-
-
Landing Page
-
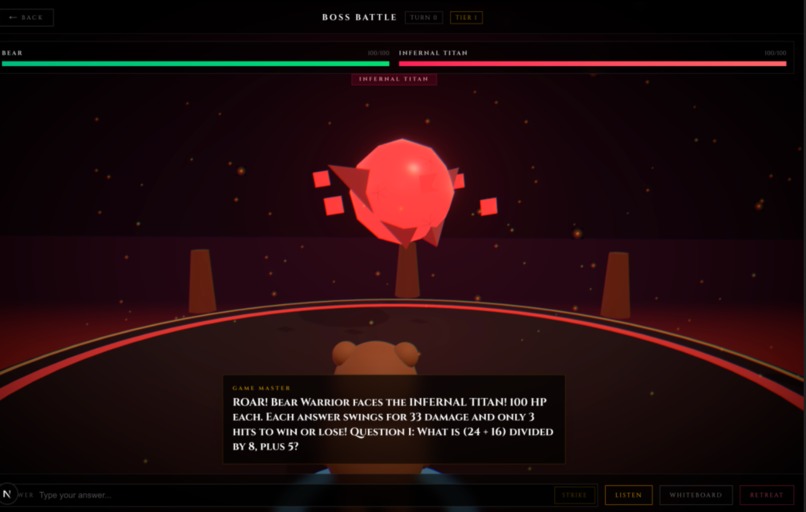
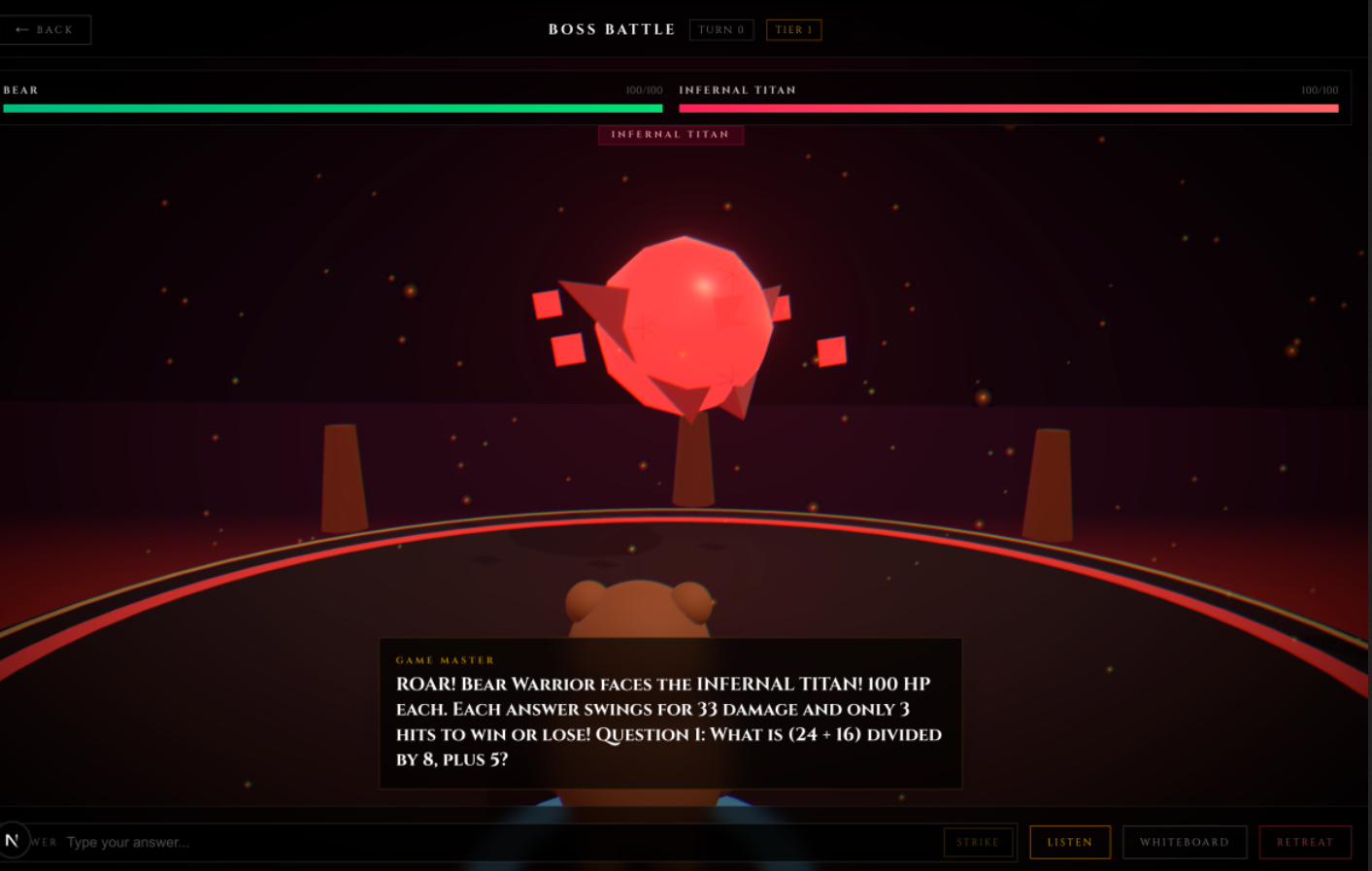
Voice Powered Problem Solving - Boss Game
-
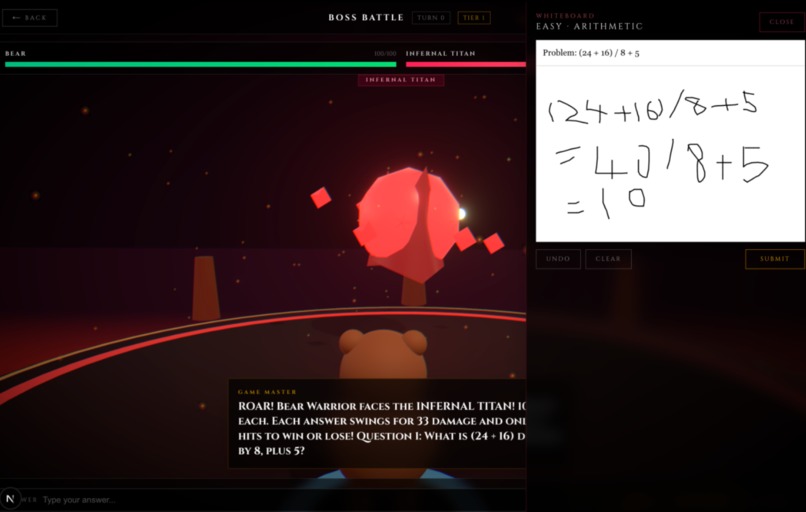
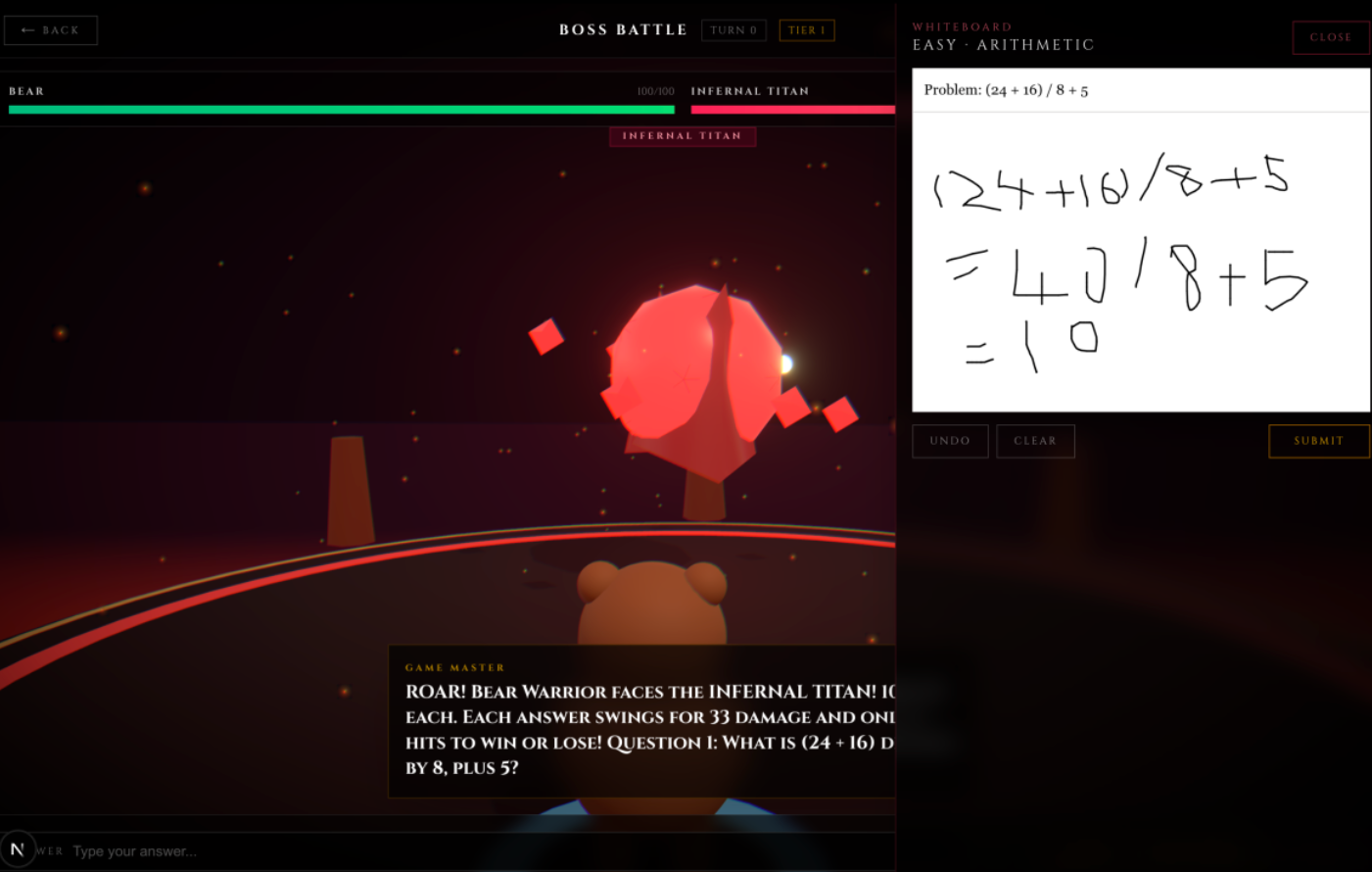
Whiteboard Feature with Gemini Agentic Vision Model - Boss Attack Game
-
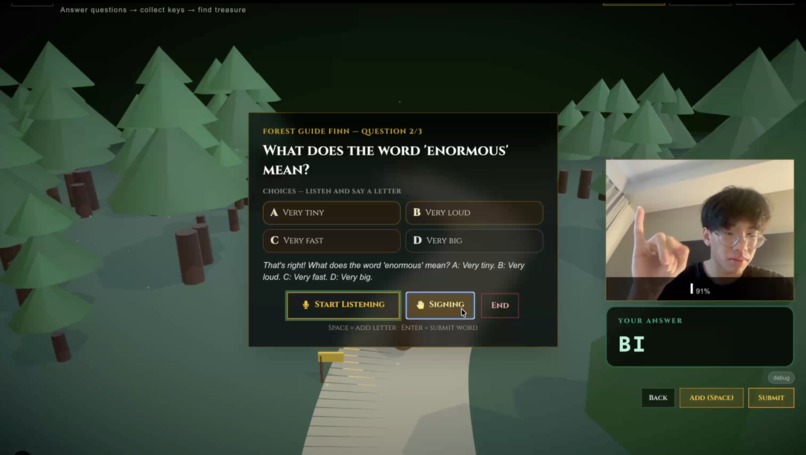
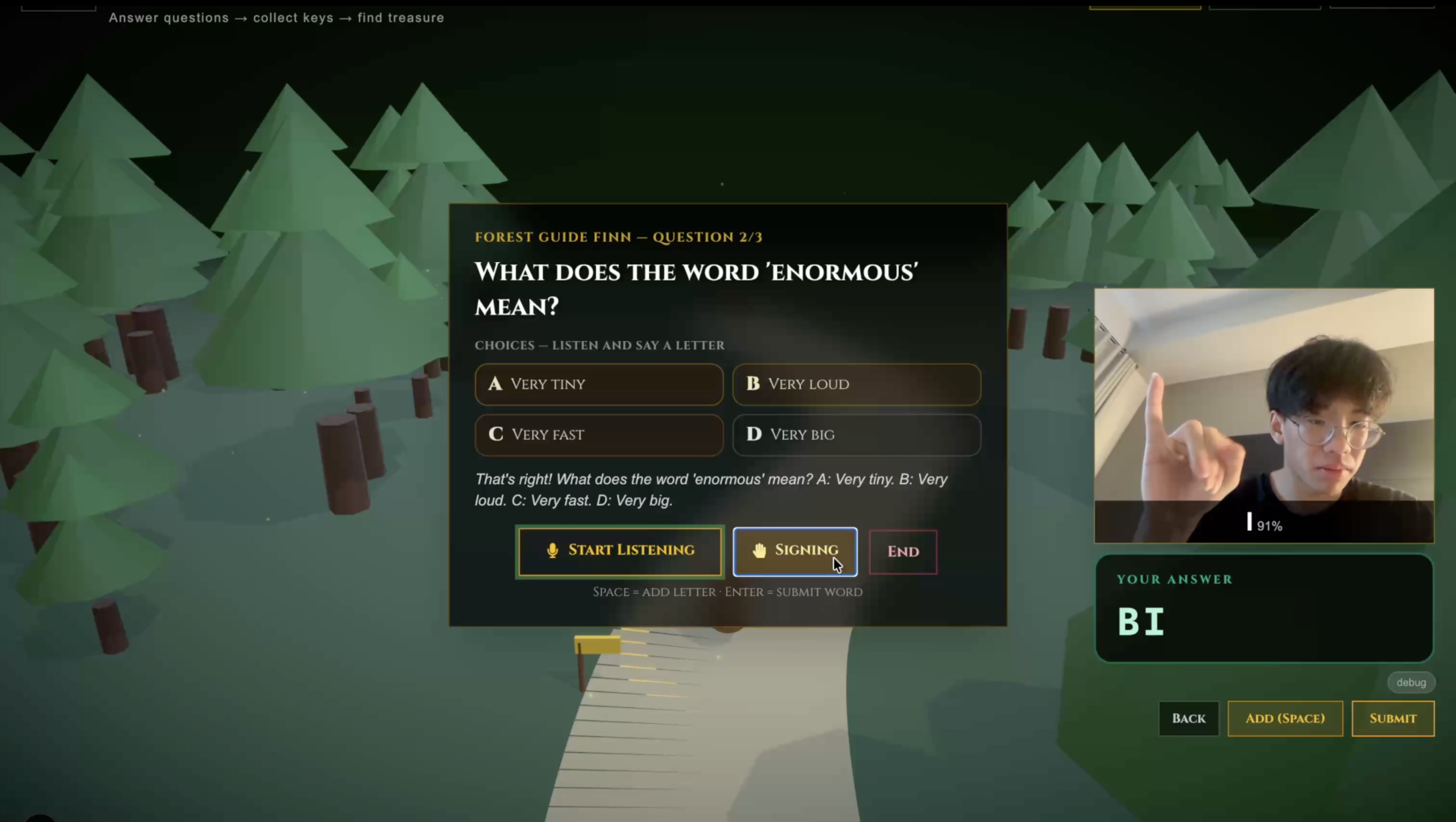
ASL Computer Vision Recognition - Adventure Game
-

Turn videos into Conversational Lessons - Maze Game
The problem
One in six kids learns differently: Deaf, neurodivergent, ADHD, autistic, dyslexic, or with a limb difference. The tools meant to help them are some of the most boring software in the world: quizzes built for a hearing kid with two hands and a working keyboard, then "made accessible" with a captions toggle.
Research is clear that interactive dialogue beats passive content for retention, especially for kids with attention and processing differences. Khanmigo proved AI can carry a real tutor conversation, but it's 18+, paywalled, US-only, and built for keyboard and ears. The kids who would benefit most, Deaf students who can't hear a voice agent, neurodivergent kids who disengage from quiz UIs, kids with limb differences who can't type, are locked out.
A conversational, character-driven game is more engaging, more retention-friendly, and more fun than a quiz. For special-ed kids, that's the difference between a tool that gets used and a tool that gathers dust.
Who we built this for
- Deaf and hard-of-hearing students who use ASL fingerspelling on camera and read every line from always-on captions.
- Neurodivergent students who get a low-friction voice loop, a character they actually like talking to, and progression that rewards engagement instead of punishing wrong answers.
- Students with limb differences who never need a keyboard or mouse: voice handles the entire experience.
Modality is the first choice the product asks you to make, not the last. There's no separate "accessibility mode."
What we built
V↑ is a conversational learning platform where the input modality is the student's choice. Speak it, sign it, or show your work on paper. Pick a character. Land in a 3D game world. Talk through it with a voice that actually responds.
- Maze Quest (Science). First-person 3D maze. Answer a science question to earn a step toward the glowing portal.
- Boss Battle (Math). Dark arena boss fight. Solve a math problem to land a hit. Submit a photo of your scratch work and the Gemini Agentic Vision model annotates it like a teacher: green checks on correct steps, red circles on the first mistake, a one-line note explaining where you went wrong.
- Forest Path Adventure (Reading + ASL). Branching forest trail. Answer multiple-choice questions by speaking, typing, or fingerspelling on webcam. Three Knowledge Keys unlock the treasure.
Pick the Bear, Fox, Robot, or Cat once at the hub and they follow you across every game with their own ElevenLabs voice and personality. The Maze Bear is a patient science buddy; the Boss-Battle Bear is a battle-hardened warrior. Same voice, different persona: twelve agents in total.
What makes the conversation feel alive
- Real conversational agents, not one-shot TTS. ElevenLabs Conversational AI through
@elevenlabs/reactgives us turn-taking, interrupts, and natural pacing instead of robotic "press to talk" UX. - Captions are always on. Every line the character speaks renders as a styled HUD card in real time.
- Multi-modal answers, one loop. Voice in. Sign in. Photo in. They all flow into the same conversation state.
- Deterministic answer judging. The client controls question order and judges answers locally with a permissive matcher. The agent's only jobs are speaking, reacting, and calling the right client tool: no hallucinated grading in front of a kid.
Multi-modal input pipeline
This is where the technical depth lives.
Voice. ElevenLabs Conversational AI streams full-duplex audio in the browser, with auto-mute on connect so background noise doesn't trigger false transcripts.
ASL fingerspelling. A FastAPI backend running two PyTorch models behind MediaPipe Hands. The client sends webcam frames at 5 fps; the backend predicts a letter:
- Landmark MLP (primary). A 4-layer MLP over normalized 21-keypoint hand landmarks (63-dim, 256, 256, 128, N). Trained by us. Fast and lighting-tolerant.
- CNN fallback. A 3-block convnet on grayscale 28×28 hand crops, trained on Sign Language MNIST.
The frontend has a live letter prediction badge, confidence bar, word buffer, and a permissive answer matcher that accepts the answer letter ("C"), the full choice ("FRIEND"), or the last word of a multi-word choice.
Scratch work via Gemini Agentic Vision. A pressure-sensitive HTML canvas whiteboard. On submit, we send the JPEG plus the problem and answer to Gemini 3 Pro Image Preview with a teacher-grading prompt. Gemini doesn't just OCR: it analyzes each step, locates the first mistake spatially, and returns the original image annotated with green checks, red X marks, a circle around the error, and a short note ("sign error", "incorrect subtraction"). We parse a trailing VERDICT line and route the result into the fight: correct calls dealDamageToBoss, incorrect prompts a retry. The annotated image renders side-by-side with the problem so the kid sees exactly where they went wrong.
Bring-your-own-lecture. A student uploads a short lecture video, a class clip, a YouTube explainer, a tutor recording, and the game rebuilds around it. The backend transcribes locally with faster-whisper, then sends the transcript to Gemini to generate eight age-appropriate questions. The same character now teaches the material the student actually needs to learn that week. This is the feature we're proudest of: it turns the platform from a fixed curriculum into a personal tutor for whatever a kid is studying.
The 3D worlds
Built in React Three Fiber with drei and @react-three/postprocessing. Three distinct visual styles, one shared character system.
- Maze Quest: night-time hedge maze, purple bloom, instanced wall geometry, sparkle particles around the goal portal.
- Boss Battle: dark stone arena with a procedurally animated icosahedron boss (HP-driven phase color shift, hit flashes, wing flap, orbiting damage shards), camera shake, lava-glow ground, chromatic aberration.
- Forest Path: warm fog and god rays, 120 instanced trees on a seeded layout, curved Catmull-Rom path, animated treasure chest with spilling coins on victory.
A Zustand store per game serves as the source of truth for HP, XP, conversation state, current question, and active character. The hub store persists the chosen character so they carry across games.
What we learned
Accessibility is not a feature you just throw on on at the end. We started thinking we'd build a learning game and "make it accessible." That framing was already wrong. A Deaf student doesn't need a captions toggle on a hearing-first product; they need a product where their input modality is first-class from the first design decision. We rebuilt the input layer twice before it stopped feeling like an accommodation and started feeling like a choice.
The conversation is the curriculum. The way the character talks matters more than what the character knows. A warm "good try, let's look at this again" recovers a frustrated kid in a way a red X never will. We treated prompt tone with the highest priority: patient, encouraging, never sarcastic, and never demeaning to the student.e
Honesty is a feature. It would've been easy to call our system "ASL support." We don't. We call it fingerspelling input for answers, because that's what it is, and the Deaf community has been burned by hearing developers overclaiming. The same honesty pushed us to add a confirmation step before grading scratch work: a misread digit telling a struggling kid they're wrong is a real harm, not a UX edge case.
The student should have control on what they want to learn. Letting a kid drop in their own lecture video and have the game rebuild around it is the answer we're proudest of. The kid picks what to study, how to answer, and who to learn from. Our job is to make every one of those choices feel native.
Challenges we ran into
Designing for three audiences at once. Deaf, neurodivergent, and limb-difference kids have almost no overlapping accessibility needs. Our first instinct, a unified "accessibility mode", collapsed in a day. The reframe that unlocked the project was treating modality as the primary axis, not disability. The same kid might want to speak today and sign tomorrow. The platform doesn't ask why.
The conversational loop is unforgiving. Streaming voice, gating game state on a deterministic answer judge, keeping captions in sync, and never letting the character be silent for more than half a second is a system, not a feature. We threw out our first orchestration design (let the agent pick the next question) because it made every turn feel like the AI was thinking instead of teaching. Making the client deterministic and the agent purely expressive is what made the demo feel alive.
What's next
- Real ASL recognition beyond fingerspelling (whole signs, two-handed signs).
- Direct integration with class lecture libraries so students can pull a lesson straight into a game.
- COPPA/FERPA-compliant pilot with a special-ed classroom.
- More games, characters, and topics: same engine.




Log in or sign up for Devpost to join the conversation.