-

cover logo
-

Inspiration
The inspiration for this project stemmed from the limitations observed in traditional video-based retrieval-augmented generation (RAG) systems. Often, these systems suffer significant context loss due to repetitive stages of image captioning, where vital visual details are gradually filtered out. We aimed to address this by building a pipeline that retains a richer level of context and visual detail. The ultimate goal was to create a novel Multimodal RAG pipeline that could efficiently process and analyze video content while maintaining deep, contextually-aware responses, maintaining a two-way process of video-text and text-video. The potential applications of such a system in healthcare and various other sectors further motivated us to push the boundaries of existing technologies.
What it does
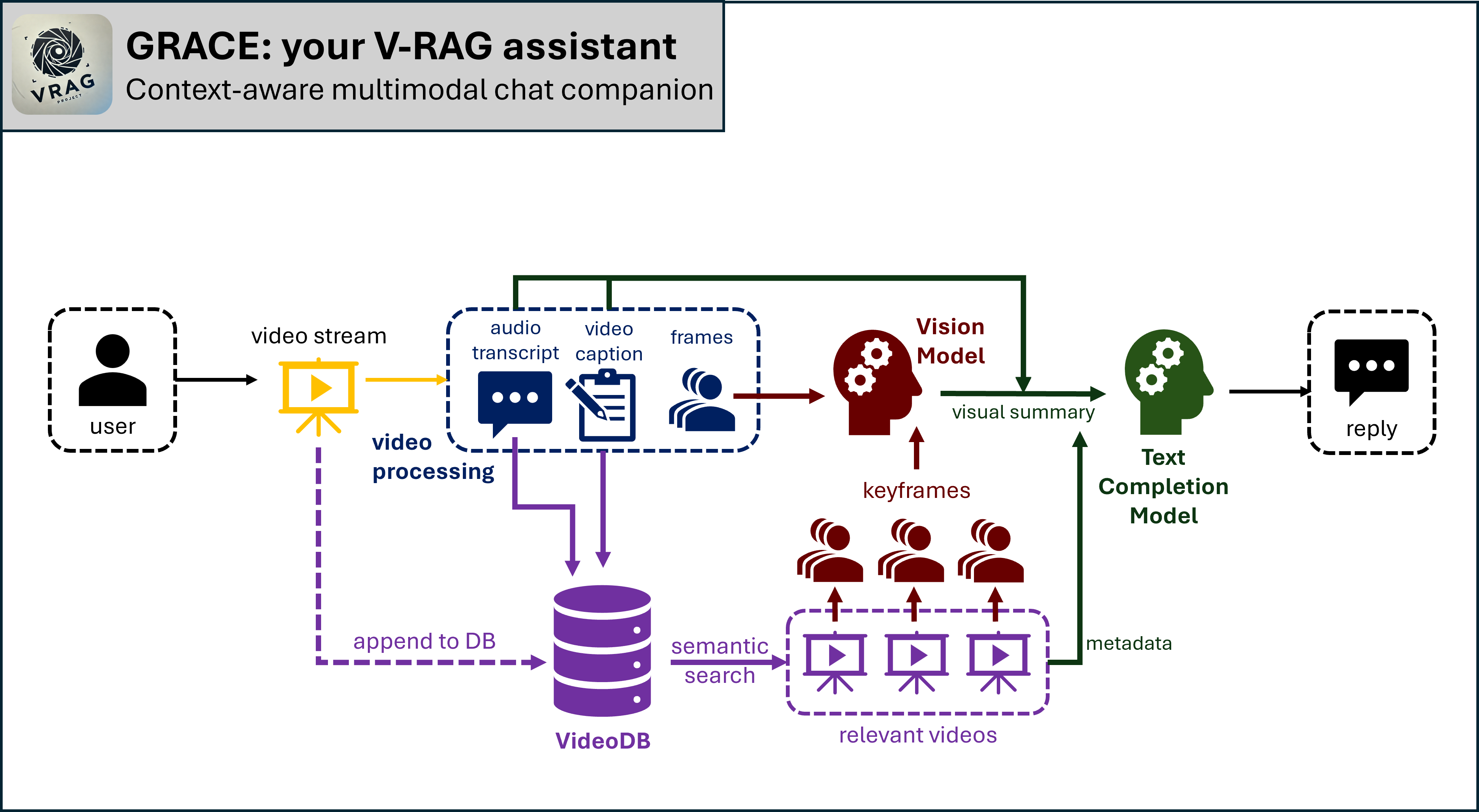
Our multi-step pipeline processes, retrieves, and generates enriched responses from video content. The project follows these stages:
- Initial Processing: Analyzes input video to generate metadata including dialogue, participant identities, and key events.
- Querying: Leverages semantic full-text search (FTS) or vector search (VS) to query metadata and retrieve relevant historical data.
- Re-ranking: Enhances the relevance of retrieved results by reranking them.
- Keyframe Retrieval: Identifies and retrieves keyframes based on the metadata.
- Secondary Analysis: Processes and resamples keyframes to regenerate and verify metadata for consistency.
- Metadata Comparison: Compares original and regenerated metadata to ensure accuracy.
- LLM Integration: Passes metadata to a language model (LLM) to create enriched, context-aware responses.
- Response Generation: Generates accurate responses that are contextually relevant.
- Logging: Logs metadata for iterative improvements, memory-persistence and future reference.
Compared to typical RAG systems, our pipeline is significantly more context-aware, with a focused approach to preserving and leveraging visual details for enhanced responses by maintaining a two-way conversion process powered by VideoDB, emphasizing Keyframe sampling.
Benchmarks of semantic retrievals on videos indexed by audio and scene descriptors yielded an average of 3 seconds for a repository of ~20 second clips. We maintain past conversations by inserting streamed footage on-the-fly during agent responses. This yielded a highly responsive agent who is capable of handling consecutive memory-persistent conversations with multiple users.
How we built it
We were particularly inspired by memory recalling of human beings. We figured that to generate truly authentic (and in some ways, flawed) responses of chat agents, they needed real memeroy. Not just text. But actual imagery that they could retrieve from their repository and cross reference with the input frames via the agent's peripherals. This brings human-computer/robot-interaction to the next step.
We utilized a combination of advanced tools and methodologies to build this pipeline:
- VideoDB: Implemented to index and query images and audio efficiently. -LlamaIndex: Implemented Video RAG (V-RAG) along with an escape hatch to resample keyframes from memory scenes.
- VideoLLaVa: Used to handle and caption the incoming video stream.
- GPT-4o and LLaMA: Employed for generating chat responses based on queried data, balancing the visual and textual understanding in a two-stage approach.
By leveraging these technologies, we constructed a microservices architecture capable of retaining richer visual and contextual information throughout the video analysis, augmenting response generation and regeneration stages.
Challenges we ran into
Developing this system was not without its challenges: -Cost and Scaling up: We had plenty of easy solutions. Pay for a better model. Use Claude. Get a A100 Cluster. But we decided to be cheap and resourceful, utilizing GPT models minimally and investing development time into MLOps on Llama and foreign OSS.
- Database Limitations: The database used were not very tweakable, as VideoDB is traditionally a database used for video retrieval, not for active and dynamic conversations. This limited some customization options for optimizing query performance, but we ultimately bypassed these by utilziing with concurrency and batching techniques.
- Vision Model Constraints: Current vision models faced challenges with handling long context windows for images, making image-based RAG processes expensive. We overcame this by implementing a two-stage model that separately handles vision and text, optimizing efficiency.
- Balancing Context Retention: Ensuring that visual details were preserved without overwhelming the model or losing critical textual context posed significant difficulties.
Accomplishments that we're proud of
We are proud of developing a pipeline that achieves superior context awareness in video RAG systems. The integration of multi-stage processing and the combination of vision and LLM technologies have resulted in a tool that can effectively generate enriched, contextually accurate responses from a singular video input. Additionally, finding an efficient way to process both visual, audio and textual information cohesively stands as a major achievement as we developed extra hatches that resamples existing memories.
What we learned
Throughout this project, we gained insights into:
- Optimization of Vision Models: Understanding the constraints and possibilities of current vision models and adapting strategies to mitigate their limitations.
- Context Preservation: Techniques for balancing and preserving detailed visual and textual context throughout a multi-step pipeline.
- Tool Integration: Effective ways to combine tools such as VideoDB and LLMs for comprehensive video analysis and response generation, and studying abstract documentation to supplement the trial and error nature of new tools.
- It is very important to take CS 537: Operating Systems
What's next for V-RAG
Moving forward, we envision:
- Expanding Use Cases: Further applications in fields like healthcare, where a companion robot can use video analysis to support patient setup, or in assistant bots that handle massive amounts of video content for processing and Q&A.
- Enhanced Customization: Improving database flexibility and expanding the range of adjustable parameters for finer control.
- Scaling and Performance: Developing scalable methods to extend the pipeline's capabilities for even larger datasets and longer video streams.
- Refined LLMs: Integrating more specialized language models fine-tuned for specific industries, enhancing response quality and relevance.
- Getting a A100 cluster with 5x Flash attention would speed up inference significantly. And everyone would've been happier.
V-RAG sets a foundation for more comprehensive, multi-modal context-aware video processing that can revolutionize how visual content is analyzed and utilized across various industries, specifically for chat agents.
In other words, we're one step closer to sentient androids!!!!









Log in or sign up for Devpost to join the conversation.