-
-
UPAI Main Landing Page
-

User Clicking the picture
-
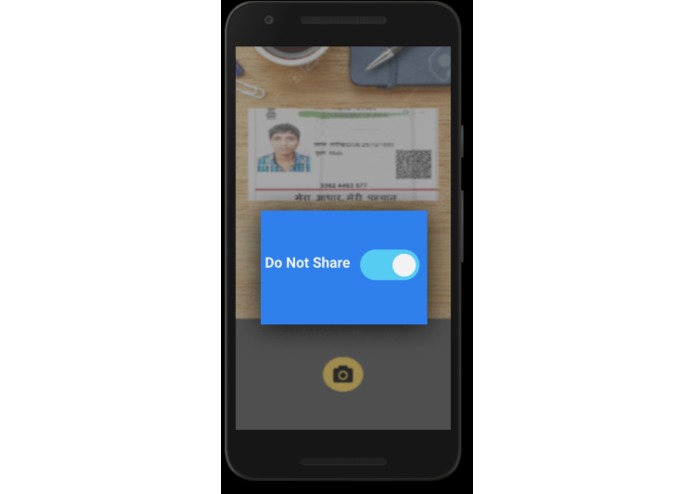
On-Device AI flags it as DO NOT SHARE
-
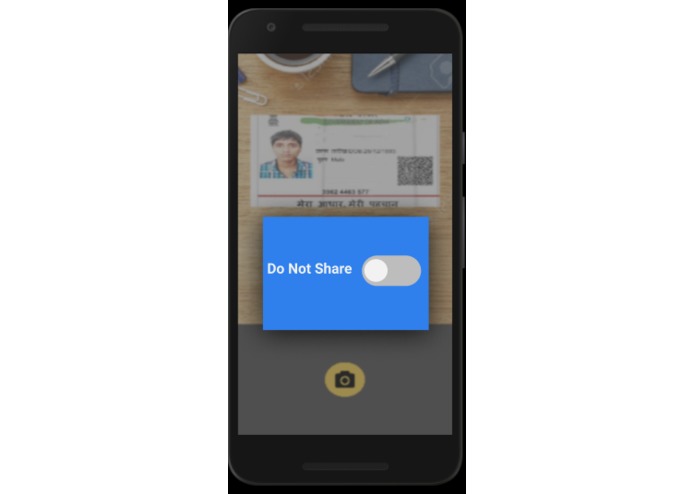
User can turn the DO NOT SHARE feature off




Inspiration
We live in an increasingly digital-driven world. It’s a world where our personal data is flowing freely online. Whether it’s information close to us such as our private images, official images, date of birth, private chats or even financial data, we find ourselves interfacing with the online world on a continuous basis. Irrespective of whether we understand how these services work around secure data on the internet, there exists a major worry over the possibility of that information and data getting hijacked for potential misuse.
"The Facebook incident is a lesson for all of us when it comes to being cyber safe. We don't realise how grave a threat is until we experience its consequences... if a tech giant like Facebook is vulnerable to such data breaches, then how can we ensure that our personal data is not being misused by the cyber criminals? At the time of stepping into digitalization, we can't afford to be vulnerable,"
What it does
Our UPAI model, which basically classifies the personal/official images and automatically flag it as DO NOT SHARE which although the user has control to turn it on. These flagged images go to a hidden folder where any third party app irrespective of permissions to access Gallery is not able to access these flagged items. In addition to image data, privacy for text data in the mobile can be achieved using NLP.
How we built it
We basically trained a CNN (Convolution Neural Network) model with pre-labelled data. Initially sample data is collected and then labelled. After this training is carried out. Once the model is trained to the desired accuracy , the model is deployed and then integrated with the existing mobile ecosystem.
Challenges we ran into
Collecting data and then labelling data is a big challenge. Also cleaning data seems to be time consuming. We worked as a team and then overcame these challenges in the hackathon.
Accomplishments that we're proud of
Training the model to the desired accuracy and then creating an initial concept within the stipulated time are the accomplishments which we are very proud of. Also we were able to reach the dimensions of Trustworthy AI such as Platform addressing Privacy and concern, including a Fallback mechanism and well separated data types.
What we learned
We have learned, that we need to have proper labelled data to achieve good accuracy. Also we learnt a good deal on how we can deploy the trained model along with integrating the same in mobile ecosystem.
What's next for User Privacy through AI
Collect more data, train the model to high accuracy. After this create a full fledged framework and then probably release it as Open Source for further usage. This can then be used by different OEMs, manufacturers and software developers.




Log in or sign up for Devpost to join the conversation.