Inspiration We've all skipped customer discovery. It's slow, awkward, and easy to fake. You ask leading questions and hear what you want to hear. But The Mom Test nails it: people lie to be nice. The real problem isn't talking to users, it's getting the truth out of them and knowing what to do with it.
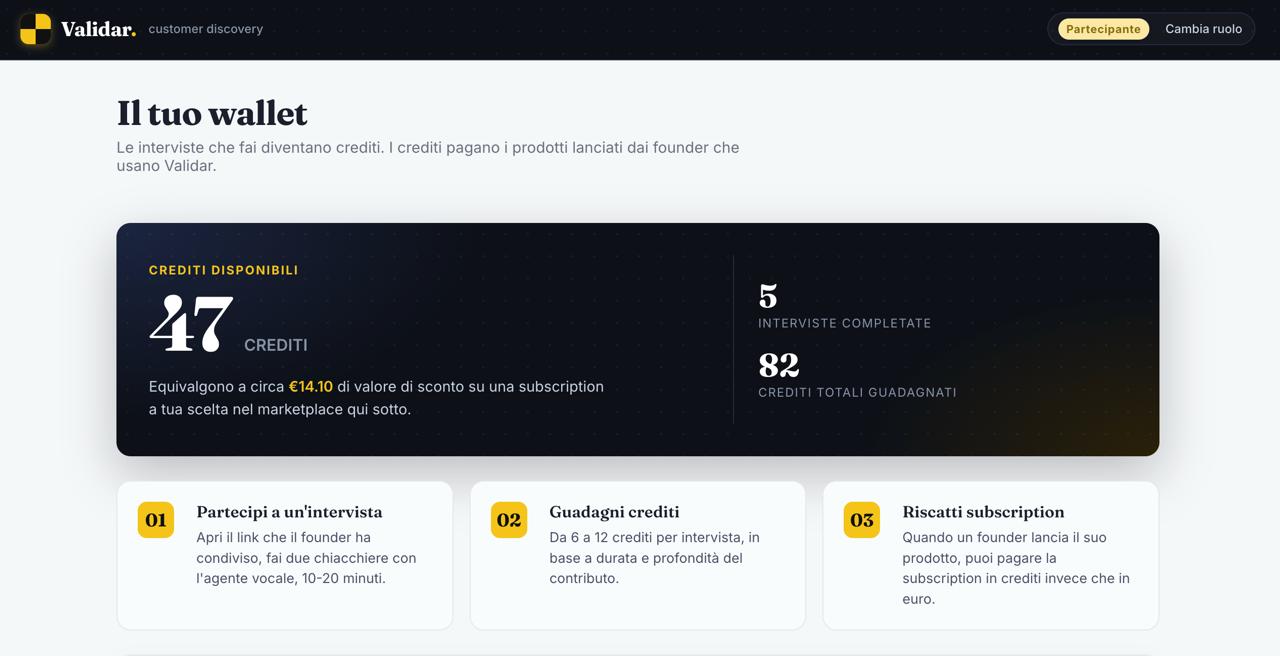
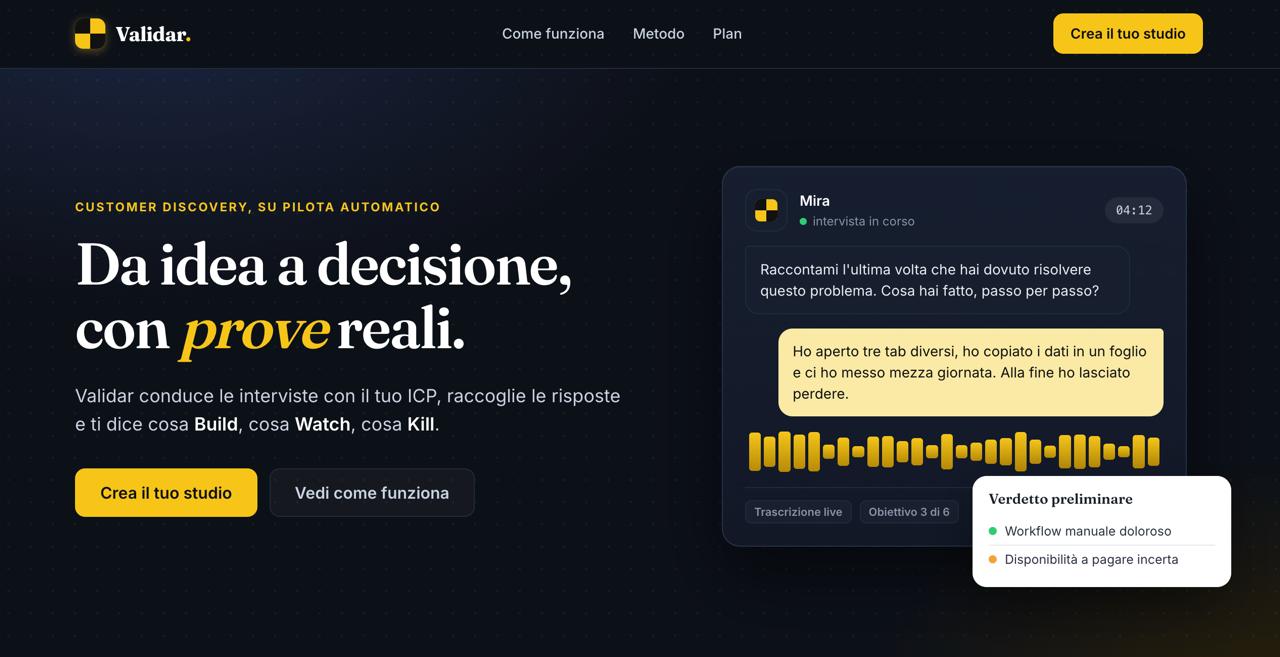
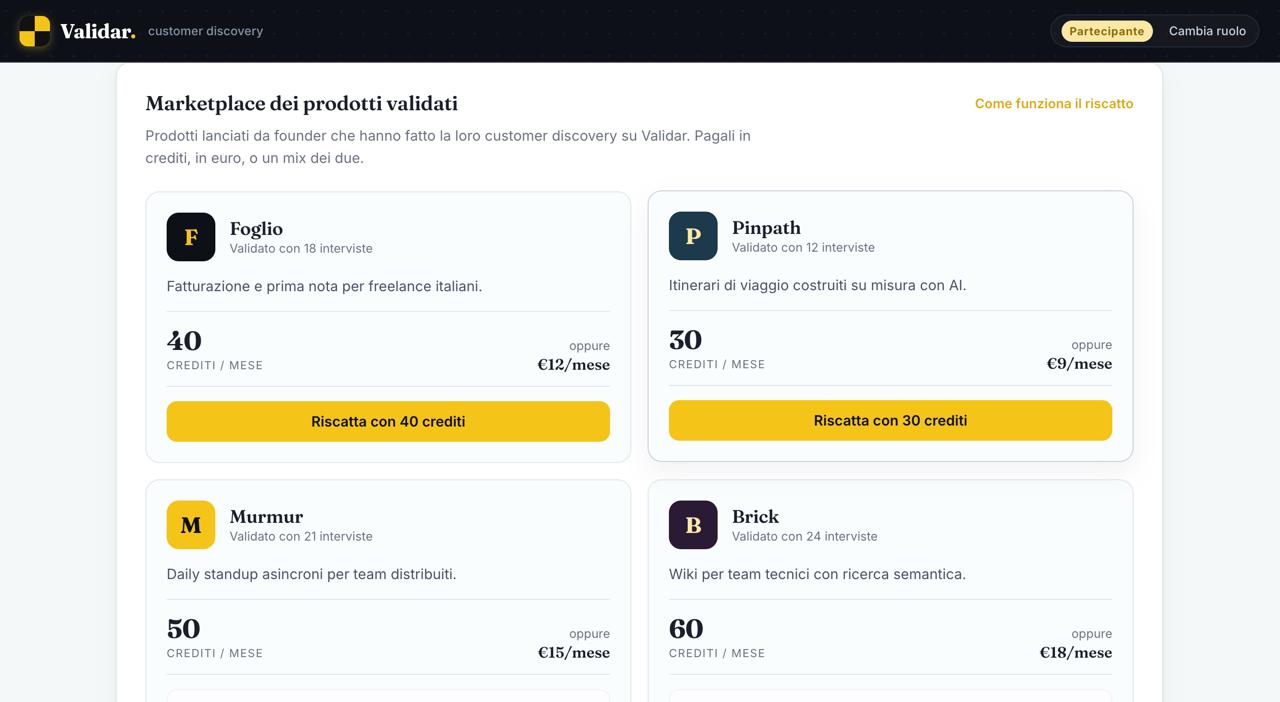
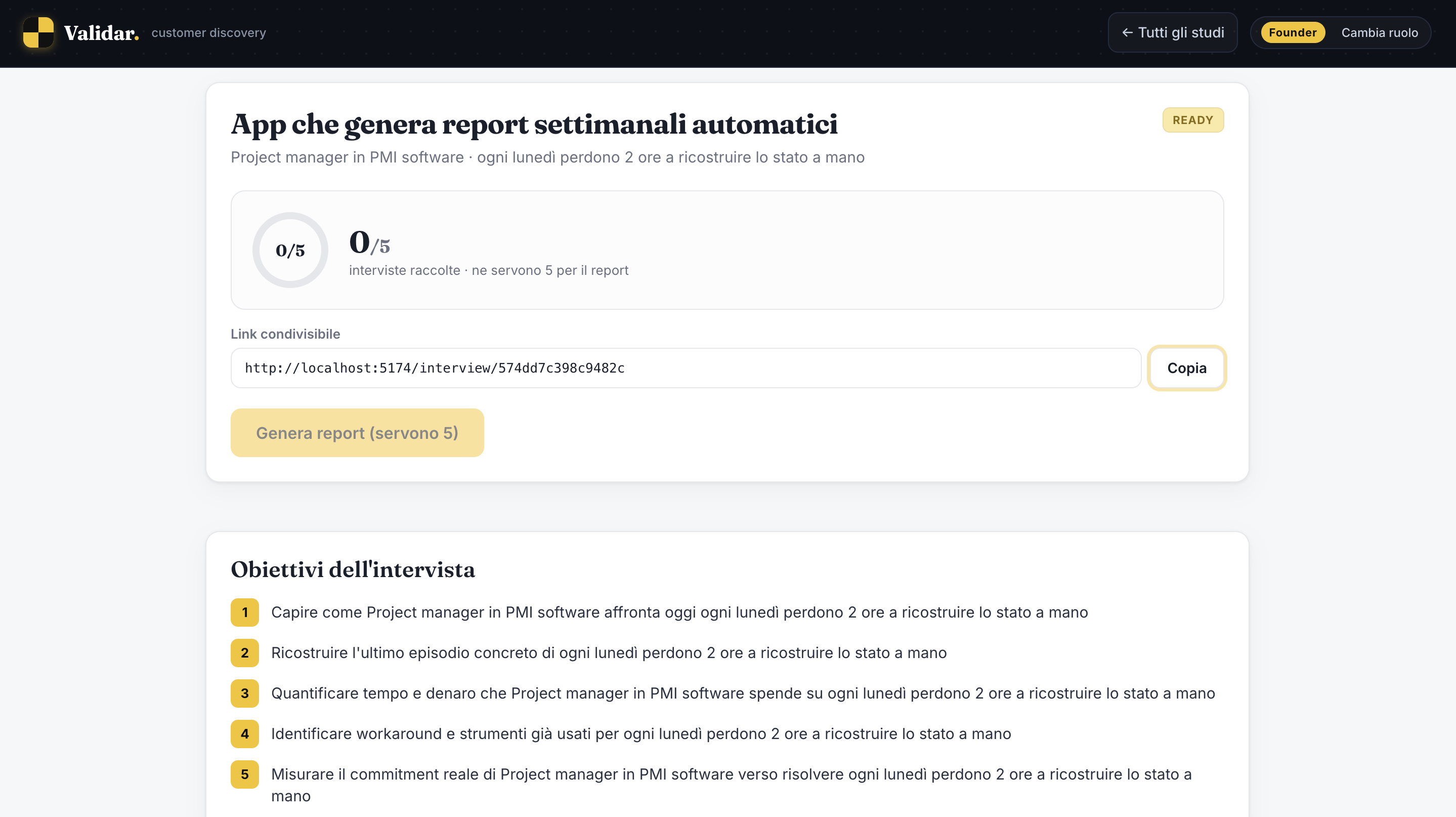
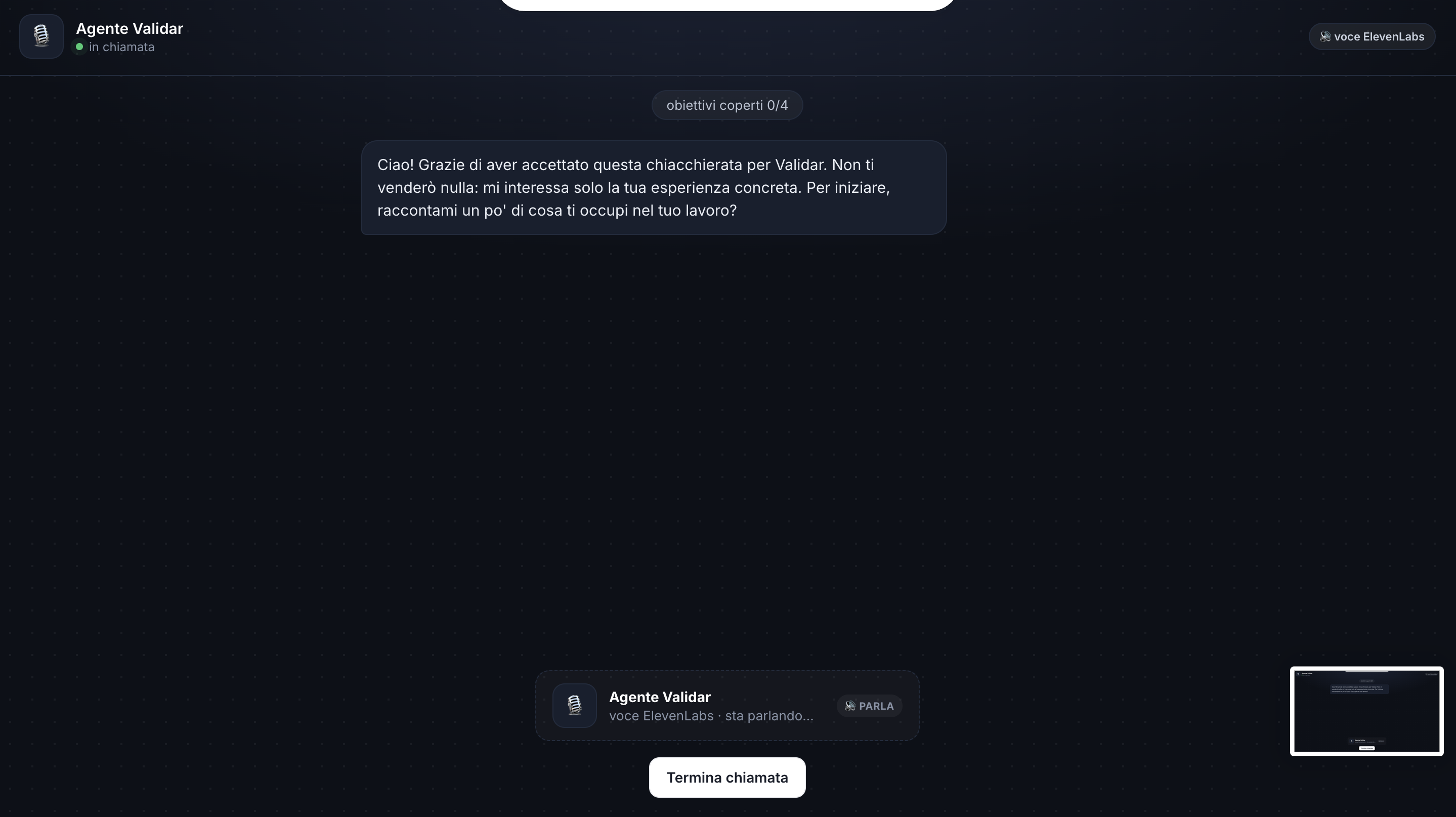
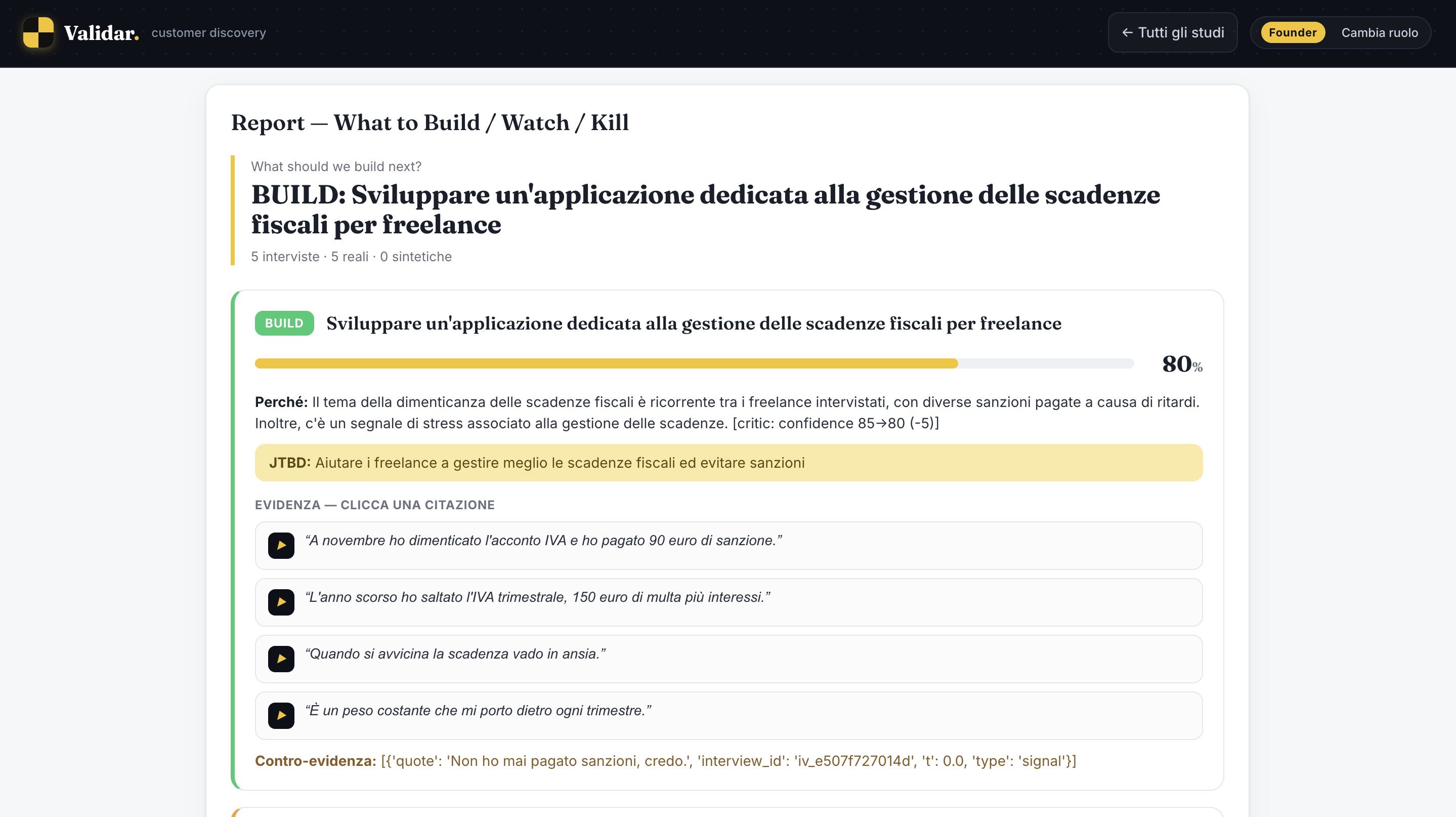
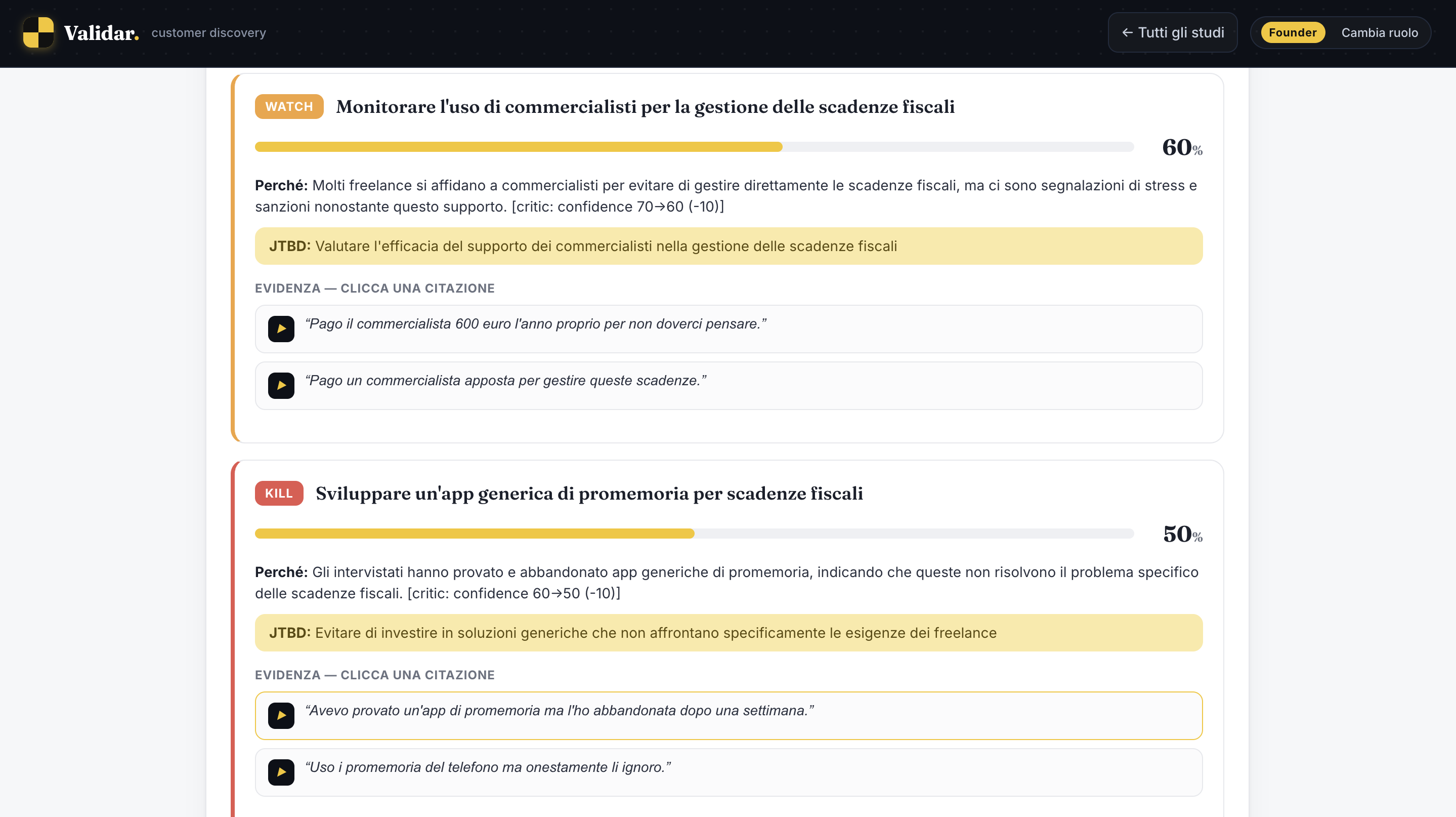
What it does You give Validar an idea and who it's for. An Interview Designer turns that into a Mom-Test discussion guide (objectives, seed questions, a probe tree) and spins up a specialized interviewer behind a shareable link. The respondent joins a real voice call: the agent runs the interview the right way, no pitching, digging into what they've actually done, like time, money, and real workarounds, while an objective tracker follows what's been covered. After five interviews, a multi-agent pipeline turns the conversations into a Build / Watch / Kill brief, with confidence scores and an evidence trail back to the exact words that justify each call.
How we built it Four of us, one idea that held everything together: keep the brain separate from the face. The face is an ElevenLabs voice agent handling speech-to-text and text-to-speech on a live WebRTC call. The brain is ours, a FastAPI backend wired in as ElevenLabs' custom LLM, so every question comes from our Mom-Test logic and not a generic model. That logic is a chain of agents on OpenAI: a response-analyzer that scores each answer and decides when to dig or move on, a question-generator bound by hard guardrails, then synthesis (signal extraction, JTBD mapping, pattern clustering, a decision engine, and an adversarial critic). The voice is just a shell, so the same agent re-specializes for any idea from the backend, keyed per study.
Challenges we ran into The hard part was never the code, it was getting four people to meet at one clean seam. So we froze the data contracts first, the transcript and the brief, and built against mocks until they merged. Then came wiring a live voice agent to think with our brain: an OpenAI-compatible endpoint, a tunnel, turn-taking that stays natural. The humbling moment was the first real call. It ran, but it interviewed badly, walking through questions in fixed order, ignoring answers, not screening the person. The fix wasn't plumbing. The LLM was only phrasing sentences while heuristics made every decision, so we had to put the model's judgment in command: screening against the ICP, choosing when to probe, deciding when the interview is genuinely done.
Accomplishments that we're proud of We got on a call and talked to it, out loud, and it ran a genuine discovery interview end to end (speech in, reasoning in the middle, speech out) then handed back a real decision instead of a pile of transcripts. And it's honest by construction: the critic's only job is to doubt the conclusion, and it can lower our confidence, never inflate it.
What we learned The model isn't the moat, the method is. Anyone can call an LLM; the value is codifying how to run discovery so the truth comes out. And an AI in the loop means nothing if it isn't the one making the call. A model that only phrases questions while heuristics decide produces an interviewer that doesn't listen.
What's next for Validar Every conversation makes it sharper. We're building toward a system that learns from each interview, a reinforcement loop over a proprietary dataset of how real people respond to nascent products, so that one day no one ships a product on a guess again, because the decision was made, not gambled. The infrastructure behind every product decision.
Built With
- elevenlabs
- fastapi
- ngrok
- openai
- pydantic
- python
- react
- sqlite
- typescript
- vite
- webrtc

Log in or sign up for Devpost to join the conversation.