-
-
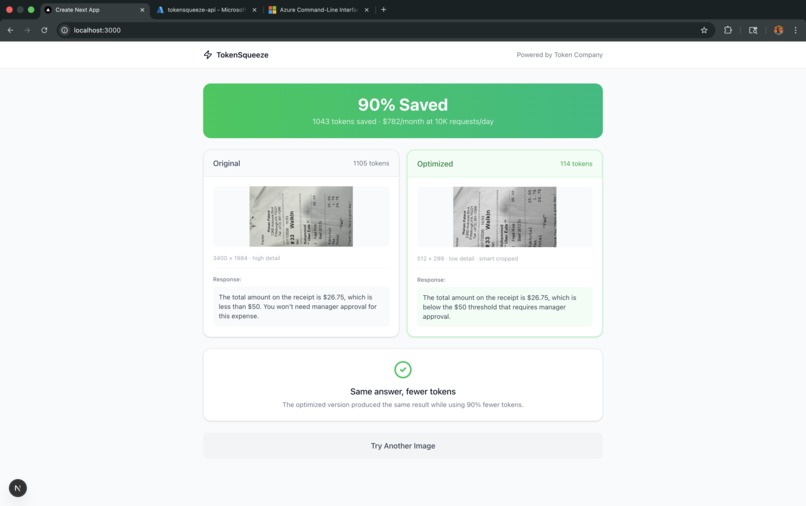
Image Optimization
-
Prompt Optimization
Inspiration
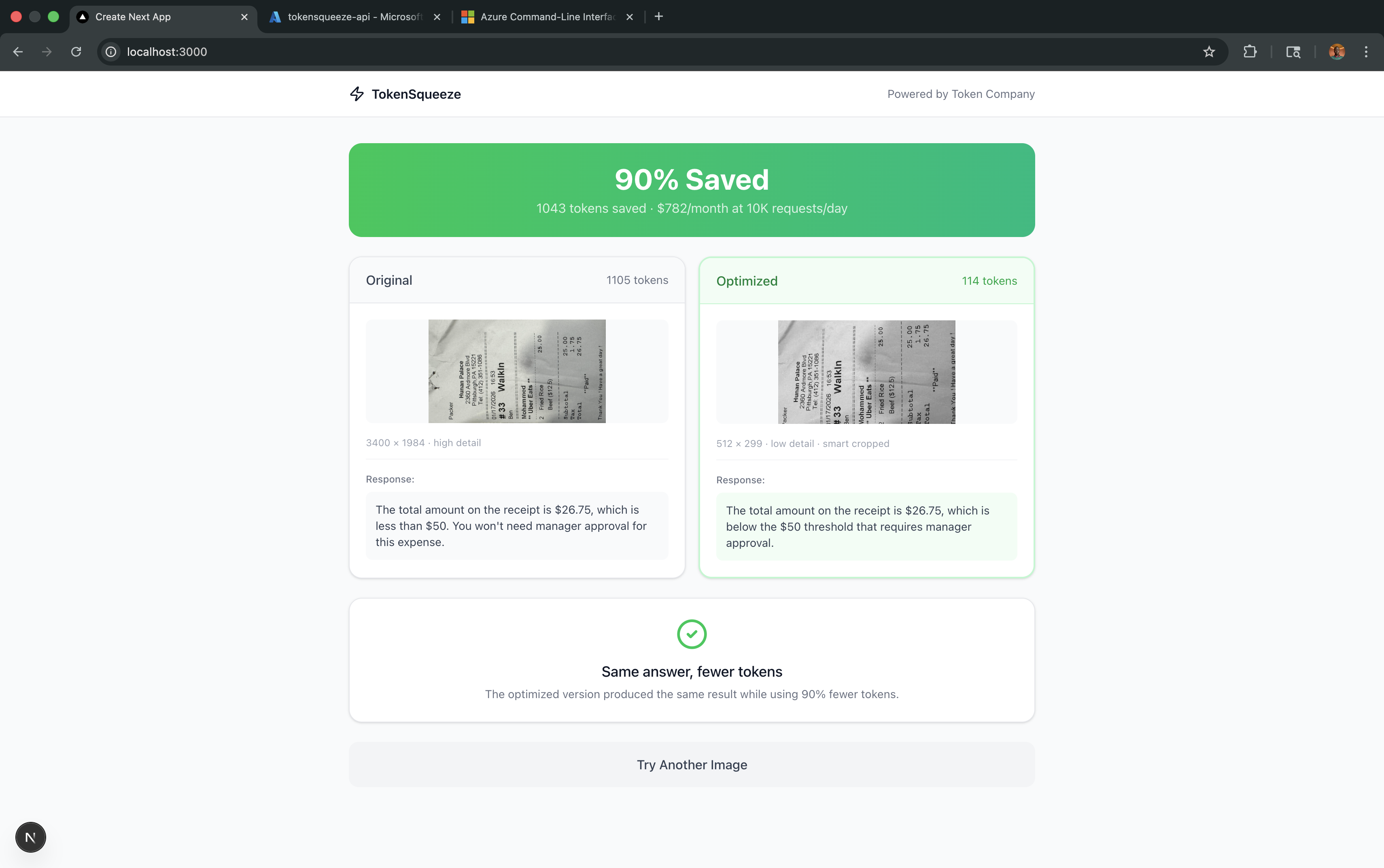
We noticed something expensive hiding in plain sight: vision LLMs charge by the pixel, but most questions don't need the whole picture. When you ask GPT-4o "Is the total on this receipt more than $50?", you're paying for every pixel in that 4000x3000 photo - the table, the background, the napkin holder - when all the model needs is a tiny cropped section of the receipt itself. The math is brutal:
- A typical smartphone photo: ~1,105 tokens
- A simple yes/no question actually needs: 85 tokens
- That's 92% waste on every single request. At 10,000 API calls per day, companies are burning $500+/month on pixels that add zero value to their answers. We built TokenSqueeze to fix this.
What it does
TokenSqueeze is an intelligent preprocessing layer that sits between your application and vision LLMs. It:
- Analyzes your question to understand what you're actually asking (binary question? text extraction? scene description?)
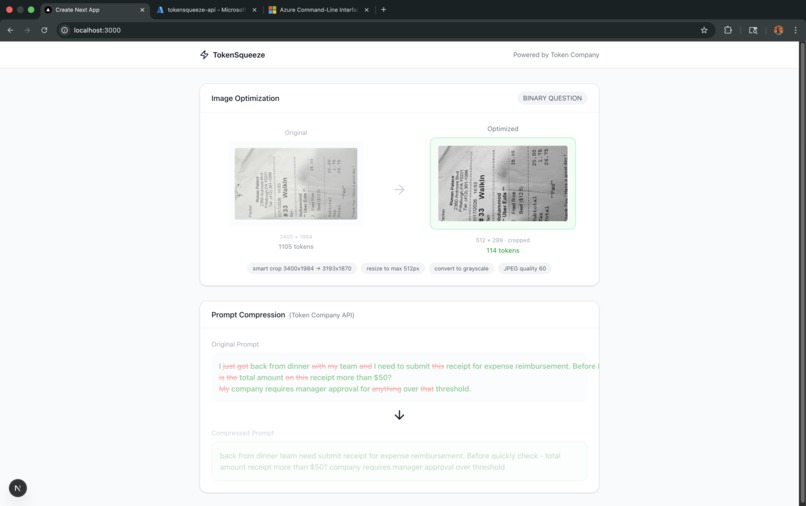
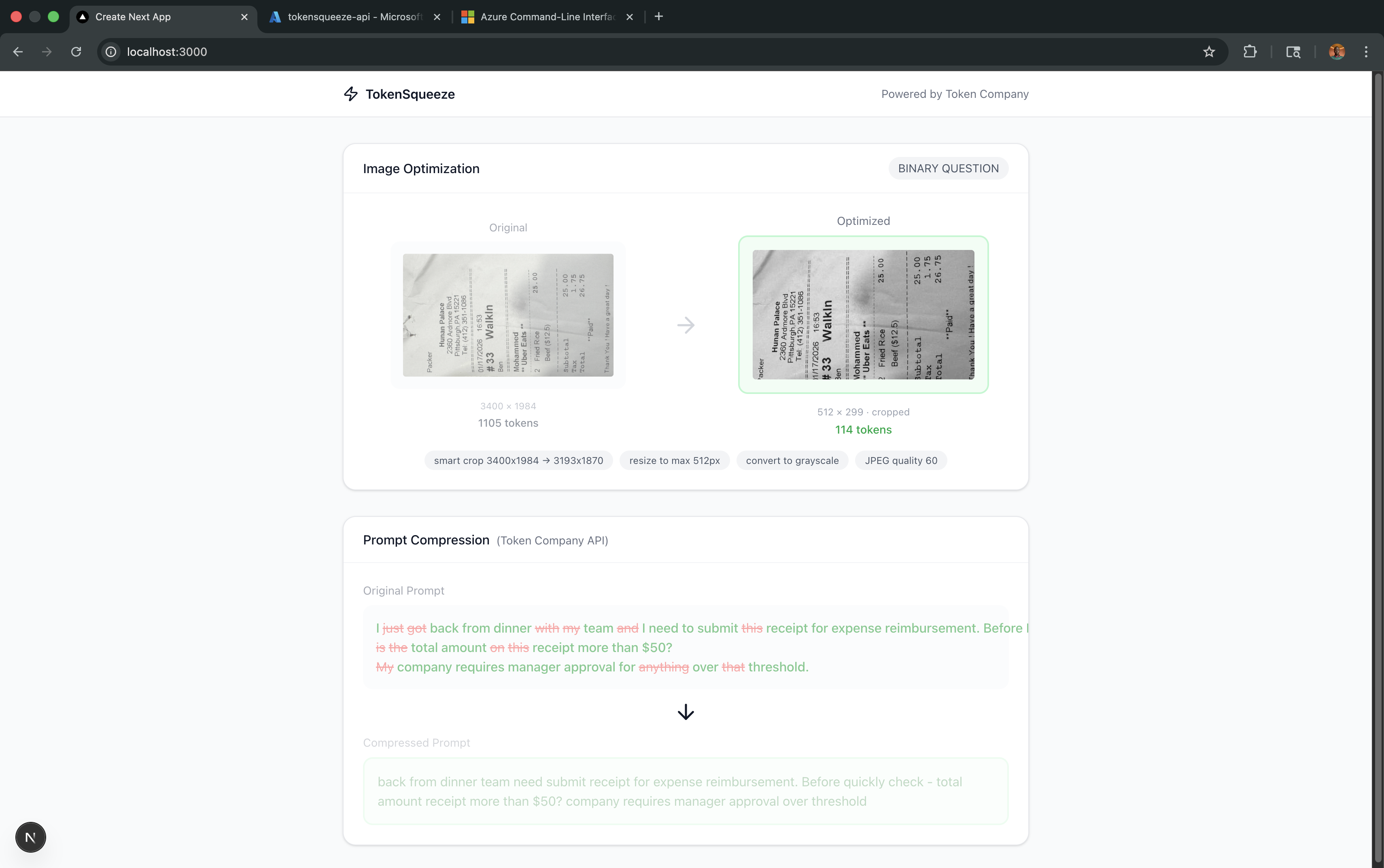
- Optimizes the image based on that intent - smart cropping, resolution adjustment, grayscale conversion and quality tuning
- Compresses your prompt using Token Company's bear-1 model to reduce text tokens too
- Delivers the same answer with up to 89% fewer tokens
How we built it
- Intent Classification (Hybrid Approach) We couldn't use an LLM to classify intent - that would defeat the purpose of saving tokens! Instead:
- Keyword Pattern Matching (95% confidence) - Fast regex patterns catch obvious cases like "Is there...", "Does this...", "Yes or no..."
Zero-Shot Classification (DeBERTa fallback) - For ambiguous queries, we use a lightweight 200M parameter model locally
Six Intent Categories | Intent | Detail Mode | Max Dimension | Example | |---------------------------|------------------|-------------------|-------------------------| | BINARY_QUESTION | low (85 tokens) | 512px | "Is the total > $50?" | | TEXT_EXTRACTION. | high | 2048px | "OCR this document" | | SCENE_DESCRIPTION | high | 1024px | "Describe this image" | | OBJECT_DETECTION | high | 1024px | "How many cars?" | | DETAILED_ANALYSIS | high | 2048px | "Analyze this chart" | | COMPARISON | high | 1024px | "Compare these two" |
Image Processing Pipeline
Smart Cropping: OpenCV-based document detection using Canny edge detection and contour analysis
Intelligent Resizing: Scale to optimal dimensions for the intent
Grayscale Conversion: For text-focused tasks where color doesn't matter
JPEG Compression: Quality tuning based on task requirements
Token Company Integration We integrated Token Company's bear-1 model to compress text prompts, squeezing additional savings from verbose user queries.
Tech Stack
Backend: FastAPI (Python)
Frontend: Next.js with animated step-by-step visualization
ML: DeBERTa for zero-shot classification, OpenCV for image processing
APIs: Token Company (text compression), OpenRouter (GPT-4o)
Challenges we ran into
The Classification Paradox Our biggest challenge: how do you classify user intent without using tokens? Using GPT-4o to decide if a question is simple would cost more than we'd save! Solution: Hybrid approach with regex patterns (free, instant) and a small local model (DeBERTa, ~200M params) as fallback.
Smart Cropping Edge Cases Document detection works great for receipts and forms, but struggled with:
Crumpled papers
Extreme angles
Low contrast backgrounds Solution: Multiple detection strategies (Canny edge, adaptive threshold, white region detection) with fallback to center crop.
Proving Equivalence How do you prove to judges that a compressed image gives the "same" answer? We needed side-by-side comparison showing identical model responses. Solution: Built a live demo that sends both original and optimized images to GPT-4o simultaneously, displaying both responses for direct comparison.
Accomplishments that we're proud of
- 89% token reduction on binary questions with zero quality loss
- Sub-50ms preprocessing - faster than the API latency itself
- Hybrid intent classification that doesn't require an LLM
- $500+/month savings at production scale (10K requests/day)
- Clean API that's a drop-in replacement for direct vision API calls
What we learned
- GPT-4o's pricing model has optimization opportunities - The low/high detail modes aren't well understood. Most developers default to high detail for everything.
- You don't always need an LLM - Pattern matching and small local models can handle classification without burning tokens.
- The 512px boundary matters - Below 512px in both dimensions, images cost a flat 85 tokens in low detail mode. This is the magic number.
- Intent matters more than content - A complex image with a simple question needs less resolution than a simple image with a complex question.
What's next for TokenSqueeze
- Short Term
- SDK/Library: Python and JavaScript packages for easy integration
- More Intents: Fine-grained classification (e.g., "counting" vs "locating" objects)
Batch Processing: Optimize multiple images in parallel
Medium Term
Model-Specific Optimization: Different strategies for Claude, Gemini, etc.
Caching Layer: Recognize similar images to avoid reprocessing
Analytics Dashboard: Track token savings over time
Long Term
- Enterprise API: Managed service with SLA guarantees
- Custom Training: Fine-tune intent classifier on customer data
- Multi-Modal: Extend to video frame optimization



Log in or sign up for Devpost to join the conversation.