-
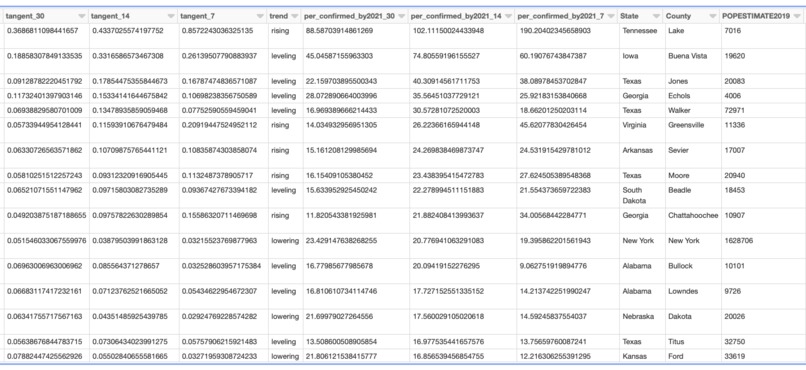
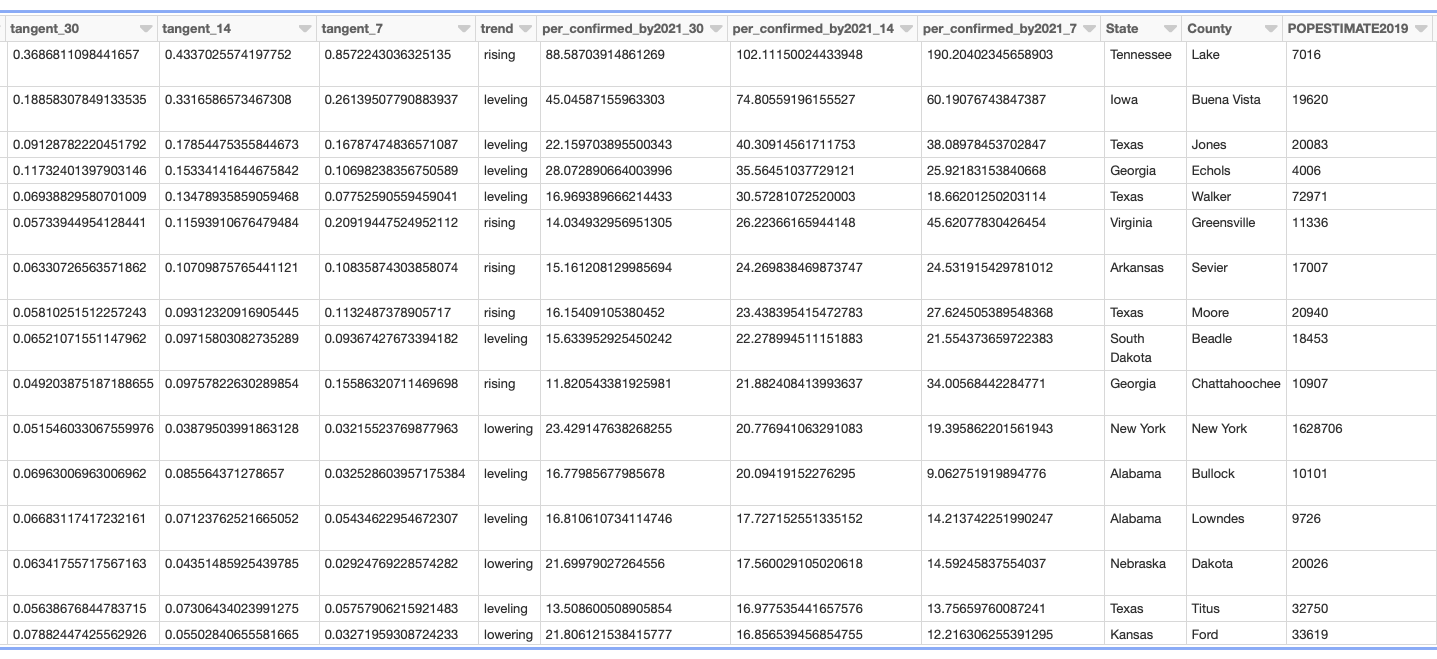
Some of the enhanced fields are: tangent_30, tangent_14, tangent_7 (rate slope based on time period), trend and per_confirmed_by2021 fields
Inspiration
Fight against COVID-19: I wanted to enhance an existing dataset with other local reference data to enable more insights based on COVID-19 data by Johns Hopkins CSSE
What it does
Using estimated population data it derives percent of population with based on confirmed cases per US county. As of v0.1 it uses the last 30, 14 and 7 date ranges to compute rate of increase and the slope to define "hot zones". It also projects the rate of spread for the three date ranges to forecast what percent of all residents will have been confirmed to be infected by 2021.
How I built it
I used Spark on Databricks (Scala APIs) to read the Databricks hosted copy of the COVID-19 data by Johns Hopkins CSSE and added a script to download the Census data by county with 2019 estimates from www.census.gov After some cleanup I joined them to add the 2019 estimated population to the COVID data. From there, compute percent confirmed, last X day infected, rate of infection using the slope per data range. Using the three rates it computes what percent of the county population will have been confirmed by 2021 if the rates were to remain the same - basic projection.
Challenges I ran into
Unfortunately I didn't have much time to look for other datasets. I'm sure there are other reference data that could have been to further enhance the data and enable even more insights.
What I learned
In more than 20 counties in the US the virus will reach to at least 15% of the population by 2021 with one of the three rates as of the data with last reporting of 06/07/2020
What's next for US COVID-19 Hot Zones and Trends with Census county data
v0.2 will add visualization to easily see regional trends v0.3 will use the other time series datasets: Global and the rest of US data (not only confirmed)

Log in or sign up for Devpost to join the conversation.