-
-
Final Poster
Introduction
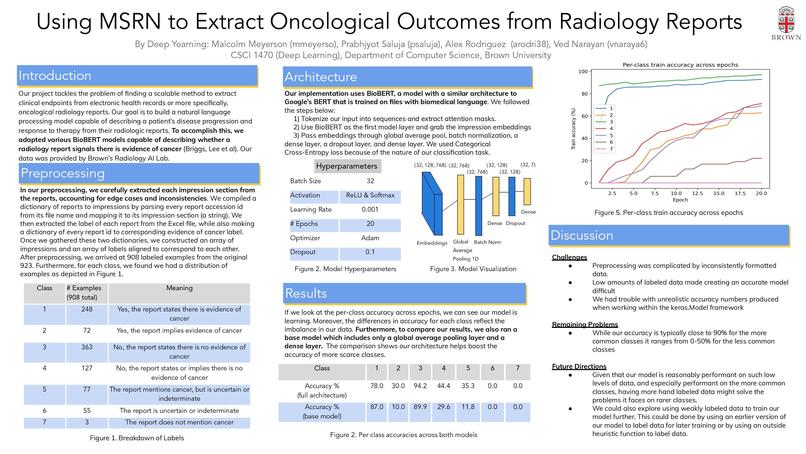
Machine learning can be a catalyst for rapid health care systems. In these systems, patient data can be used in real time to carry out cost-effective, personalized and low-risk treatments. Our project tackles the problem of finding a scalable method to extract clinical endpoints from electronic health records or more specifically, oncological radiology reports. To this end, we collaborated with Brown’s Radiology AI Lab. They provided us with all data and labels we used for this project. Usually, reports come in large amounts and it is sometimes difficult to gauge the meaning of the author’s impression, as it can include a lot of technical language. Our goal is to build a natural language processing model capable of describing a patient’s disease progression and response to therapy from their radiologic reports. To accomplish this, we adapted various BioBERT models capable of describing whether a radiology report signals there is evidence of cancer [2][3]. The result is outputted as a numerical label, indicating varying degrees of cancer evidence (as seen in the table below).
GitHub Repo
What it does
Our group was given the task of classifying oncological radiology reports using annotated reports provided by Dr. Bai in Brown's AI Radiology Lab. We built a model that uses BioBert that takes in oncological radiology reports, extracts a label from one to seven, and outputs an indication of cancer evidence.
How we built it
Our model uses BioBERT to grab embeddings and then passes these through a global average pooling layer, a batch normalization layer, a dense layer of size 128 with a ReLU activation function, a dropout layer with rate equal to 0.1 and a final dense layer of size seven with a softmax activation function. Our batch size was 32, our optimizer was Adam with a learning rate of 0.001 and our number of epochs was 20. This combination of layers and hyperparameters allowed us to achieve our highest accuracies.
Challenges we ran into
Our biggest challenge was our small and imbalanced dataset. Low amounts of labeled data made creating an accurate model difficult. Moreover, preprocessing was complicated by inconsistently formatted data. We lastly had trouble with unrealistic accuracy numbers produced when working within the Keras framework, which led us to re-write our model and to make sure we had robust accuracies.
Accomplishments that we're proud of
We're happy to have implemented a model with robust accuracy, as well as one that performs relatively well for such a small dataset. We're also proud of having built a model from the group up that makes use of BioBERT to extract embeddings. While programming this project, we learned a lot about NLP, using the Huggingface API and thinking critically about our metrics and architecture.
What we learned
We learned to use Huggingface for NLP tasks, specifically, using a model to extract embeddings and training a classifier over these. In our different trials, we also learned to use Keras's API functions such as fit() and evaluate() and learned to think critically about what our model is doing when re-implementing it without these and instead structuring it similar to our homework.
What's next for Using MSRN to extract Oncological Outcomes from Medical Data
Given that our model is reasonably performant on such low levels of data, and especially performant on the more common classes, having more hand-labeled data might solve the problems it faces on rarer classes. We could also explore using weakly labeled data to train our model further. This could be done by using an earlier version of our model to label data for later training or by using an outside heuristic function to label data.
Links
Built With
- biobert
- natural-language-processing
- tensorflow






Log in or sign up for Devpost to join the conversation.