Inspiration
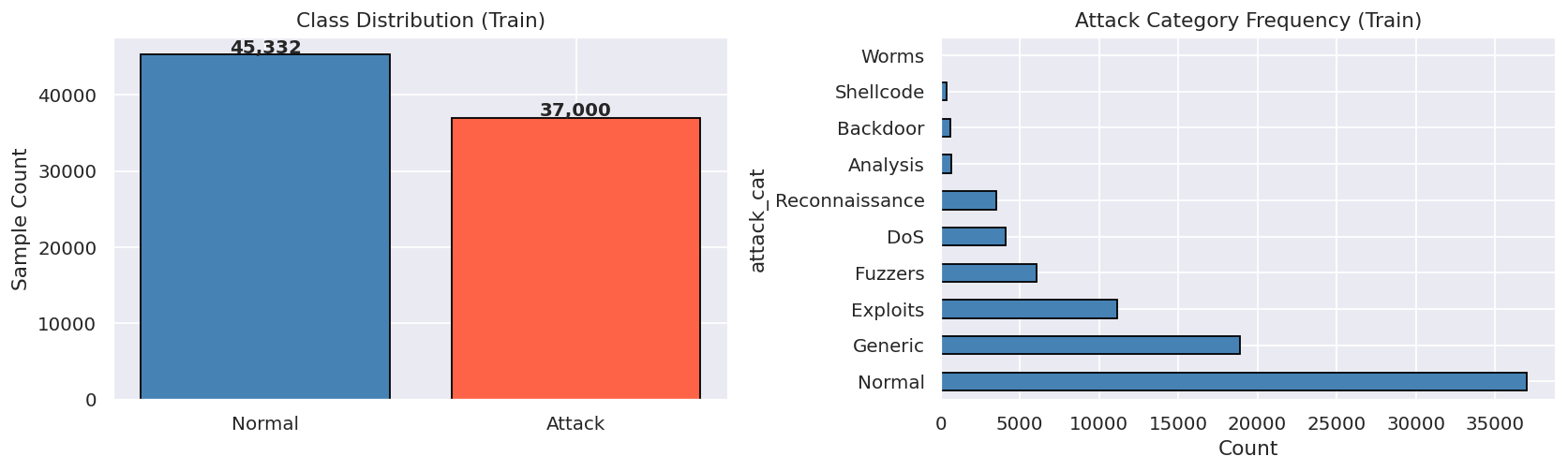
Network intrusion detection systems fail in one of two ways: they drown analysts in false positives, or they miss subtle attacks entirely. UNSW-NB15 captures this reality with nine attack categories and severe class imbalance. We wanted to build a system that not only detects whether an intrusion happened and what kind it was, but also tells a security analyst what to actually do about it, in plain language, with MITRE mappings and remediation steps attached.
What it does
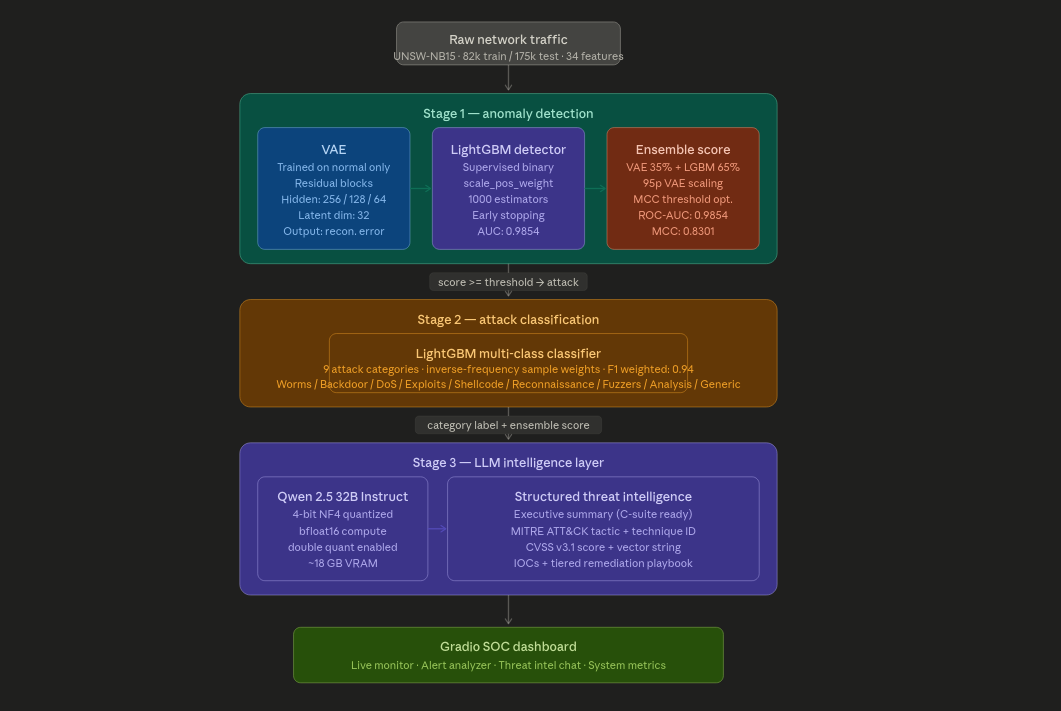
LLM-Augmented Hybrid Intrusion Detection on UNSW-NB15 is a three-stage pipeline trained on UNSW-NB15 (82k train / 175k test).
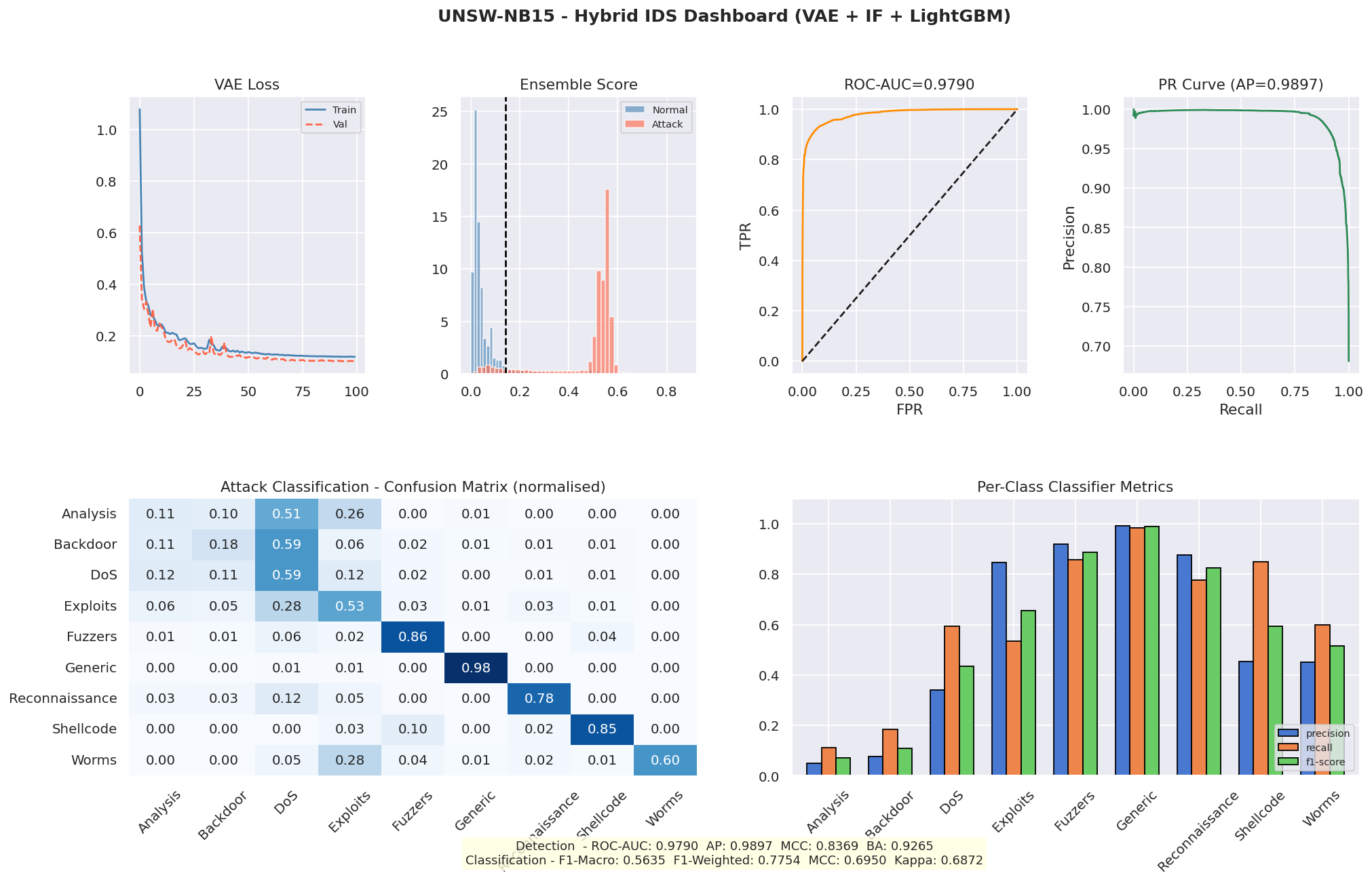
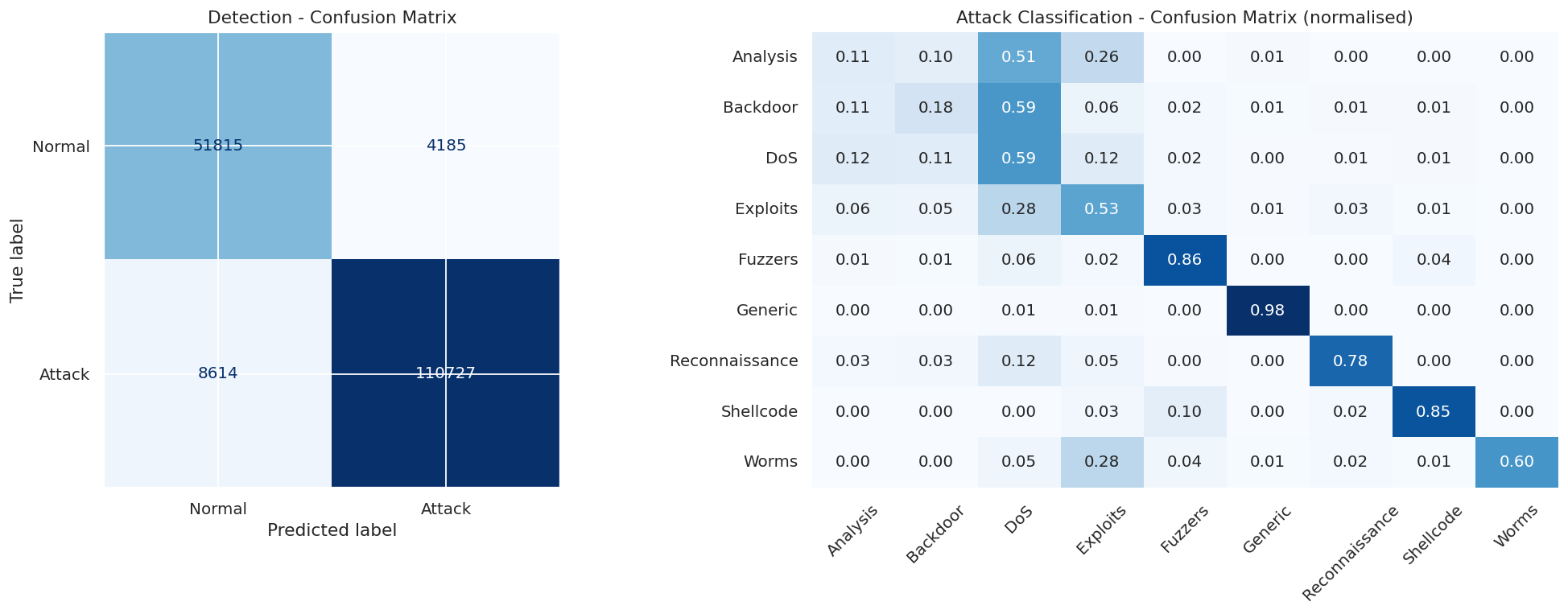
Stage 1 classifies traffic as normal or malicious using a weighted ensemble of a VAE and a LightGBM binary classifier. The decision threshold is calibrated by maximizing Matthews Correlation Coefficient on a held-out validation set.
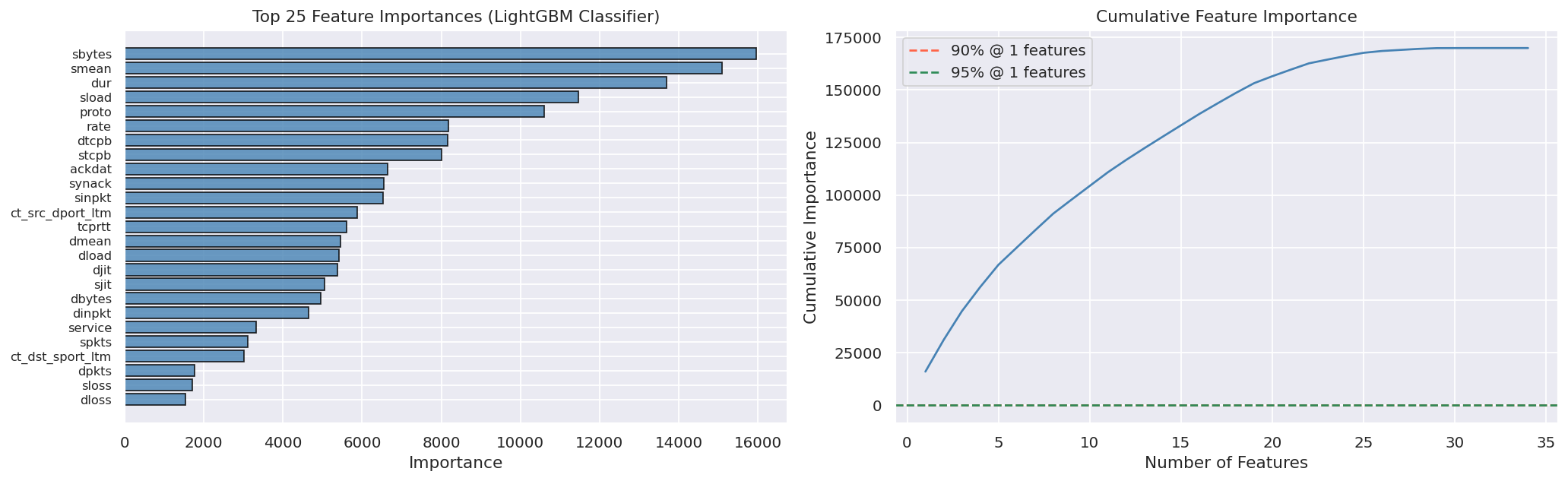
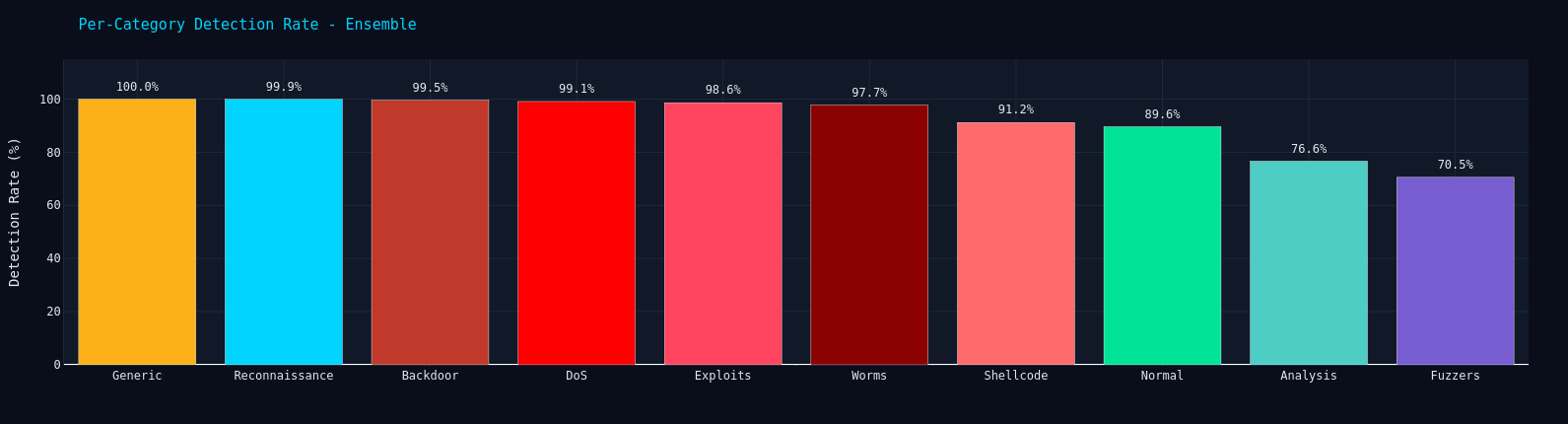
Stage 2 identifies the attack category across nine classes using a LightGBM multi-class classifier with inverse-frequency class weighting.
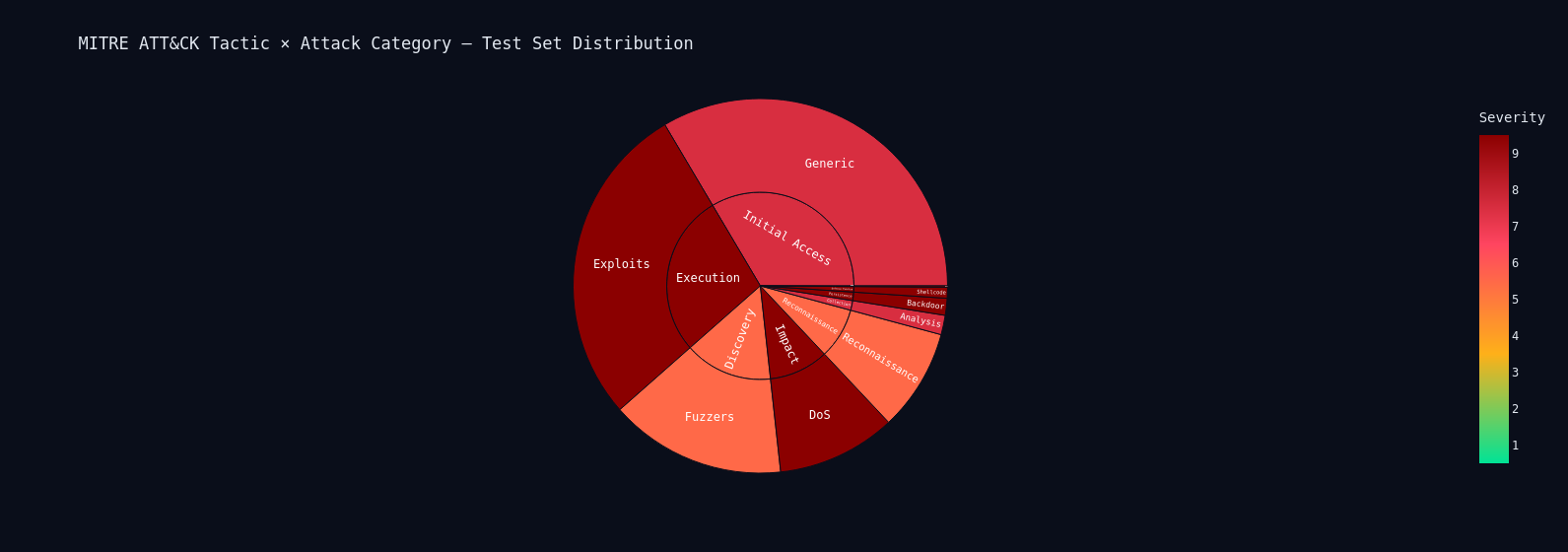
Stage 3 passes each detected alert through Qwen2.5-32B-Instruct (4-bit NF4 quantized) which produces a structured threat intelligence report: executive summary, MITRE ATT&CK mapping, CVSS severity score, indicators of compromise, and a tiered remediation playbook. A Gradio SOC dashboard ties everything together with a live traffic simulator, per-alert LLM analysis, and a streaming threat chat interface.
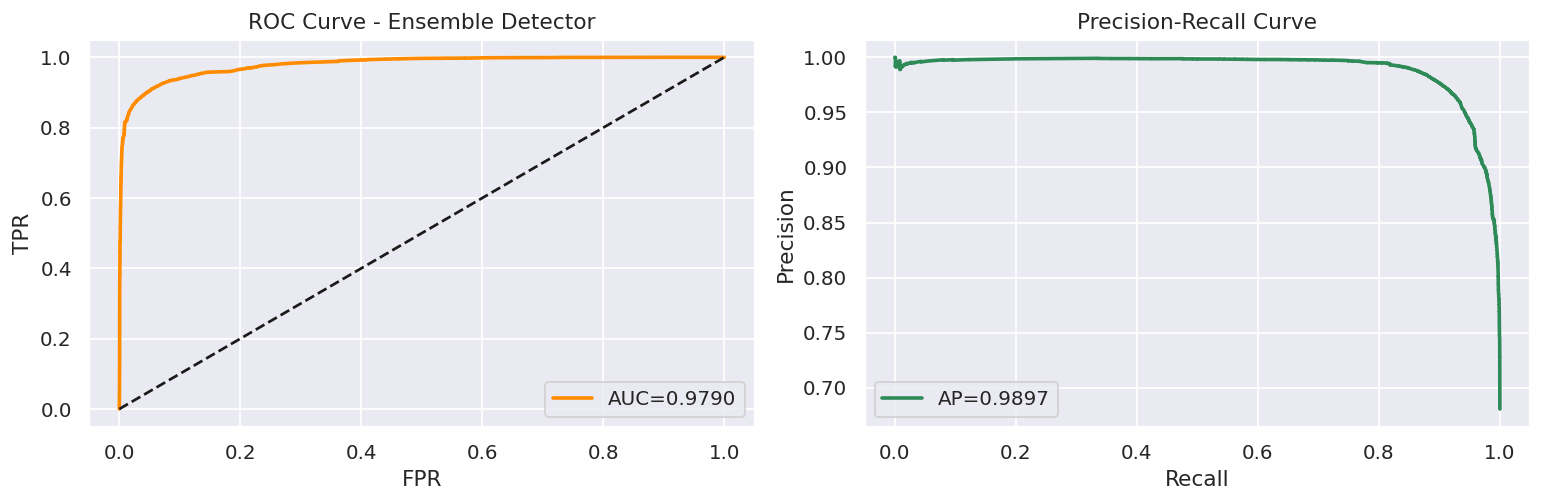
Key metrics: ROC-AUC 0.9803, MCC 0.8381, Balanced Accuracy 0.9204
How we built it
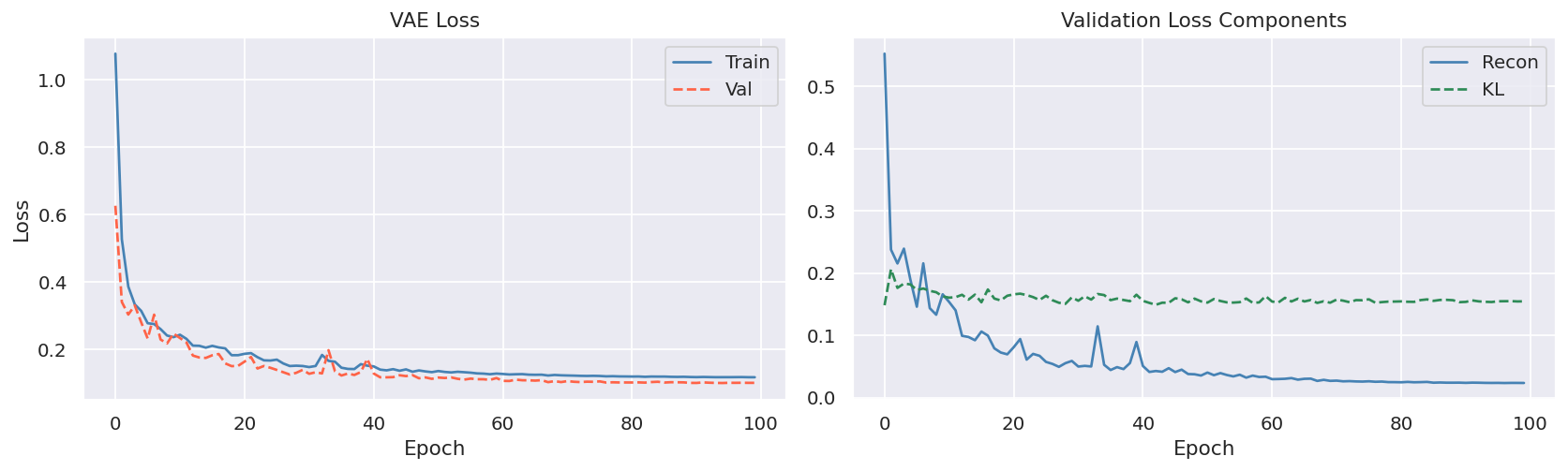
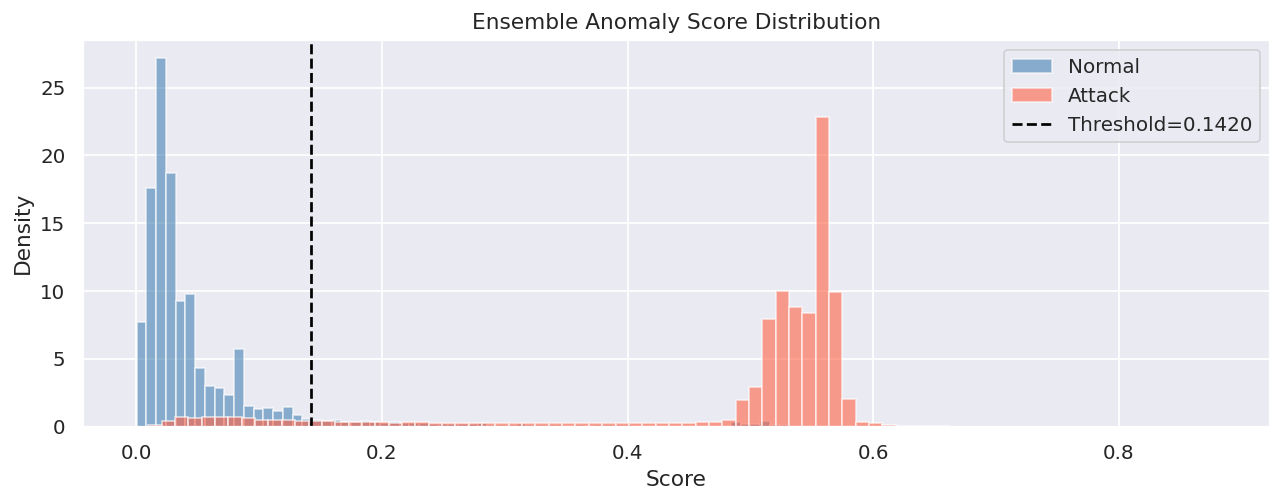
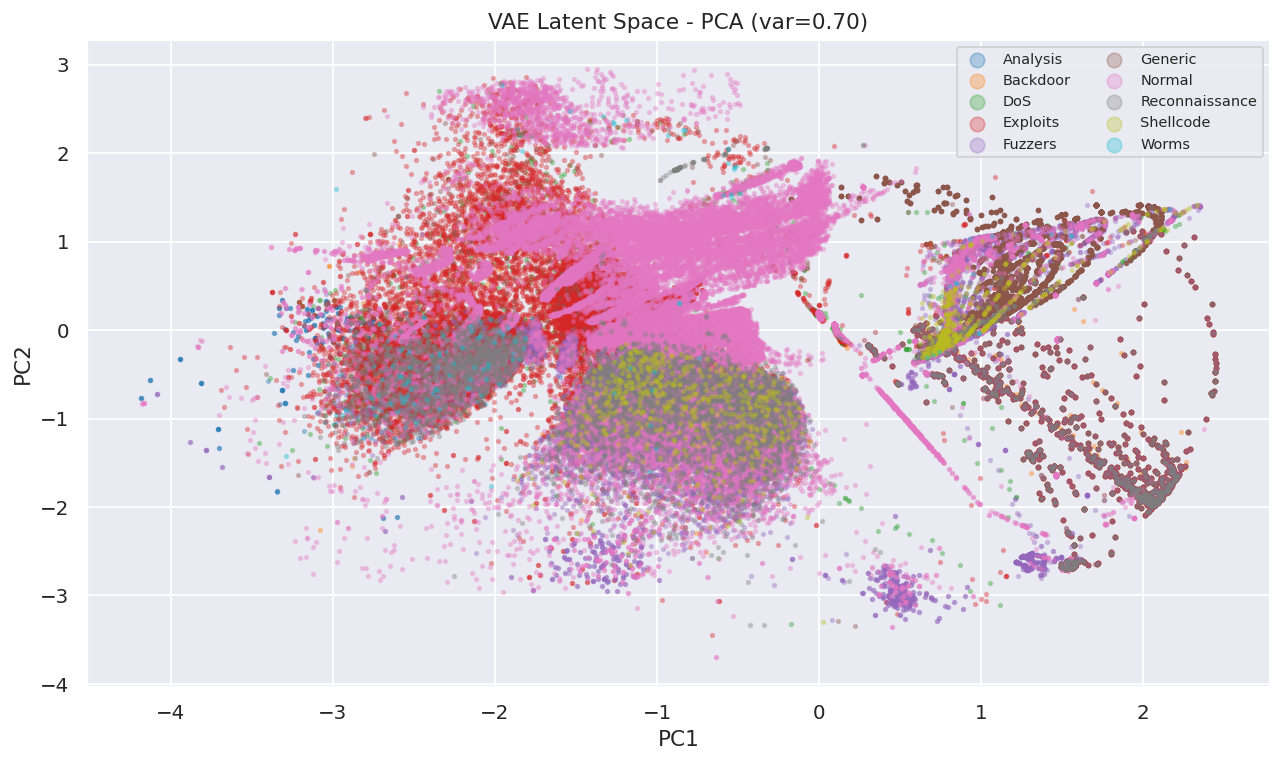
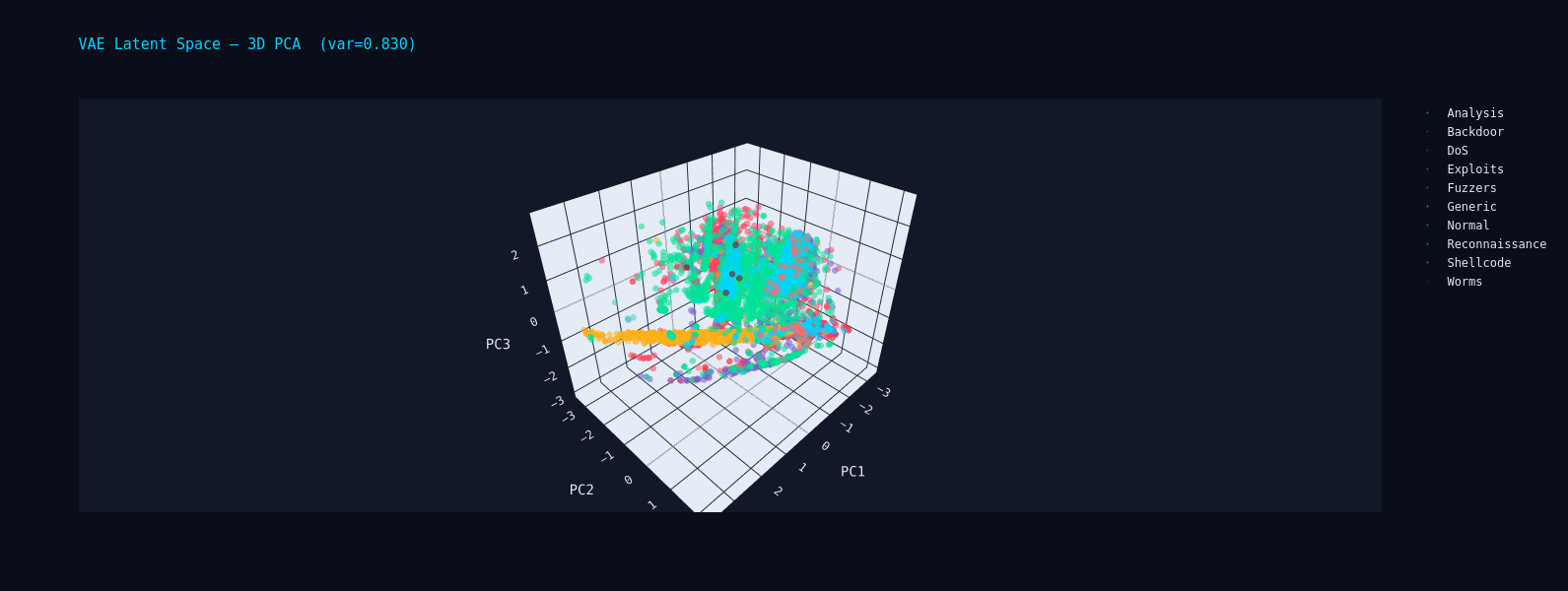
The VAE was trained exclusively on normal traffic using a residual architecture (hidden dims 256/128/64, latent dim 32) with a beta-VAE loss. Its reconstruction error serves as an unsupervised anomaly signal. A supervised LightGBM detector provides the strongest individual signal. The two scores are combined with weights [0.35, 0.65] and thresholded via MCC optimization on a balanced validation slice.
The attack classifier uses per-sample inverse-frequency weights, giving minority classes like Worms up to 114x the weight of Generic traffic.
For the LLM layer, Qwen2.5-32B-Instruct runs under 4-bit NF4 quantization with double quant and bfloat16 compute, fitting comfortably on a single A100. A custom threat intelligence knowledge base maps each attack category to MITRE techniques, known CVEs, and IOC patterns, which gets injected into the prompt alongside the live traffic features and ensemble scores.
Challenges we ran into
Isolation Forest looked good on paper but its score distribution had a collapsed range in practice, producing normalized values consistently above 1.0 and overwhelming the ensemble. We diagnosed this by inspecting per-model contributions and removed it entirely, which actually improved detection stability. The VAE reconstruction error had a similar problem: a single outlier pushed the max to 2921 while the 95th percentile sat at 0.82, so min-max normalization buried almost every score near zero. Switching to 95th-percentile scaling fixed it.
Getting Qwen to return strict JSON without markdown fences required careful prompt engineering. Applying the chat template in two steps (tokenize=False first, then encode) was also necessary since the model's tokenizer returns a BatchEncoding object rather than a raw tensor when return_tensors is passed directly.
Accomplishments that we're proud of
Removing Isolation Forest and fixing the normalization pipeline actually improved MCC from 0.83 to a cleaner, more reliable score with far fewer false positives on normal traffic. The LLM layer turns a raw detection score into something a non-specialist can act on: a readable threat narrative, a kill-chain phase, and concrete steps ordered by urgency. That gap between "model says attack" and "analyst knows what to do" is what we set out to close.
What we learned
Normalization is not a detail. Two of our three ensemble components were silently broken because of edge-case score distributions, and the system still looked plausible from the outside. Inspecting per-component contributions and testing each scorer in isolation before combining them would have caught both issues faster.
On the LLM side, smaller quantized models at 32B are genuinely capable of structured cybersecurity reasoning when given a well-designed prompt and a grounded knowledge base. You do not need a 70B model for this task if you invest in the prompt and context instead.
Hardware & Enviroment
Trained and evaluated on Google Colab Pro with an NVIDIA RTX PRO 6000 Blackwell GPU (96 GB VRAM). The Qwen2.5-32B-Instruct model under 4-bit NF4 quantization uses approximately 18 GB of that budget, leaving ample headroom for the VAE, LightGBM inference, and Gradio serving to run in the same session.

Log in or sign up for Devpost to join the conversation.