-
-
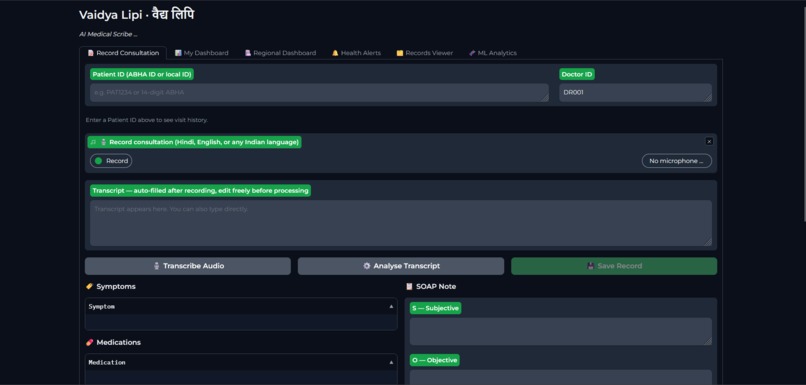
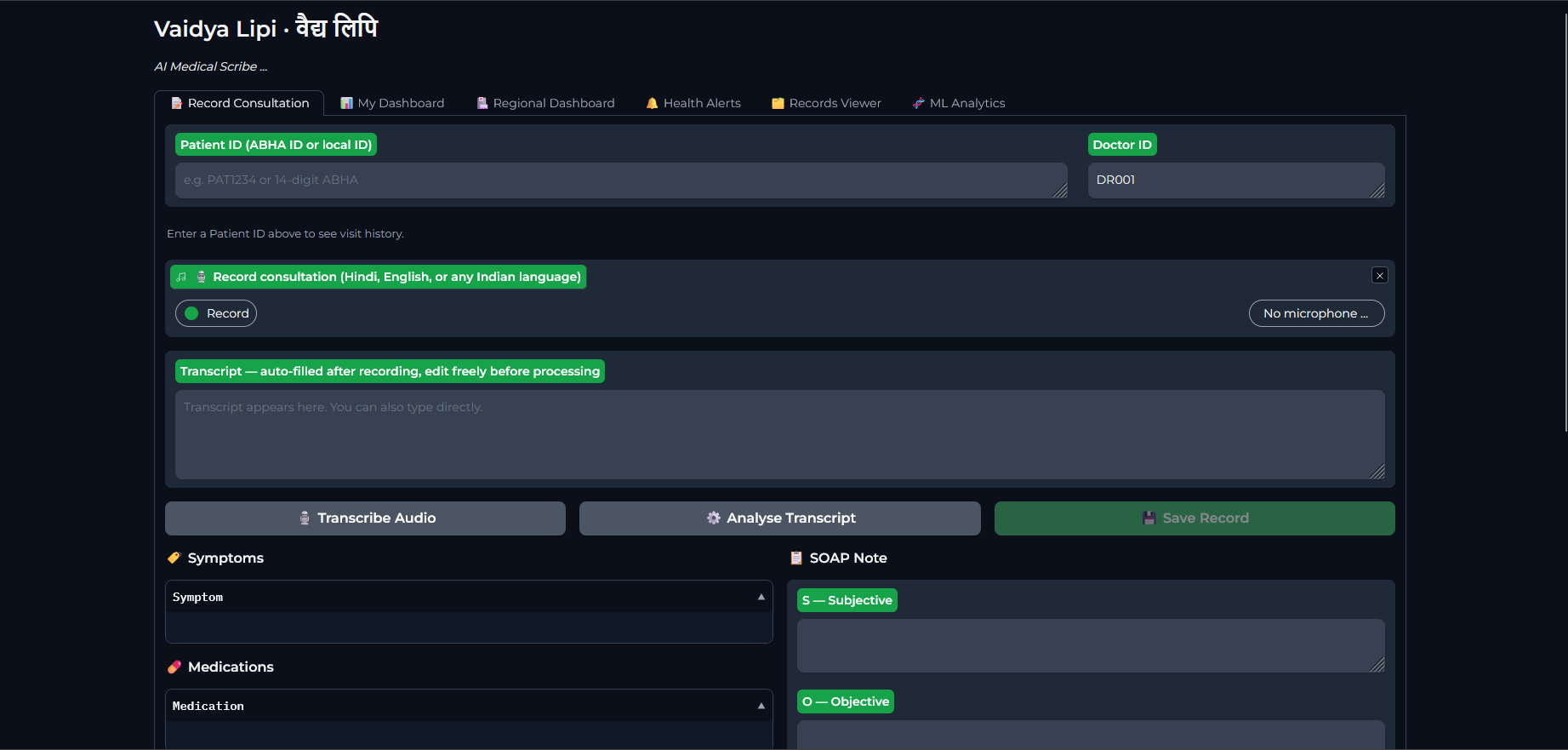
Entry page
Inspiration
We were inspired by the series The Pitt, it is about daily lives of healthcare professionals in a Pittsburgh hospital as they juggle personal crises, workplace politics, and the emotional toll of treating critically ill patients, revealing the resilience required in their noble calling. We saw doctors charting the data using application like the one we tried to develop.
What it does
Vaidya Lipi is an AI-powered clinical scribe designed specifically for the Indian healthcare ecosystem, capable of converting multilingual doctor–patient conversations—across Hindi, English, and other Indic languages using Sarvam Saaras v2—into structured SOAP notes. It ensures interoperability by aligning with SNOMED-CT standards, addressing the major challenge of unstructured digital health data in India and contributing to improved patient care and public health outcomes. The platform significantly reduces physician burnout by automating clinical note-taking, allowing doctors to focus more on patient interaction; users simply enter patient and doctor IDs and record the consultation to generate structured documentation. Built on the Databricks Lakehouse architecture with Unity Catalog and Delta Lake, it provides secure data storage and supports large-scale health analytics aligned with the Ayushman Bharat Digital Mission (ABDM). The system processes data through the Llama 4 Maverick gateway to produce accurate SOAP-formatted clinical records, which are then presented on an intuitive clinician dashboard. Additionally, it includes a regional analytics dashboard for hospital administrators and a health alert tracking system that analyzes trends in recent conversations to provide early insights into potential disease outbreaks and broader public health patterns.
How we built it
We implemented Vaidya Lipi using a hybrid architecture that combines high-performance cloud infrastructure with efficient local processing, ensuring reliability even in resource-constrained environments. Databricks played a central role in the system: Databricks Apps were used to host and deploy the Gradio-based doctor interaction interface, while Unity Catalog and Delta Lake enabled secure and scalable storage of patient records and health analytics data. Databricks Vector Search was utilized for efficient medical entity retrieval and SNOMED tag matching, and Model Serving was used to host the Llama-4-Maverick endpoint for structured clinical reasoning. PySpark was employed to build real-time analytics dashboards and process large public health datasets such as HMIS and NFHS, while Volumes were used to store model weights and FAISS indexes. On the modeling side, we integrated a mix of open-source and API-based tools: Llama-4-Maverick served as the primary LLM for generating structured SOAP notes, Sarvam Saaras API enabled multilingual speech-to-text across Hindi, English, and other Indic languages, and Parrotlet-e was used for medical entity extraction. For embeddings, we chose the lightweight all-MiniLM-L6-v2 model for its speed and efficiency on CPU-based systems, and FAISS was used as the underlying library for building and querying the vector index.
Challenges we ran into
We faced our 1st challenge at the very first step, that is obtaining data and how do we use that data to process conversations. We struggled with deciding which models to use for our project, since we were limited to free edition of databricks, we only had CPU compute at our hands so we could not try running something heavy on the platform. We went for using external API for all heavy AI lifting stuff. Deciding the architecture for the hackathon was a major challenge, how do we process the data, how will be check for symptoms, how can we minimize the compute provided given constraints.
Accomplishments that we're proud of
We were able to come up with a final architecture and full ideate our problem statement well and also implement it by integrating databricks, external open source models and different functionalities. We successfully integrated Databricks for data processing, storage, and deployment, while combining it with external open-source models for embeddings and response generation. One of our key achievements was building a working RAG pipeline. We also managed to structure the system in a scalable way, ensuring that each component (data, retrieval, and application layer) works seamlessly together.
What we learned
Through this project, we gained a strong understanding of how real-world AI systems are built beyond just models. We learned how to handle unstructured data, convert it into embeddings, and use vector search for meaningful retrieval. Working with Databricks helped us understand how data engineering, machine learning, and deployment come together in a unified platform. We also explored integrating external APIs and models, managing secrets securely, and dealing with system-level issues like data pipelines and environment setup. Most importantly, we learned how to design a complete system from scratch and debug it step-by-step.
What's next for Vaidya Lipi
Going forward, we plan to improve the accuracy and reliability of the system by using better domain-specific models and larger datasets. We also aim to enhance the user experience by building a more intuitive and responsive interface. Another key focus will be expanding the system to support multilingual queries and more complex medical use cases. Additionally, we want to optimize performance and scalability so the application can handle real-world usage. Ultimately, the goal is to evolve Vaidya Lipi into a practical tool that can assist users in accessing and understanding medical information efficiently.
Built With
- a
- and
- apps
- databricks
- databricks-hosted-llms-(llama-4-maverick)-for-ai-reasoning
- deployed
- faiss-for-vector-search
- github
- gradio-based
- leveraging-spark-and-delta-lake-for-data-processing-and-storage
- ui
- using
- we-built-the-system-using-python-on-databricks
- with

Log in or sign up for Devpost to join the conversation.