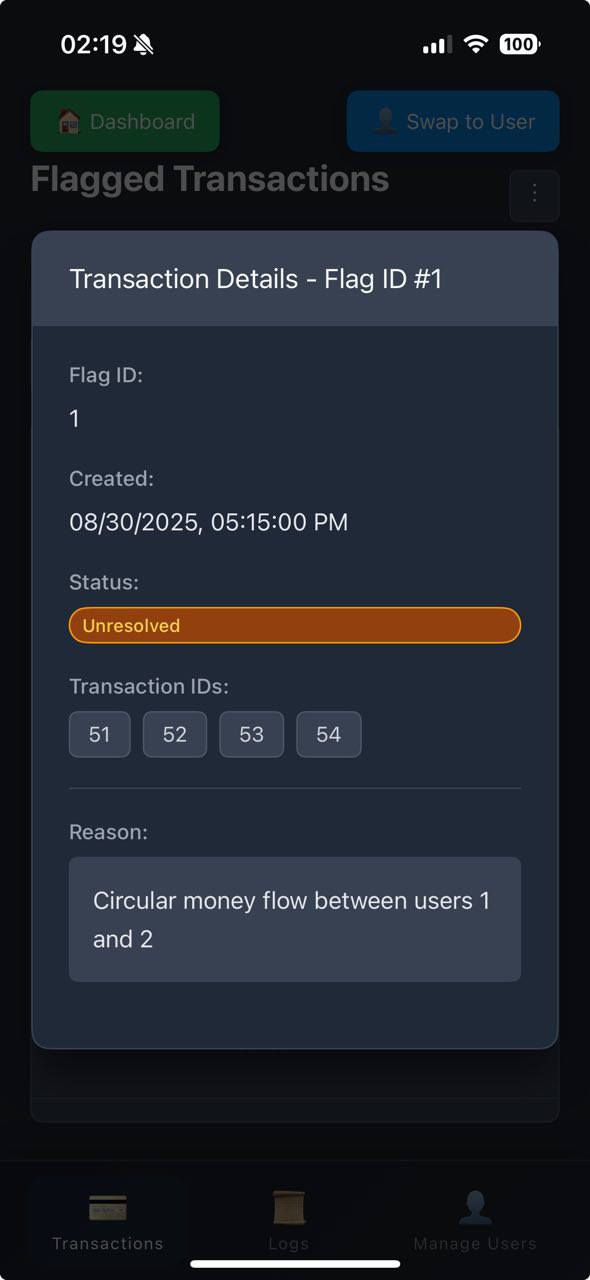
Transaction Details
-

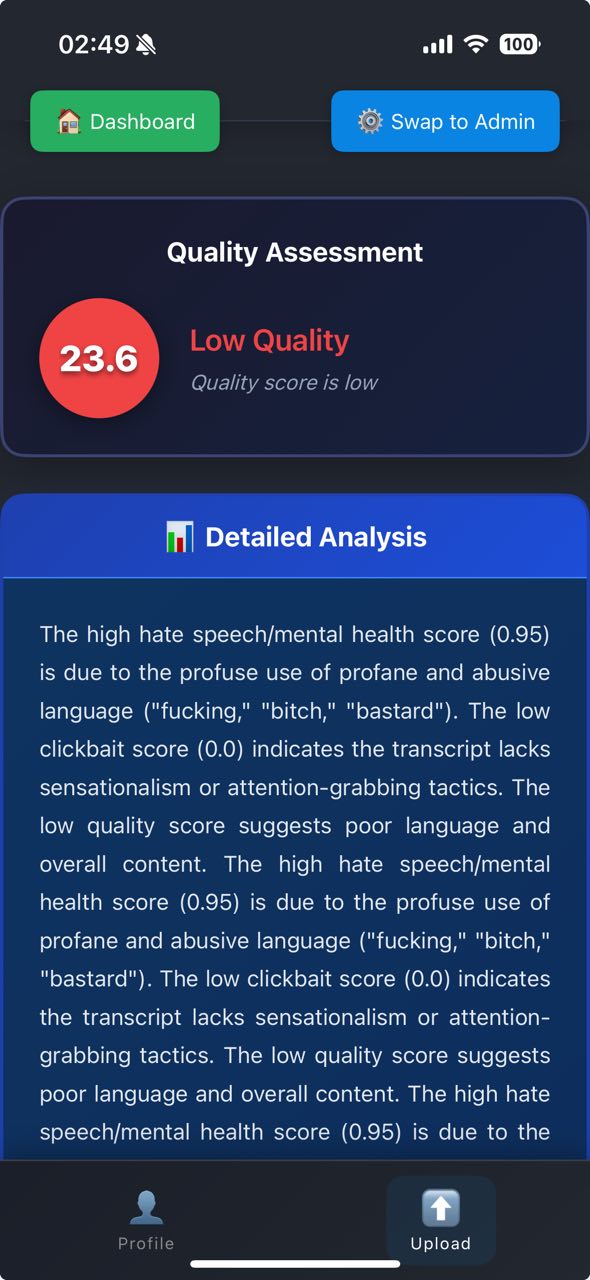
Content Moderation by AI
-
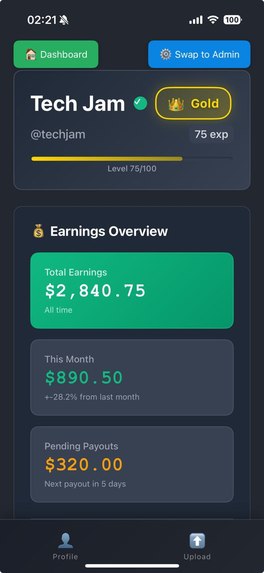
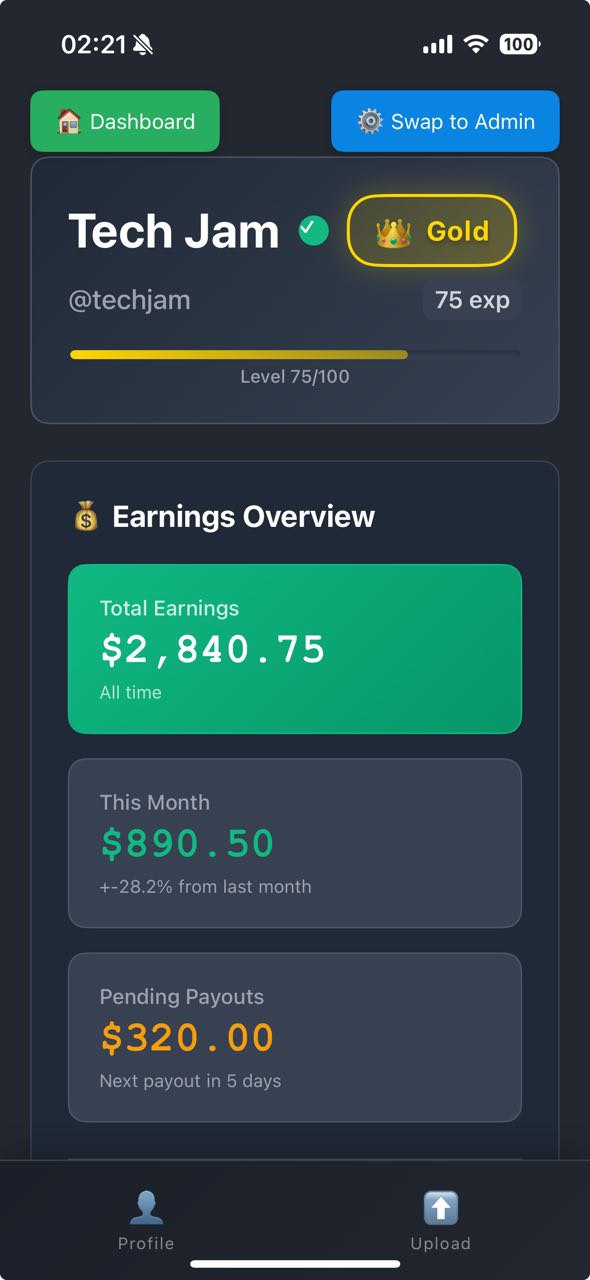
Creator Dashboard
-
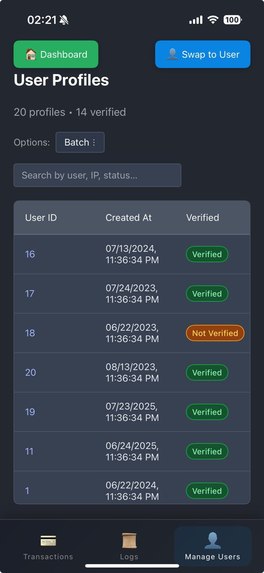
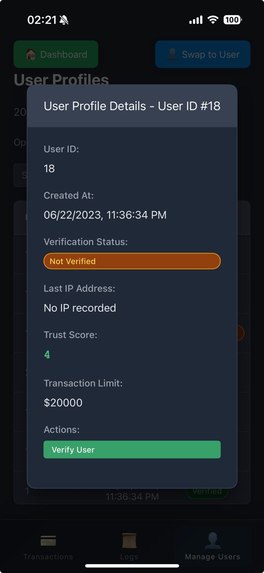
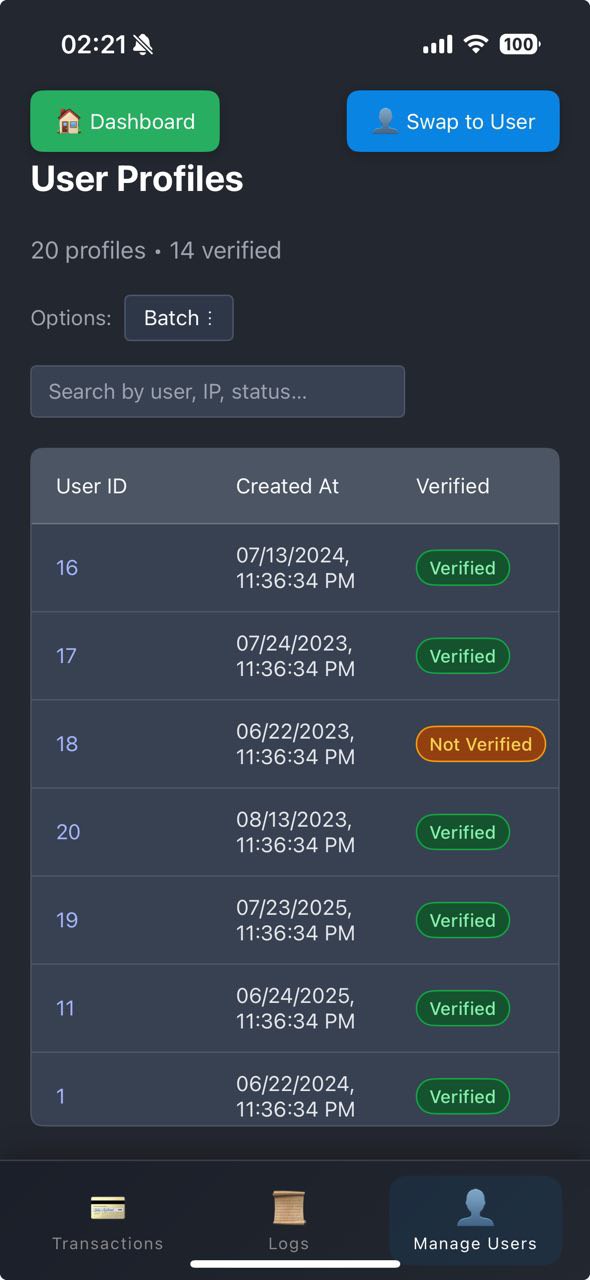
View User Profiles
-
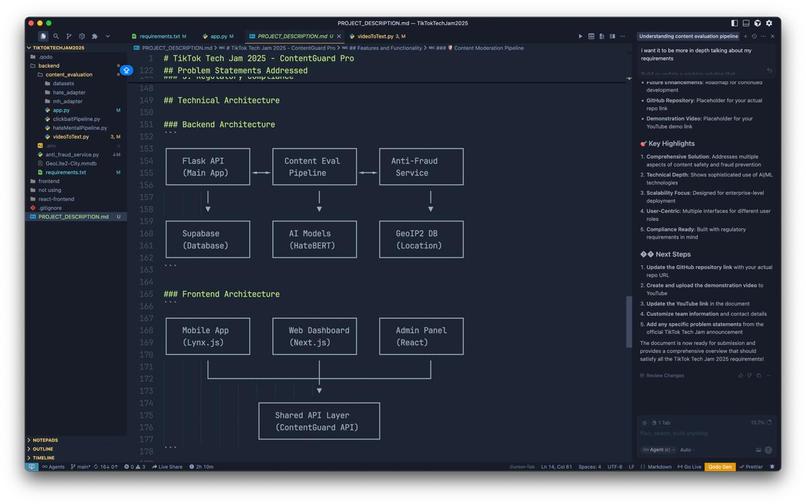
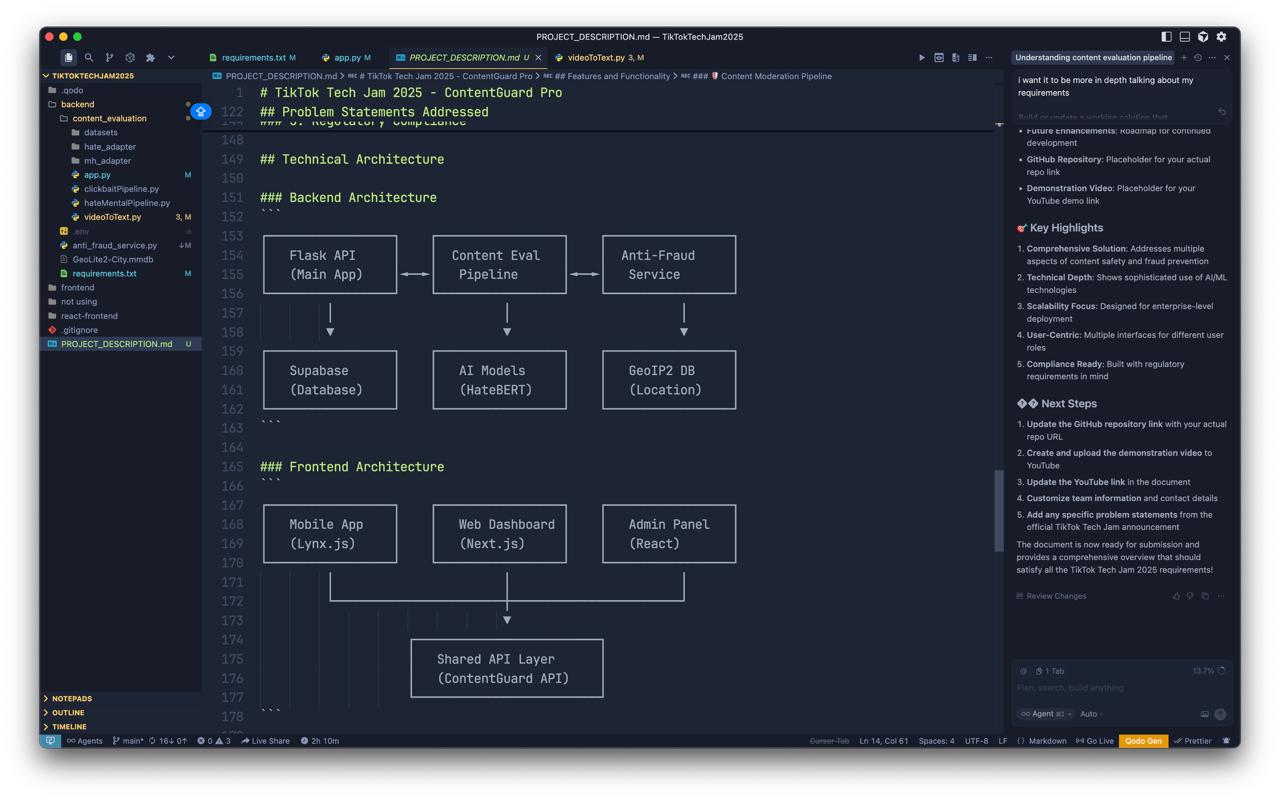
Rough Architectural Diagram
-
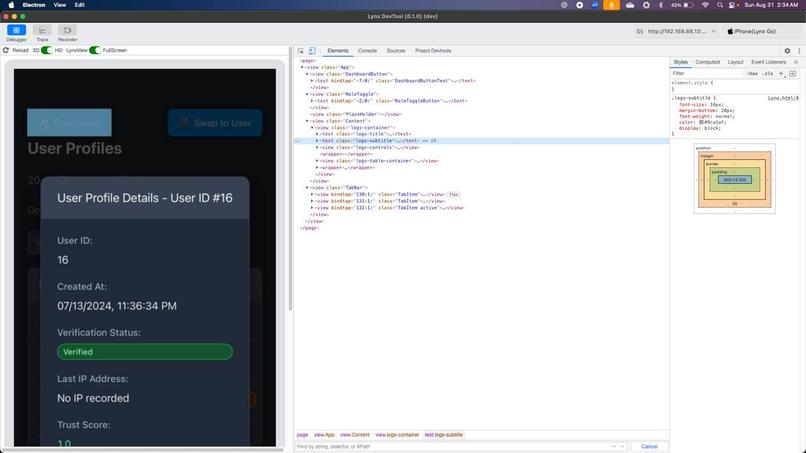
Use of Lynx Debugger
ValueTok - Fair Creator Rewards System
Inspiration
Creator rewards on TikTok can be opaque and gameable; we need a fair, transparent value-sharing system that protects viewers, rewards quality, and resists fraud—without slowing creators down.
What it does
- Evaluates content risk in real time on video transcripts (hate speech + mental-health risk + clickbait detection)
- Gates content quality using a Quality Score with 50% threshold (content flagged if score < 50)
- Provides comprehensive anti-fraud protection with IP monitoring, transaction limits, velocity checks, and pattern matching
- Creator recognition: user verification system with trust scores and milestone tracking to reward sustained safe, quality creation
How we built it
Content Evaluation Pipeline
1. Ingest
- FFmpeg extracts audio
- Whisper to transcribe audio to english text
2. Risk Models (Hybrid Local + LLM)
Hate-Safety Risk Detection
- Primary Model: Fine-tuned BERT adapter (
hate_adapter/) - Dataset: Kaggle Hate Speech and Offensive Language Dataset (
hd_final.csv) https://www.kaggle.com/datasets/mrmorj/hate-speech-and-offensive-language-dataset - Fallback: Gemini 1.5 Flash LLM with prompt engineering
- Confidence Threshold: 0.5 - if local model confidence < 0.5, use LLM
- Features: Detects hate speech, offensive language, toxic content
Mental-Health Risk Detection
- Primary Model: Fine-tuned BERT adapter (
mh_adapter/) - Dataset: Kaggle Sentiment Analysis for Mental Health Dataset (
mhd_final.csv) https://www.kaggle.com/code/engsaiedali/mental-health-text-classification-with-huggingface - Fallback: Gemini 1.5 Flash LLM for edge cases
- Confidence Threshold: 0.5 - if local model confidence < 0.5, use LLM
- Features: Detects self-harm signals, eating disorders, harassment, mental health concerns
Clickbait Detection
- Model: Gemini 1.5 Flash with specialized prompt engineering
- Strategy: Analyzes common clickbait patterns and phrases
3. Safety Risk Score (SRS) Calculation
SRS = (0.7 × HateSpeechRisk) + (0.3 × MentalHealthRisk)
Weighting Rationale:
- Hate speech misclassification carries higher immediate social/brand cost
- Mental health concerns, while important, have different risk profiles
- 0.7/0.3 ratio reflects risk sensitivity in social media context
4. Quality Assessment
- Final Score Formula:
(1 - (SRS × 0.8 + ClickbaitScore × 0.2)) × 100 - Threshold: Content flagged if final score < 50
- AI Summary: Gemini generates explanation of scores and reasoning
- Output: Quality score (0-100) + AI-generated explanation
5. API Endpoints
Content Evaluation Service (content_evaluation/app.py)
POST /checkContent- Analyze video content and return moderation scoresPOST /flagged- Store flagged content in database (future implementation)
Request Format for /checkContent:
{
"url": "video_url_here"
}
Response Format:
{
"message": "Quality score is high/low",
"score": 85.2,
"summary": "AI-generated explanation of the scores and reasoning"
}
Profit-Sharing Mechanisms
Performance-Based Incentives
- Rewards linked to views and sales (↑ Views, ↓ Platform Fees)
- High performers earn proportionally more
Fairness
- No penalty for success; platform fees shrink with growth (based on view counts/sales)
- Equal starting structure for all creators
- Rewards are merit-based, protecting newcomers (e.g., the first 5 Live sessions are free from Platform Fees)
Sustainable, Mutual Benefit
- Encourages creator growth, which in turn boosts platform activity
- Builds trust, motivation, and better content quality
Value Transfer Pathways from Consumers to Creators
Follower Milestones
- Creators are rewarded with bonuses upon reaching specific follower milestone goals
- They can also receive plaques or other recognition awards (inspired by YouTube)
- This system is designed to encourage long-term growth and foster consumer loyalty towards creators
Trend Incentives
- Creators have the ability to submit new trend ideas for administrative approval
- If a submitted trend gains popularity, the original creator receives additional rewards and a "promotional push" for being the initiator
- A key aspect of this incentive is to ensure fair credit and compensation for originality
Overall Impact: Transforms consumer engagement (follows, trend adoption) into direct rewards for creators, creating transparent pathways where effort and creativity are fairly compensated.
AML (Anti-Money Laundering) Compliance & Anti-Fraud Prevention
IP Monitoring
- Detects multiple accounts from the same person/IP
- Flags sudden country switching / VPN abuse
- Supports KYC (Know Your Customer) & identity verification
Transaction Limits
- Viewers: New accounts are capped at $500/day, with limits increasing with trust
- Creators: Unverified creators are capped on daily gifts
- Prevents large transfers & smurfing (splitting illegal funds into small amounts)
Velocity Checks
- Monitors the speed of sending/receiving gifts
- Stops bot-driven rapid transfers
Pattern Matching
- Detects circular money flows (e.g., A → B → A → B)
- Flags suspicious transfer chains
- Prevents layering of illicit funds
Architecture / Stack
- Backend: Node.js (Express)
- ML: Python (PyTorch/TensorFlow); FastAPI/Flask service
- ASR: Whisper API
- Data: Supabase
- Frontend: Lynx
Challenges we ran into
- Adapter training complexity: configuring adapters correctly (activating, freezing base model, choosing between Trainer and AdapterTrainer) caused initial errors
- Compute limitations: Google Colab's free GPU limits interrupted long training sessions, forcing us to optimise batch sizes and epochs
- Lynx: Hard to setup developer tools for it. Certain CSS features and tailwind does not work well with it (Overflow and Word-Wrap). The way to input files in was challenging too
Accomplishments that we're proud of
- Successfully integrating Lynx into our project, enabling advanced processing and analysis
- Implementing a multi-stage content evaluation pipeline combining hate detection, mental health assessment, and clickbait detection
- Fine-tuning adapters on domain-specific tasks to improve model performance while keeping base model weights frozen
- Designing a fallback mechanism using an LLM for low-confidence predictions to ensure reliable evaluation
What we learned
- Learning a new framework Lynx
- Learning how to convert video to speech to text with the use of moviepy and Whisper by OpenAI
- Exploring the use of adapters for fine-tuning models, which allow for parameter-efficient training by adding small trainable modules to a frozen large language model. This enables customisation for specific tasks (e.g., hate speech detection) without needing to retrain the entire model, saving both time and compute resources
What's next for ValueTok
We'll let you know when we are all hired! 😄











Log in or sign up for Devpost to join the conversation.