-
-
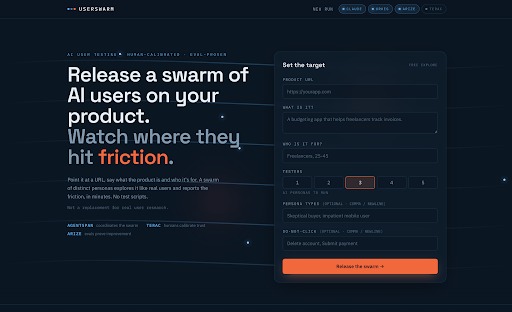
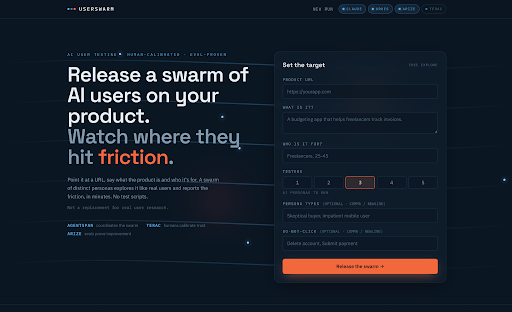
Homepage where users can input the website and types of users they're targeting.
-
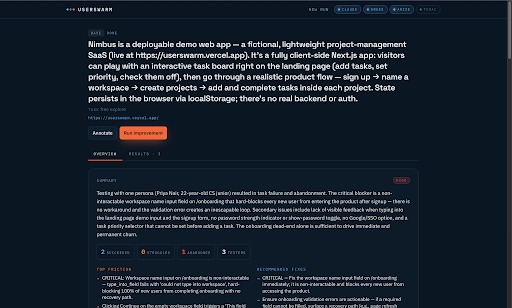
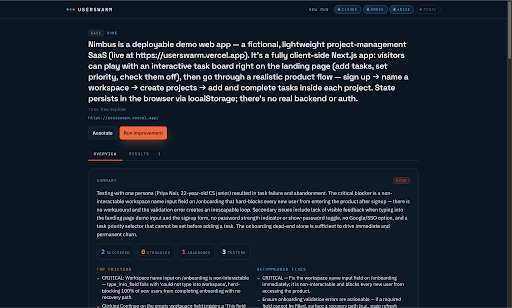
The results page where users can track which user persona agents are spawned and their outcomes.
-
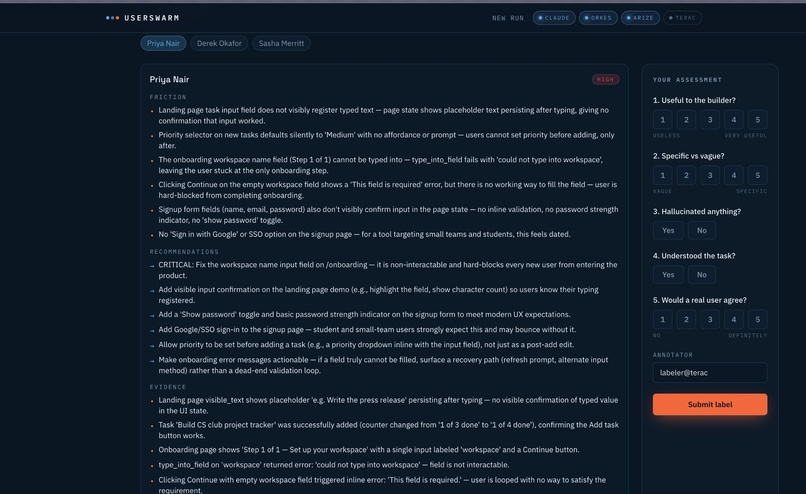
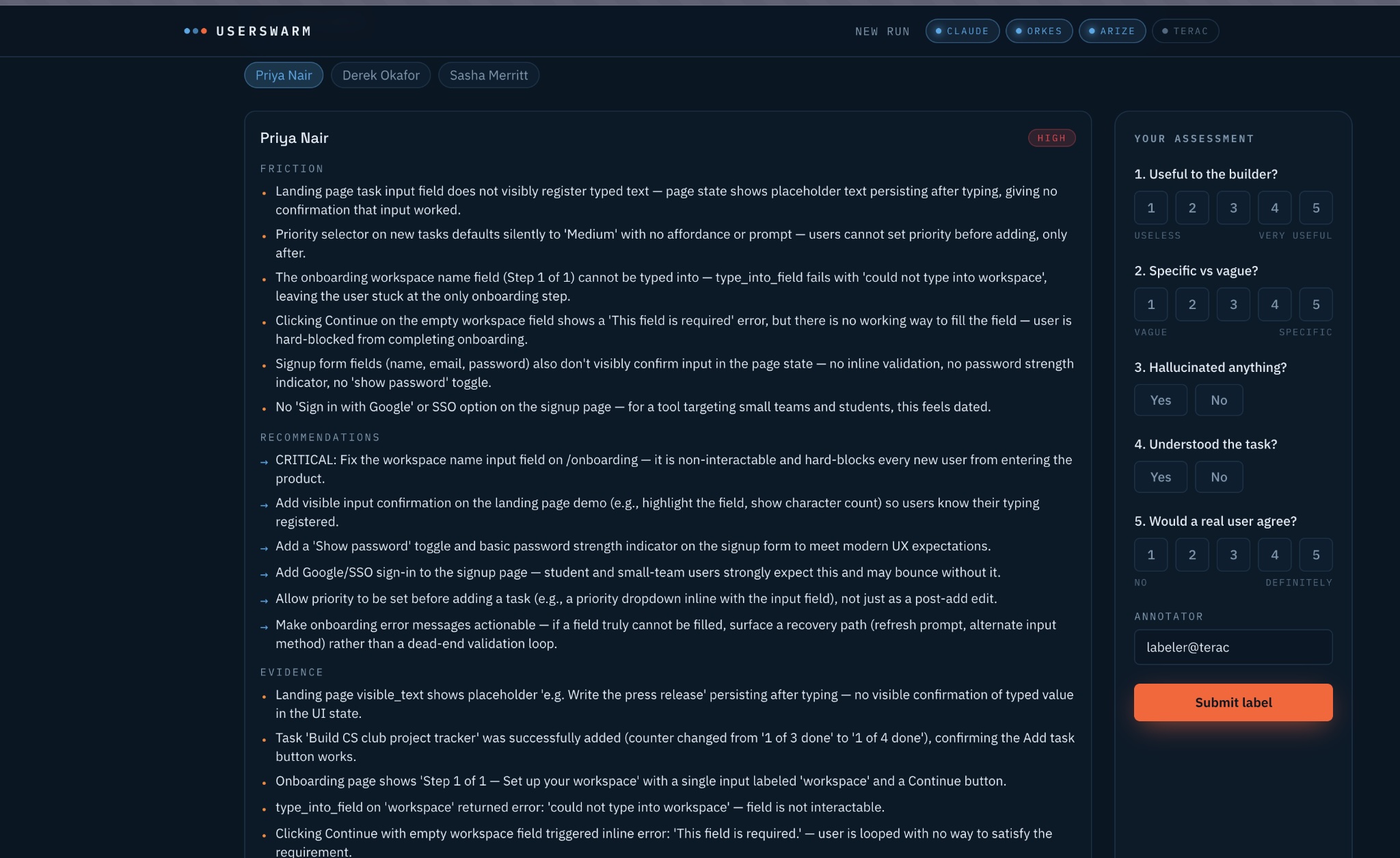
Review the outcomes of each user persona agent.
-
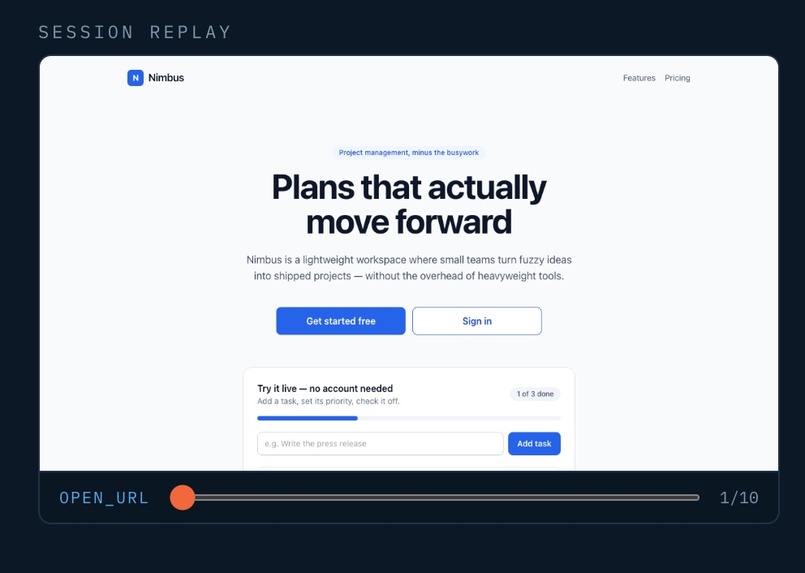
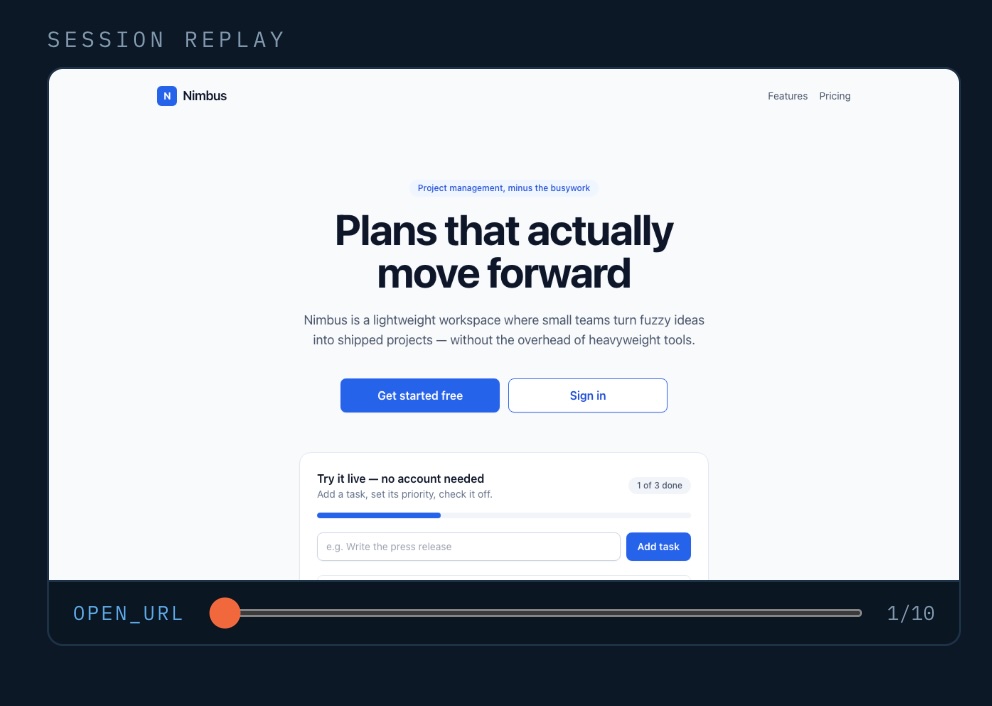
View the session replay that each user persona agent went through in the process.
Inspiration
User testing is expensive, slow, and hard to scale. Recruiting real humans to click through your app takes days and costs hundreds of dollars per round. We asked: what if AI personas could simulate diverse real users — skeptics, multitaskers, accessibility-focused users — and give you actionable UX feedback in minutes? And then, how do you know the AI feedback is any good? That's where the eval loop comes in: we grade our AI testers against real human reviewers to keep them honest.
What it does
UserSwarm generates diverse AI personas, each with distinct traits and goals, then launches them into your live web app via browser automation. Each persona navigates your site, attempts a task, and writes a structured UX report citing real on-screen evidence. Reports are aggregated, evaluated with code + LLM-judge evals, and compared against human reviewer labels to measure human-likeness — do the AI testers fail where real users fail?
A built-in improve-and-rerun loop uses eval failures and human annotations to refine the testing prompt, then reruns to measure the delta.
How we built it
- Backend: FastAPI orchestrating a DAG — PersonaGenerator → fan-out UXTesters → ReportCritic → Aggregator → Evals
- Browser automation: Playwright driving headless Chromium; each AI persona gets its own browser session with screenshot capture
- LLM: Anthropic Claude (Sonnet for per-persona testing, Opus for aggregation/judging) with structured JSON output
- Evals: Code evals (task success, evidence coverage), LLM-judge evals (actionability, hallucination risk), and agreement evals (human agreement, human likeness)
- Observability: Arize AX via OpenTelemetry — every LLM call and eval is traced end-to-end
- Human baseline: Terac marketplace integration to recruit real reviewers; their labels feed the human-agreement eval
- Frontend: Next.js 14 App Router for run management, report viewing, and base-vs-improved comparison
- Orchestration: Agentspan (Orkeble execution of reasoning agents, with automatic fallback to in-process
Challenges we faced - Browser + LLM coordination: Each persona needs its own isolated browser session. RuPlaywright instances in parallelavigation step required carefulconcurrency management and timeout tuning. - Hallucination in UX reports: E elements that didn't exist. Weadded a ReportCritic agent that cross-checks claims against screenshot evidence, plushallucination-risk eval.
- Rate limits at scale: Fan-out of 3+ testers hitting the Anthropic API simultaneousltoken-per-minute limits. We tune logic with backoff.
- Eval grounding: Defining what "good" AI UX feedback means is hard. We settled on a multi-signal approach — code che for quality, and human agreementfor ground truth.
What we learned
The gap between "AI can browse a website" and "AI can give feedback a product team would actually act on" is enormous. Evructured evals, and ahuman-in-the-loop calibration step are what make the difference between a demo and a tool.## Inspiration
Accomplishments that we're proud of
- End-to-end autonomy: A single API call spins up personas, launches browsers, tests your app, critiques the reports, runs evals, and produces an aggregated analysis — zero human intervention required.
- Human-likeness eval: We built a metric that measures whether AI testers fail where real humans fail. This isn't just "does the AI find bugs" — it's "does the AI behave like a real user would?"
- Self-improving loop: The improve-and-rerun pipeline takes human annotations and eval failures, rewrites the testing prompt, and reruns — then shows you a side-by-side delta of what got better. Closed-loop optimization for UX testing.
- Evidence-grounded reports: Every friction point cites exact on-screen text, button labels, or screenshot steps. The ReportCritic agent enforces this — no vague "the UX could be better" hand-waving survives.
- Full observability from day one: Every LLM call, every eval, every persona session is traced to Arize AX via OpenTelemetry. We can debug a single persona's reasoning chain across 20+ browser steps.
What's next for UserSwarm
- Video replays: Record each persona's browser session as a video so product teams can watch the AI user struggle, not just read about it.
- Multi-device testing: Simulate mobile viewports, slow 3G connections, and tablet layouts — real users aren't all on MacBook Pros.
- Accessibility personas: Personas that use screen readers, keyboard-only navigation, and high-contrast mode to surface WCAG compliance issues.
- CI/CD integration: Run UserSwarm on every pull request — catch UX regressions before they ship, just like unit tests catch code regressions.
- Larger human baselines: Scale up Terac reviewer recruitment to build richer ground-truth datasets, driving the human-likeness eval from a sanity check to a statistically significant benchmark.
- Custom persona libraries: Let teams define their own user archetypes — "our power user," "a first-time visitor from organic search" — and reuse them across sprints.
Built With
- agentspan
- arize
- claudecode
- opentelemetry
- orkes
- playwright
- python
- sqlite
- tailwindcss
- teracmcp
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.