-
-
Default Landing Page
-
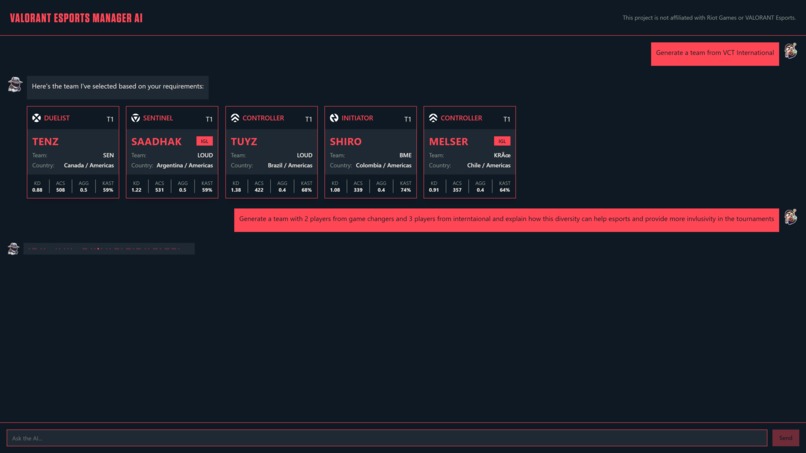
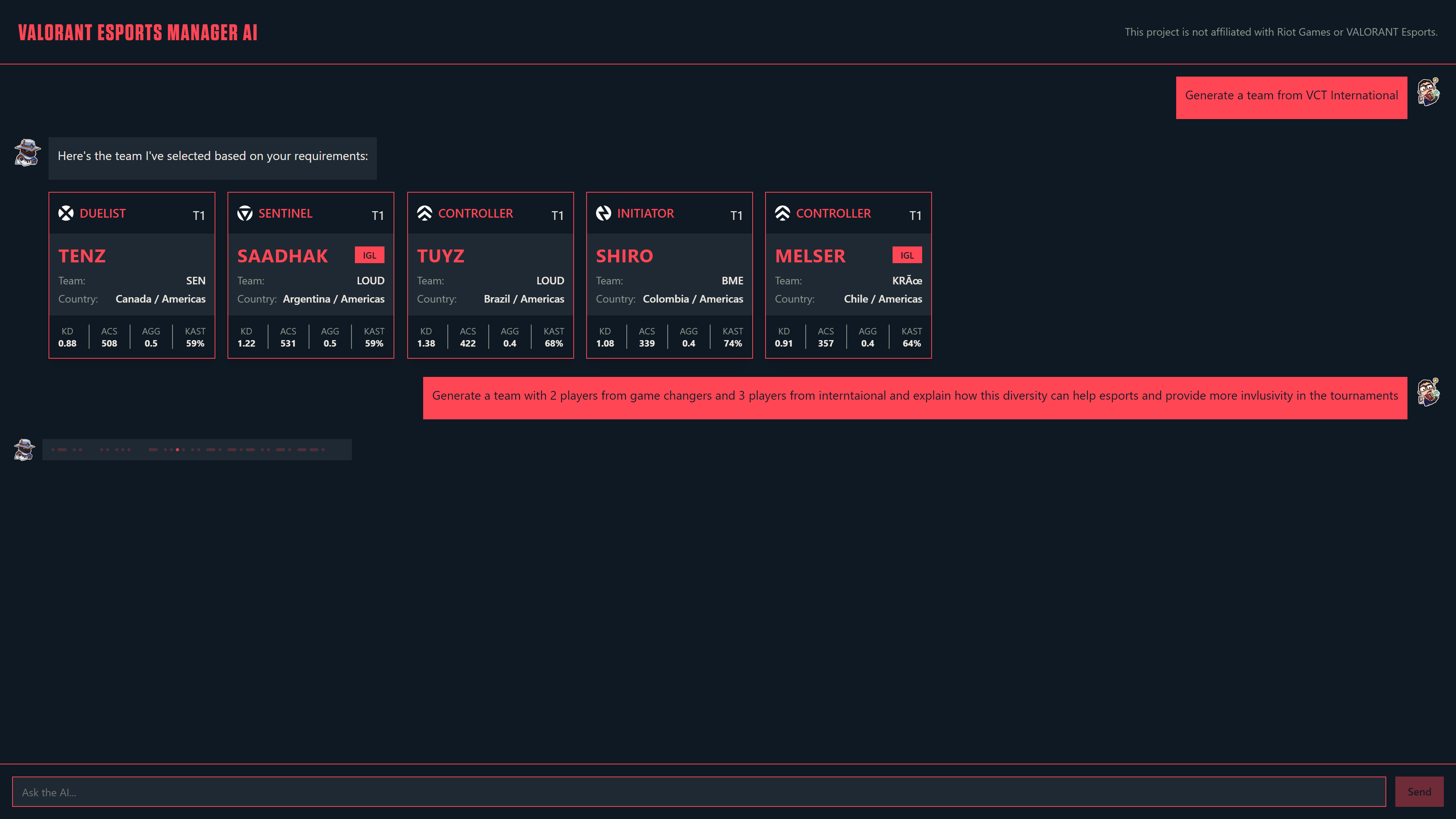
Asking to generate a team
-
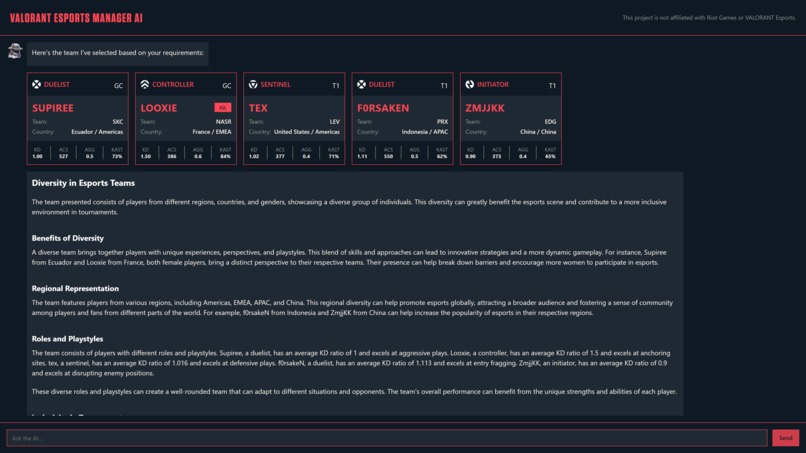
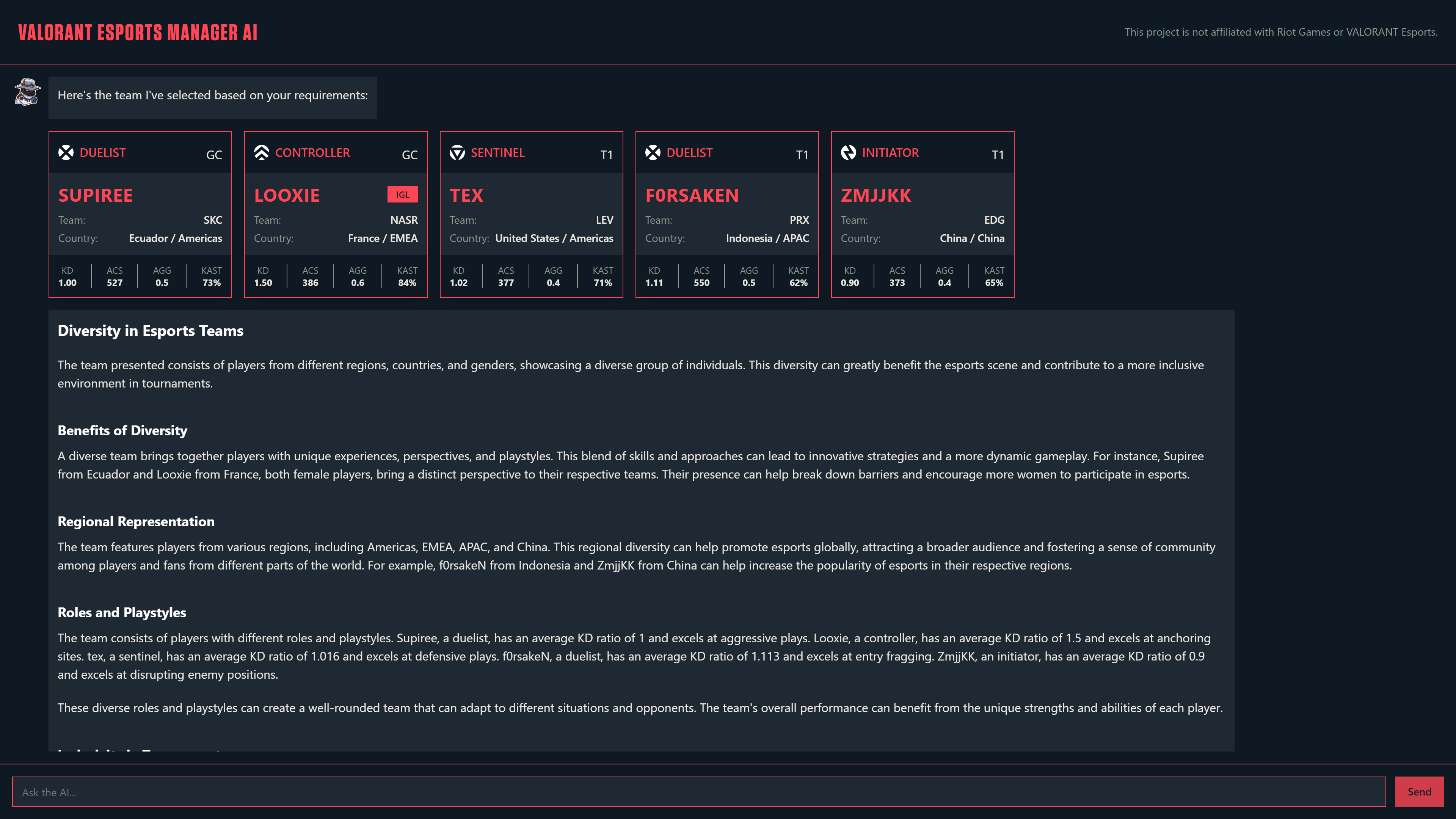
Response with Explaination as asked
-
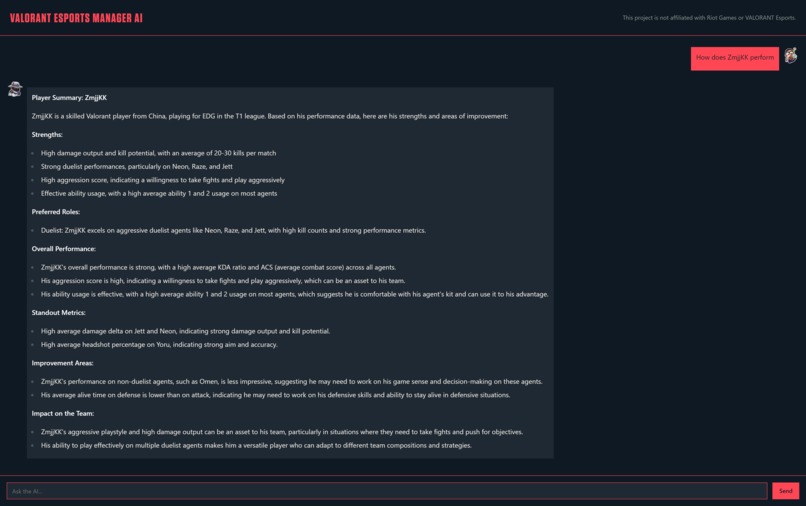
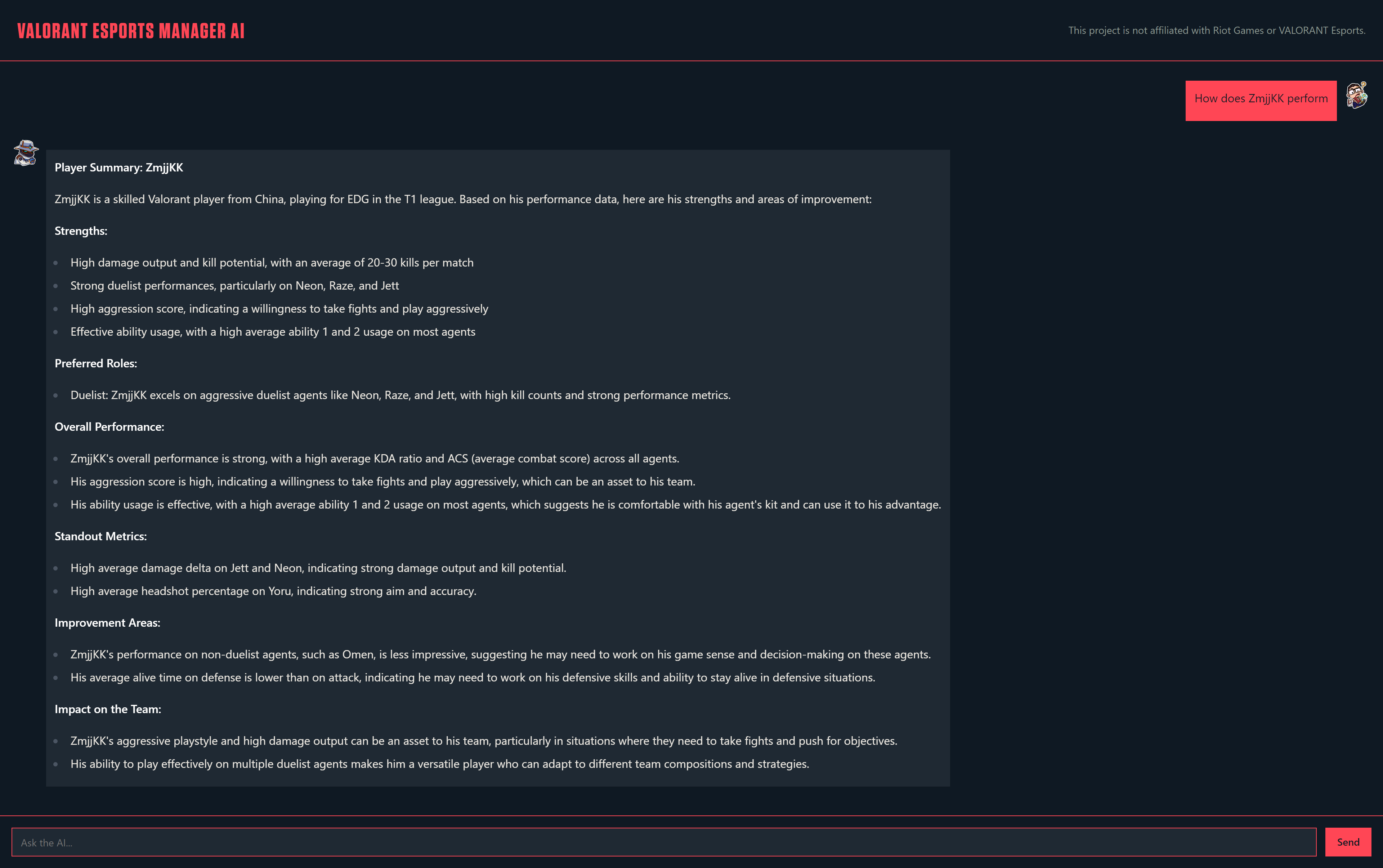
Player statistics & information
Our journey through this project was an interesting combination of data handling, model training, and the integration of various AWS services. We learned the importance of efficient data pipelines, the challenges of fine-tuning large language models (LLMs), and the necessity of custom classifiers to extract meaningful insights from raw data. This project reinforced our understanding of how to manage large datasets and optimize machine learning models for real-world applications.
Project Development
- Data Acquisition: We began by downloading esports data from S3 buckets provided by Riot Games. This data used on broadcast to power the HUD, so it had to be parsed and calculated heavily, which formed the backbone of our analysis.
- Initial Attempts at Model Fine-Tuning: Our first approach involved fine-tuning LLAMA 3 and Mistral models using the downloaded data. However, these attempts proved to be time-consuming and did not produce the desired accuracy. We realized that the raw data required significant preprocessing and enrichment to be useful for our purposes.
- Exploring AWS Bedrock: We then turned to AWS Bedrock’s Knowledge Base. While it offered powerful capabilities, it was not cost-effective for our needs. Additionally, we encountered issues with original repetitive and recursive data, which made it challenging to derive useful insights directly.
- Creating a Custom Data Pipeline: To address these challenges, we developed a custom pipeline to preprocess and structure the raw data. We extracted relevant information and stored it in a relational database (Postgres) for efficient querying. We also used a NoSQL database for more flexible data handling, allowing us to store complex player metrics and vectors.
- Developing Custom Classifiers: Recognizing the need for more detailed player insights, we built custom classifiers to categorize player play styles. These classifiers analyzed metrics such as aggression (Player is offensive or defensive on a spectrum), first kills and deaths, time alive on sides, plants, defuses, and KAST (Kill, Assist, Survive, Trade), KD, KDA ratios, HS% Number of kills, Assist by Damage or Ability, Ability & Ultimate Usage and more (over 25 custom classifiers). This step was crucial in enriching our dataset with new dimensions that could inform better decision-making.
- Backend Development: With our structured data in place, we leveraged AWS Bedrock and custom LLMs to develop the backend of our digital assistant. The backend was designed to interpret user inputs and generate structured JSON responses. These responses triggered specific functions to retrieve and process data from our databases.
- Implementing Team Composition Logic: One of the key features of our digital assistant was its ability to build optimal team compositions based on user requirements. We developed logic to parse user prompts, use the requirements to fulfill the queries to the database, and retrieve the best-suited players from our database. The selected players were then paired with explanations and additional details to create comprehensive responses.
- Frontend Development: For the frontend, we chose Next.js due to its performant API endpoints and React for the user interface. We used VALORANT's color scheme and branding to create an engaging and familiar user experience. This interface allowed users to interact seamlessly with the backend and receive immediate, insightful feedback. We also added a Morse code for the nerds as an Easter egg.
- Integration and Optimization: Ensuring seamless integration between the user interface, backend processing, and data retrieval was critical. We optimized our system to provide quick and accurate responses, ensuring that the digital assistant was both efficient and reliable in real-time scenarios.
- Hosting the Live Application: We hosted the database and the Next.js app on an EC2 machine, to reduce latency and containerize everything onto a single place and machine.
Interesting Things Added:
- Structured Responses from LLM : We made our prompts such that the LLM's respond in a certain manner, we added a lot of rules and formatting to make sure that the LLM understands and outputs the correct thing.
- Custom model for aggression score : We created a custom function that intakes' data like player location when died, where he got killed from, damage taken, damage give, time alive on sides, ability usage, distance from team, distance from bomb and many more parameters to calculate the player's aggression score from 0 to 1.
- Custom Pipeline to load and parse JSON : The Raw XML available through Riot had a lot of moving and repetitive parts, which needed to be effectively loaded and unloaded, along with parsing the data that required going back to round starts / reversing the parse to get some data for the preprocessing. As the XML files were pretty large, loading multiple into memory and processing seemed a difficult task, but we created a good measure with concurrency and were able to process the files from days at the start to minutes at the end.
- Easter Eggs : We added a few Easter eggs for anyone using the LLM, some more evidently visible than the others.
- Visuals from Valorant : We wanted to stay true to the Valorant theme and created a custom UI than going for a default chat template, along with some in-game assets.
Challenges Faced
- Model Fine-Tuning: Fine-tuning large language models required substantial computational resources and time, presenting a significant challenge in terms of efficiency and effectiveness.
- Cost Management: Utilizing AWS services necessitated careful budget management to avoid excessive costs while still leveraging their full capabilities.
- Data Processing: Cleaning and structuring the raw data was a labor-intensive process that required meticulous attention to detail.
- Performance Optimization: Balancing the need for quick response times with the complexity of the queries and data processing was a continual challenge.
Methodology & Tooling
By utilizing AWS Bedrock and custom LLMs, we created a digital assistant capable of efficient data retrieval and insightful analysis. The assistant was designed to build optimal team compositions, assign player roles, and provide strategic recommendations based on comprehensive data analysis.
Tools Used
- AWS Services: S3 for data storage, Bedrock for LLM integration, EC2 for hosting the application, RDS for hosting the Postgres database, DynamoDB for hosting the NoSQL Database and additional AWS tools for data processing and deployment.
- Databases: Postgres for relational data storage and MongoDB databases for flexible data handling.
- Frontend: Next.js and React with custom Tailwind & Animations to build a performant and visually appealing user interface.
- Backend: JavaScript functions with JSON to ensure seamless integration with the frontend and efficient data processing.
Built With
- amazon-web-services
- bedrock
- bedrock-for-llm-integration
- dynamodb
- ec2-for-hosting-the-application
- javascript
- llama
- mongodb
- next.js
- postgresql
- python
- rds
- rds-for-hosting-the-postgres-database
- tailwindcss


Log in or sign up for Devpost to join the conversation.