-
-

Vaklab
-

Team
-

Opportunity
-
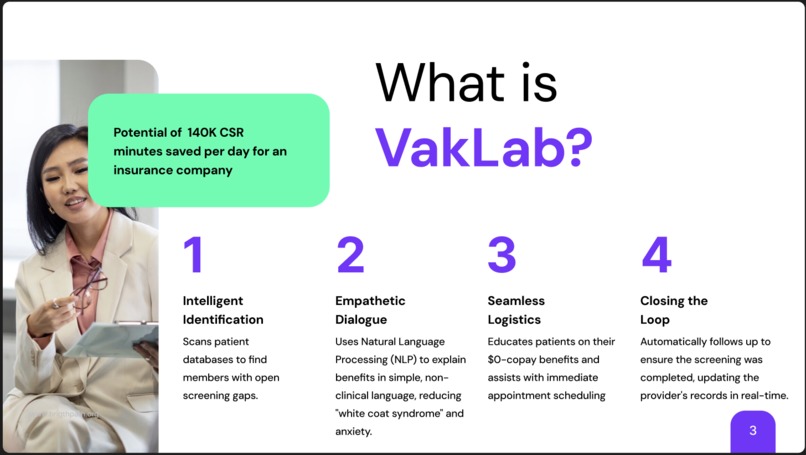
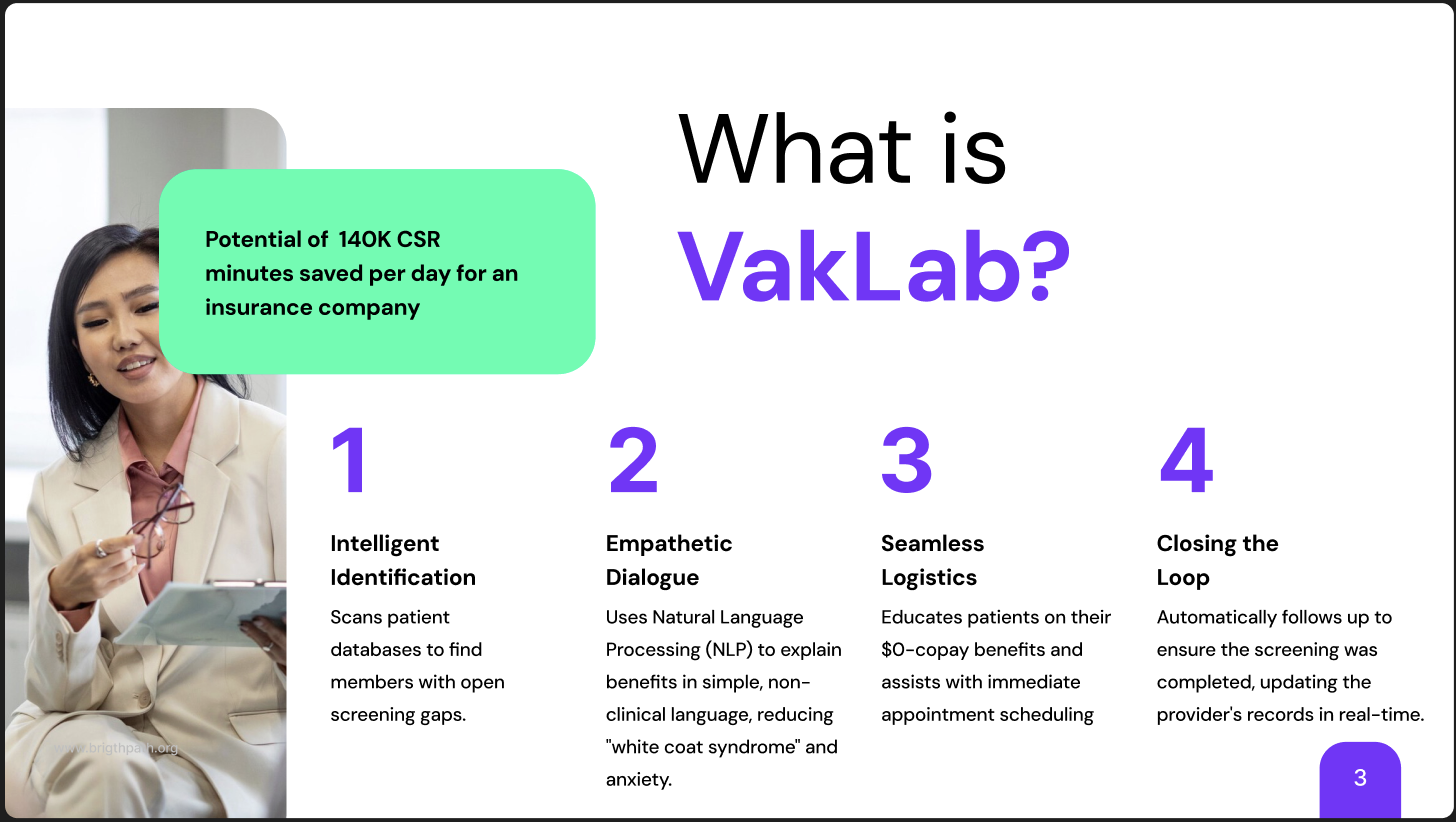
What is Vaklab
-
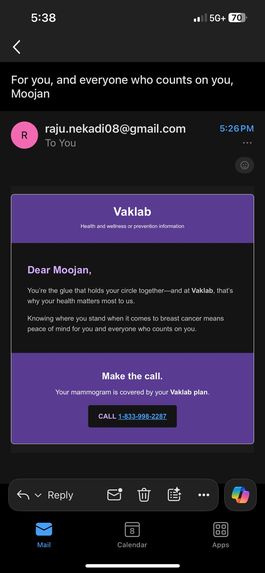
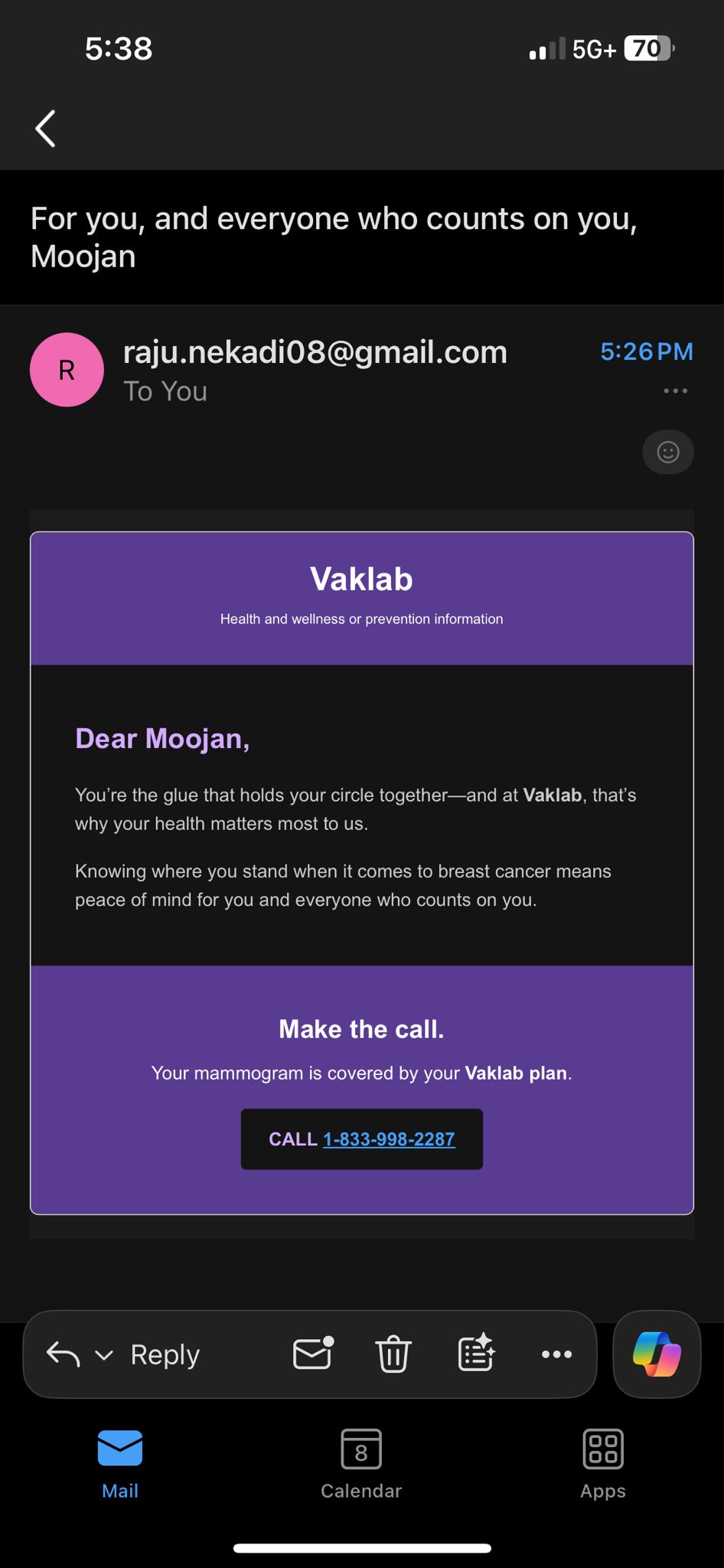
EmailScreen



Vaklab: AI-Powered Preventive Healthcare Outreach Agent
The Inspiration
VakLab started with a personal realization. Raju’s grandmother was diagnosed with breast cancer at 66, and her care team noted that regular screenings could have made a significant difference in her early treatment options and long-term health. It became clear that the challenge wasn't just the medical care itself, but ensuring patients have the information they need at the right time.
With over six years of experience leading call intelligence teams across several major healthcare organizations, Raju recognized that this wasn't an isolated incident; it was a systemic gap. He saw a recurring pattern where large-scale outreach programs—responsible for over 30 million preventative calls annually—were slowed down by administrative friction. In many cases, 1,200+ representatives would spend up to 5 minutes reviewing data for a call that lasted only 60 seconds.
Because the process was inefficient, the system struggled to keep up with the volume, meaning many patients—people like Raju's grandmother—didn't receive the timely outreach they deserved. Raju joined forces with his MBA classmates, Pete and Moojan, to create a system where no screening is missed simply because a patient felt overwhelmed or a process was too slow.
What It Does
VakLab is an AI-powered voice outreach agent designed to close HEDIS gaps with the empathy of a human and the efficiency of a machine.
Key Capabilities:
- Intelligent Identification: Scans patient databases to find members with open screening gaps.
- Empathetic Dialogue: Uses Natural Language Processing (NLP) to explain benefits in simple, non-clinical language, reducing "white coat syndrome" and anxiety.
- Seamless Logistics: Educates patients on their $0-copay benefits and assists with immediate appointment scheduling.
- Closing the Loop: Automatically follows up to ensure the screening was completed, updating the provider's records in real-time.
Impact & Efficency
We calculate the total daily operational capacity reclaimed ($C_r$) by measuring the time saved per call ($T_s$) across the total daily call volume ($V$). With VakLab, we save 7 minutes of total preparation and administrative work per call interaction.
$$ C_r = V \times T_s $$
$$ 20{,}000 \text{ calls} \times 7 \text{ minutes} = 140{,}000 \text{ minutes saved per day} $$
This allows the 1,200 reps to shift their focus away from manual data review and toward inbound calls and solving more complex patient queries that require a deep human touch.
Stars Incremental Value Breakdown (Preventive HEDIS Measures)
| Star Rating Improvement | Incremental Value Generated(Approx.) |
|---|---|
| 2★ → 3★ | ~$27.2M |
| 3★ → 4★ | ~$54.4M |
| 4★ → 5★ | ~$81.6M+ |
| Full Optimization (2★ → 5★) | $100M+ total impact at scale |
Interpretation:
- Each step-up in Star Rating delivers exponentially higher financial value
- Preventive HEDIS measures are key contributors.
- Consistently closing screening gaps compounds value across years
Vaklab transforms preventive care outreach into a scalable, AI-driven system that benefits members, health plans, and healthcare outcomes.
How We Built VakLab
We used Gemini to parse complex patient health records and generate concise, empathetic call scripts. This was integrated into a secure, HIPAA-compliant pipeline that handles voice synthesis with emotional prosody, ensuring the agent sounds supportive and professional.
Real-Time Voice Pipeline
┌─────────────────┐ ┌──────────────────────────────────────────────────────┐
│ │ │ Pipecat Pipeline │
│ Twilio │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌───────┐ │
│ Media Stream │◀───▶│ │ Google │──▶│ Gemini 3 │──▶│ Google │──▶│ Audio │ │
│ (WebSocket) │ │ │ STT │ │ LLM │ │ TTS │ │ Out │ │
│ │ │ └─────────┘ └─────────┘ └─────────┘ └───────┘ │
└─────────────────┘ └──────────────────────┬───────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Transcript Manager │
│ (Real-time WebSocket to UI) │
└──────────────────────────────────────────┘
│
┌──────────────────────┴───────────────────┐
▼ ▼
┌───────────────┐ ┌────────────────┐
│ Live UI │ │ PostgreSQL │
│ Dashboard │ │ (Call Logs) │
└───────────────┘ └────────────────┘
Evaluation Framework Flow
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────────────────┐
│ Conversation │ │ ADK Eval │ │ Evaluation Metrics │
│ Scenarios │────▶│ Runner │────▶│ ┌─────────────────────────┐│
│ (JSON) │ │ (User Sim) │ │ │ • Response Quality ││
└─────────────────┘ └──────────────────┘ │ │ • Tool Usage Quality ││
│ │ • Hallucination Check ││
│ │ • Custom Rubrics ││
│ └─────────────────────────┘│
└──────────────┬──────────────┘
│
▼
┌──────────────────┐ ┌─────────────────┐
│ PostgreSQL │◀──────────│ Eval Results │
│ (Eval Data) │ │ (Scores/Turns) │
└──────────────────┘ └─────────────────┘
Agent Tools & Services
┌──────────────────┐
│ Google ADK │
│ Agent (Rebecca) │
└────────┬─────────┘
│
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ send_email() │ │ end_call() │ │ transfer_to │
│ Enrollment │ │ Graceful │ │ _agent() │
│ Confirmation │ │ Termination │ │ Human Handoff │
└───────────────┘ └───────────────┘ └───────────────┘
Tech Stack
| Component | Technology |
|---|---|
| AI Agent | Google ADK + Gemini3.0 Flash |
| Telephony | Twilio Voice API |
| Backend | FastAPI (Python) |
| Database | PostgreSQL |
| Containerization | Docker Compose |
| Evaluation | ADK Eval Framework + Custom Rubrics |
Challenges We Faced
Challenge 1: Conversation Turn Extraction
Problem: The ADK CLI outputs evaluation results, but conversation turns weren't being captured out database.
Solution: We discovered ADK stores detailed eval history in JSON files:
agents/outbound_agent/.adk/eval_history/*.evalset_result.json
We wrote a parser to extract user_content, final_response, and tool_calls from each invocation and store them in PostgreSQL.
Challenge 2: Vertex AI Credentials for Safety Metrics
Problem: The safety_v1 metric requires Google Cloud credentials:
ERROR: Missing project id.
This metric uses Vertex Gen AI Eval SDK...
Workaround: For local development, we focused on custom rubrics while setting up proper GCP authentication for production.
Challenge 3: Balancing Conversational Warmth with Efficiency
Problem: Too friendly = long calls and annoyed members. Too efficient = cold, robotic.
Solution: We tuned the agent to:
- Keep responses under 2-3 sentences
- Use encouraging phrases ("Great question!")
- Pause for natural conversation rhythm
Challenge 4: Email Timing Logic
Problem: The agent would sometimes send emails before the user confirmed interest.
Solution: Added explicit rubric checking:
{
"rubric_id": "email_after_confirmation",
"criteria": "The agent MUST wait for verbal confirmation before sending the enrollment email"
}
What We Learned
1. Prompt Engineering for Empathy
Getting an AI to sound genuinely caring — not robotic — required extensive prompt tuning:
❌ "I am calling to inform you about your mammogram screening benefit."
✅ "Hi! I hope I caught you at a good time. I have some great news about your health benefits!"
2. Handling Edge Cases Gracefully
Real conversations are messy. Users might:
- Say "not now" (agent must offer to call back)
- Ask unexpected questions ("Is this a scam?")
- Give one-word answers ("No", "Maybe")
We learned to design the agent to handle ambiguity without breaking the flow.
3. Evaluation-Driven Development
Writing evaluation scenarios before finalizing the agent helped us:
- Define clear success criteria
- Catch regressions early
- Quantify improvements objectively
Results
After multiple iterations of our evlauation framework, our agent achieved:
| Metric | Score | Threshold |
|---|---|---|
| Hallucinations | 0.85 | 0.8 ✅ |
| Response Quality | 0.79 | 0.7 ✅ |
| Tool Use Quality | 1.0 | 0.8 ✅ |
| Overall | 0.76 | 0.7 ✅ |
Future Enhancements
- Turn Key Solution : One-click deployment for healthcare organizations
- Agent Latency : Focus on Improving Agent Latency using better model or Using BidiStreaming Gemini Live API
- Multi-language Support : Spanish, Vietnamese, Mandarin
- Callback Scheduling : Integrate with calendar APIs
- A/B Testing :Compare different conversation scripts
- Real-time Dashboard : Live visualization of call outcomes
Acknowledgments
- Google ADK Team — For the powerful agent development framework
- Twilio — For reliable telephony infrastructure
- Open Source Community — For FastAPI, PostgreSQL, Pipecat and Docker
Built with ❤️ for the GCP Hackathon 2026
Built With
- adk
- docker
- gcp
- pipecat
- postgresql
- python
- twilio

Log in or sign up for Devpost to join the conversation.