-
-
Our Poster! Please Enjoy
Eli Shea and Zachary Huang
Original Devpost Outline for Final Project
Title
“Using Convolutional Neural Networks to Classify NFL Bets”
Who
Eli Shea eshea1 Zachary Huang zhuang68
Introduction
We will be attempting to build a convolutional neural network to classify NFL bets. Both of us are big football fans, as well as avid poker players, so we were interested in thinking of how we could use deep learning to work on a complex and interesting problem. Eli is starting a job as a Quantitative Trader after graduation and talked with another trader who works on providing betting markets for the NFL. The conversation was so interesting, we wanted to take a shot at a simpler version of the problem. Our goal is to look at betting data and team statistics, and use it to try to classify bets as profitable or not. We also plan on focusing on “spreads” which are a type of be in which a bettor is given a number that represents how much a team is expected to win by. For example, if the Patriots were playing the Dolphins, and odds makers expected the Patriots to win by 4.5 points on average, the spread would be “Patriots -4.5”, or equivalently, “Dolphins +4.5”. If someone bet on the Patriots, in order for them to win the bet, the Patriots would need to win by greater than 4.5 points, where if the bet on the Dolphins, they would win the bet if the Dolphins win by greater than -4.5 points, which means the better would win if the Dolphins win, or if they lose by less than 4.5 points.
Relevant Work
While we are trying to approach this as an original problem and not implement someone else’s work, there has been some work done in this area already that we can learn from. One good example is: https://www.sciencedirect.com/science/article/abs/pii/S016920701930007X This paper discusses using a convolutional network to develop a strategy on money line bets for NBA games, as well as pointing out some of the potential issues, such as the learned model being coupled with the bookmaker’s model. They ultimately go on to try to learn an optimal strategy balancing expectation and variance to help a sport’s bettor allot their bankroll. One feature they included that we find interesting and intelligent is confidence thresholding, or an estimate of confidence that the model’s classification of a bet is correct. This seems particularly important to keep in mind, since by the bookmaker’s model, the bets being offered are not fair, that is, the bookmaker believes they have positive expectation on every bet they offer. This paper, while not what we are trying to implement, serves as a good baseline of knowledge
Data
Right now, we are planning on using two main datasets for this problem. The first is an online machine learning dataset we found on Kaggle, titled “NFL Scores and Sports betting data”, which has a list of seemingly every NFL Game since 1966, along with accompanying information about the bets that were available. The dataset has around 13.2 thousand entries. The second dataset is from sports-reference.com, which has historical box scores of every game with a huge list of accompanying statistics that we may want to incorporate into the model. Both datasets will require a little cleaning, such as transforming some qualitative factors into quantitative ones, and reconciling the two datasets so that they match up, but we don’t expect this to require an incredible effort.
Methodology
While we don’t know exactly what the model architecture is going to look like, we have decided to start with a CNN because of its ability to transform complex data and perform classifications on the transformations, by identifying the pertinent features. While the examples for CNNs we have used in class have mostly been images, we believe this frame work can be extended to numerical data, and that we will be able to use the model to hopefully not only classify bets as good or not, but also be able to identify the features of our data that most impact that classification As a backup, we may try to do a more simple feed forward network if we run into unforeseen issues with the CNN
Metrics
We fully recognize that this is a difficult problem, and that achieving success with a model on sports betting is far from trivial. We therefore think it is important to have well defined metrics of success We believe that if our model is able to have betting success better than randomly selecting a side of the bet, then it will be successful. We will be able to quantify what percentage of its predictions are correct, as well as how confident it was in those predictions. Because this is a classifier trained on historical data, accuracy seems like a solid starting point as a performance measure Our base goal is to at least do as well as random selection, with a target of at least slightly outperforming random selection (i.e. >50% Accuracy). A stretch goal would be a model that correctly classifies bets with significant consistency to the point one would expect to be quite successful making bets in line with its classifications (i.e. >60%). Another way of evaluating performance we discussed would be measuring how our model does on bets across time. That is, we expect that as time goes on bookmaker’s models become better, and therefore, we hypothesize we are likely to have a higher probability of success on betting lines given by older bookmakers. Finally, because we recognize challenges in having success in this field, we hope that even if we don’t have significant predictive success, that the features or model identifies as being the most significant for classification are interpretable, and we can learn from it in that way
Ethics
While betting on NFL games isn’t on the face of it riddled with ethical issues there are still a few things we must consider First, that for some people, betting can be an addiction, and that from some ethical perspectives, bookmakers try to leverage their access to data and information to take advantage of people who don’t have the same access. Our project does not address this issue directly, but we must think about whether we could be potentially contributing to a similar problem From that, we suppose that the underlying ethical issue is considering at what point a bet agreed upon between two parties becomes unfair. If one party has access to significantly more information than the other is that inherently not right? Or should both parties have an expectation of the risks involved when entering into a bet, and does one have an obligation to the other to make sure they are aware of the odds they are getting?
Division of Labor
While we plan on both being involved in every part of the project, Zachary will be in charge of data extraction and preprocessing, while Eli will be in charge of analyzing results and drawing conclusions, and we will work together on making choices regarding the model architecture.
Reflection for Part 2
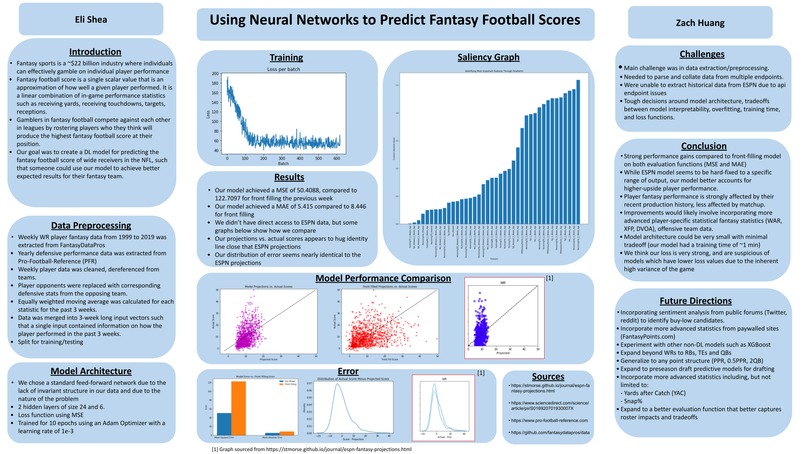
Eli Shea and Zach Huang CSCI 1470 Final Project Check In 2 Reflection We have made a few significant changes to our project since the outset. First and foremost, we realized that using a CNN for our task will likely not be the best approach since our data isn't heavily dependent on its structure. Furthermore, we talked about some of the limitations with our first approach, namely that the sample size we were working with was limited to about twelve thousand NFL games, which we ultimately decided was not enough to make a robust model. We therefore shifted our focus to using NNs to help predict Fantasy Football scores for Wide Receivers in the NFL. There is a lot of data available for this, which has made it easier to make sure we focus on only the most relevant information. So far, a significant portion of our work has been devoted to preprocessing of the data, although we have spent a lot of time discussing our plans for our model architecture as well. One of the features we have decided to engineer is a trailing average of a player’s statistical information, week over week, so that we have a glimpse into how a given player is performing lately. This makes a lot of intuitive sense and we believe will help deliver better results, but it does mean that we have to take extra steps to make sure there is no data contamination between our training and testing data, which has required a little extra work. We have also spent some time reflecting on how to judge the success of our model. Since we have shifted to doing a regression problem, we don’t have accuracy to use as a metric. We believe that Mean Squared Error is a good way to approach this, but recognize that we need to contextualize this error with some baseline performance. Our current approach right now, is to say that our model is successful if it performs better than just using a players score from the previous week.
Final Writeup And Reflection
Please find our final write up through this link: https://docs.google.com/document/d/1KSwj1YFlvLGUYlJcBzOs9mZSi2SHik4wqfw4gUYewhk/edit?usp=sharing


Log in or sign up for Devpost to join the conversation.