-
-
Login Screen
-
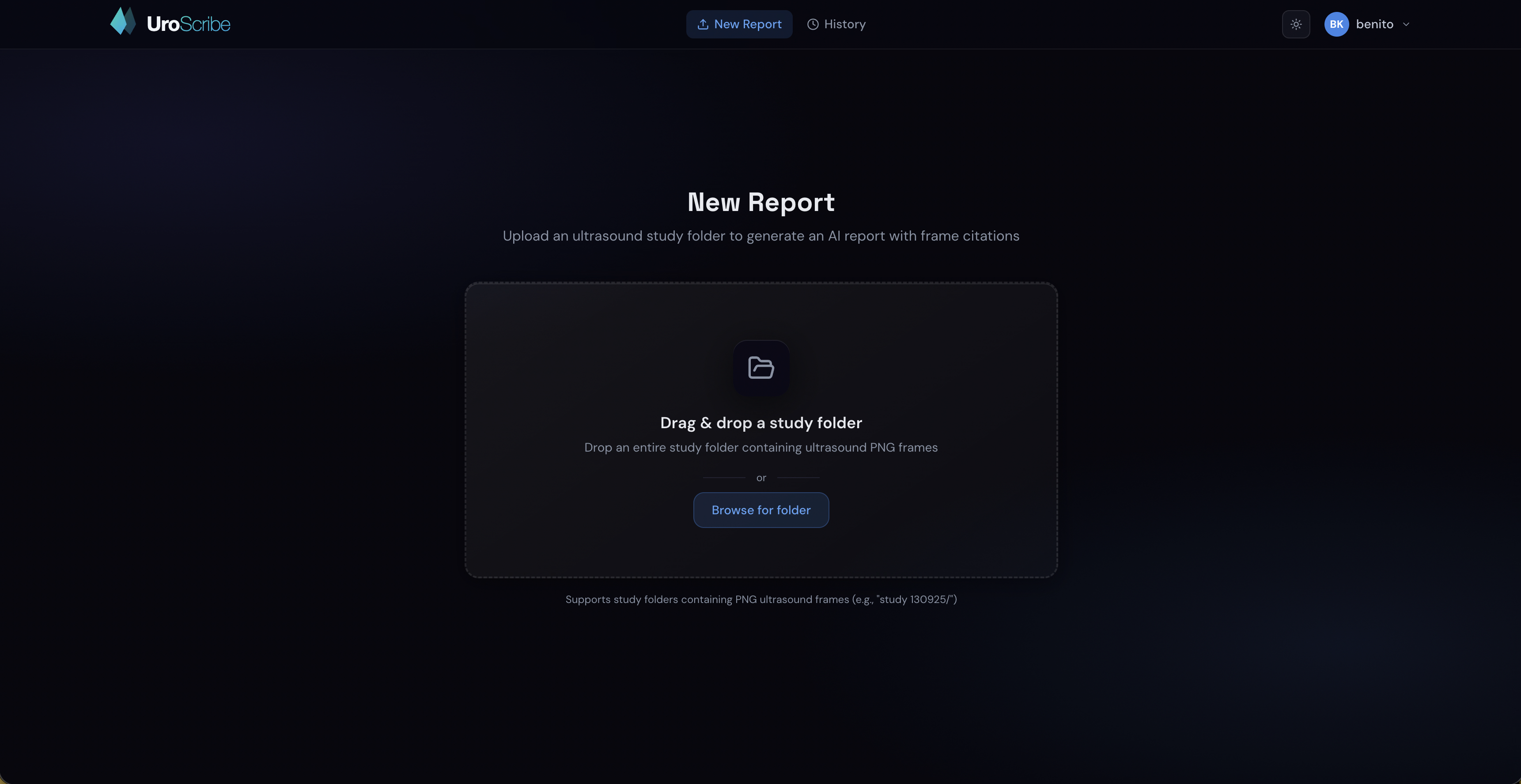
Upload Screen
-
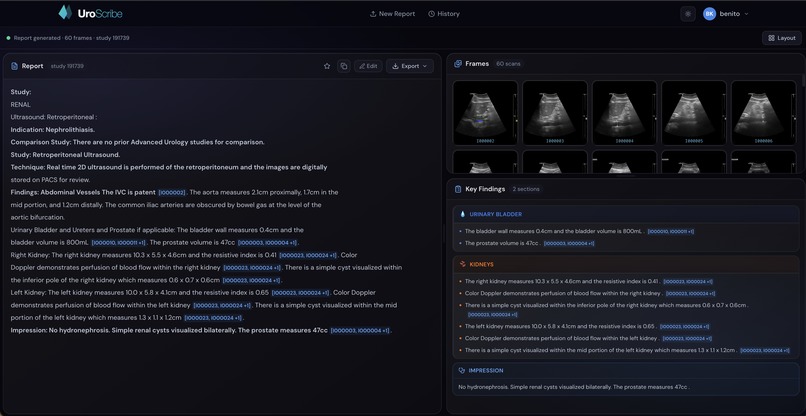
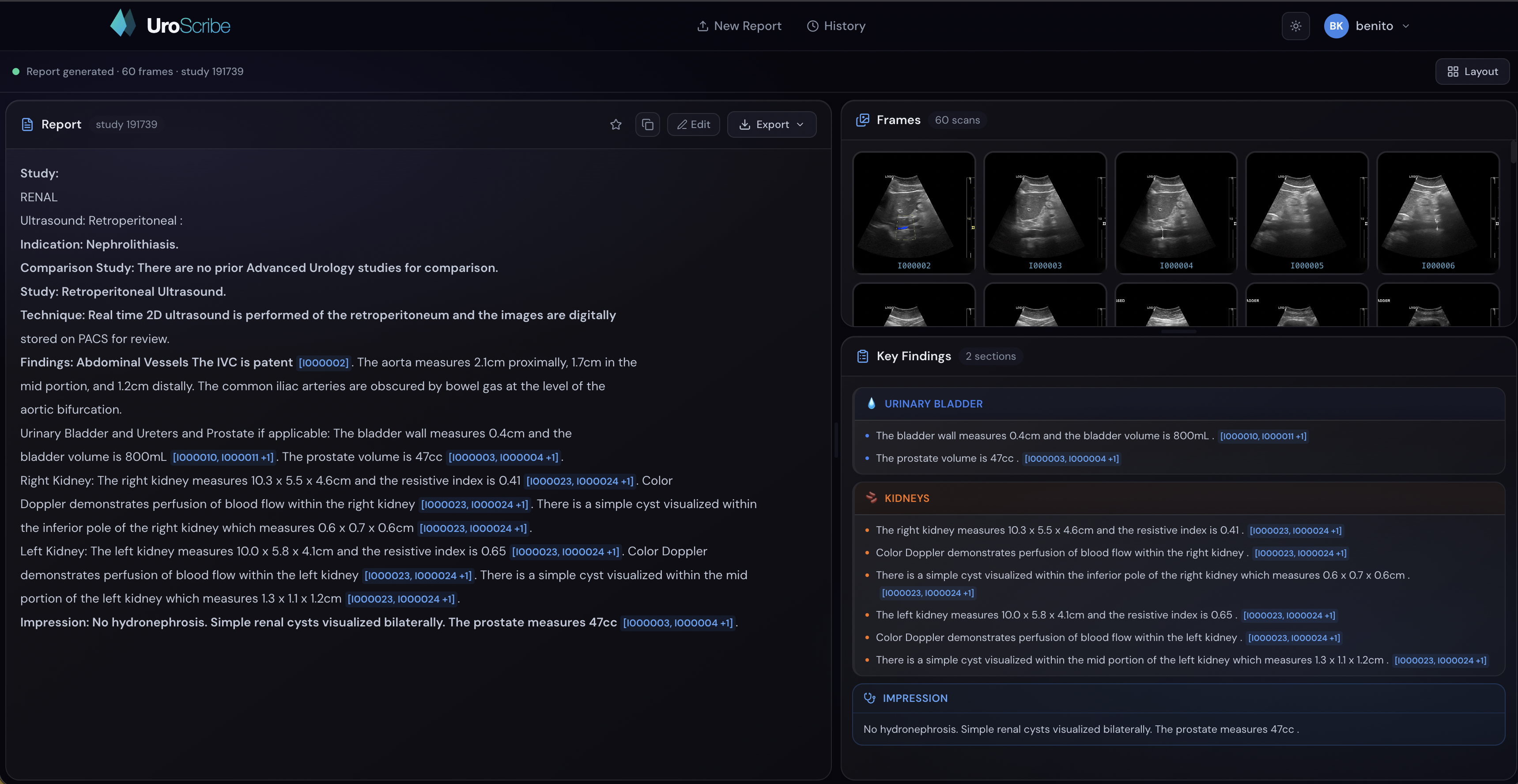
Standard view of the dashboard
-
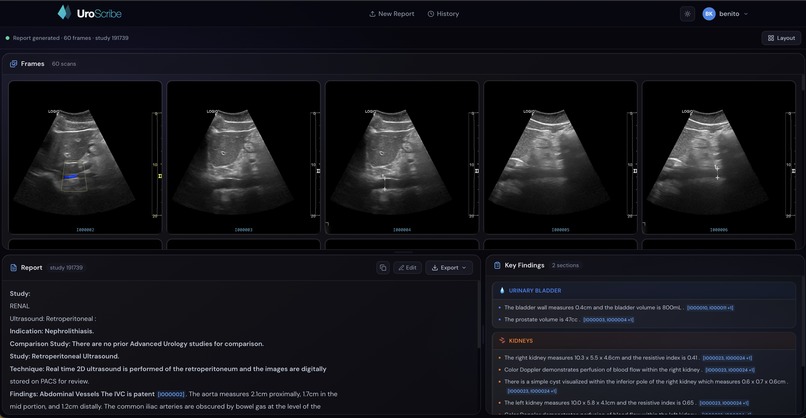
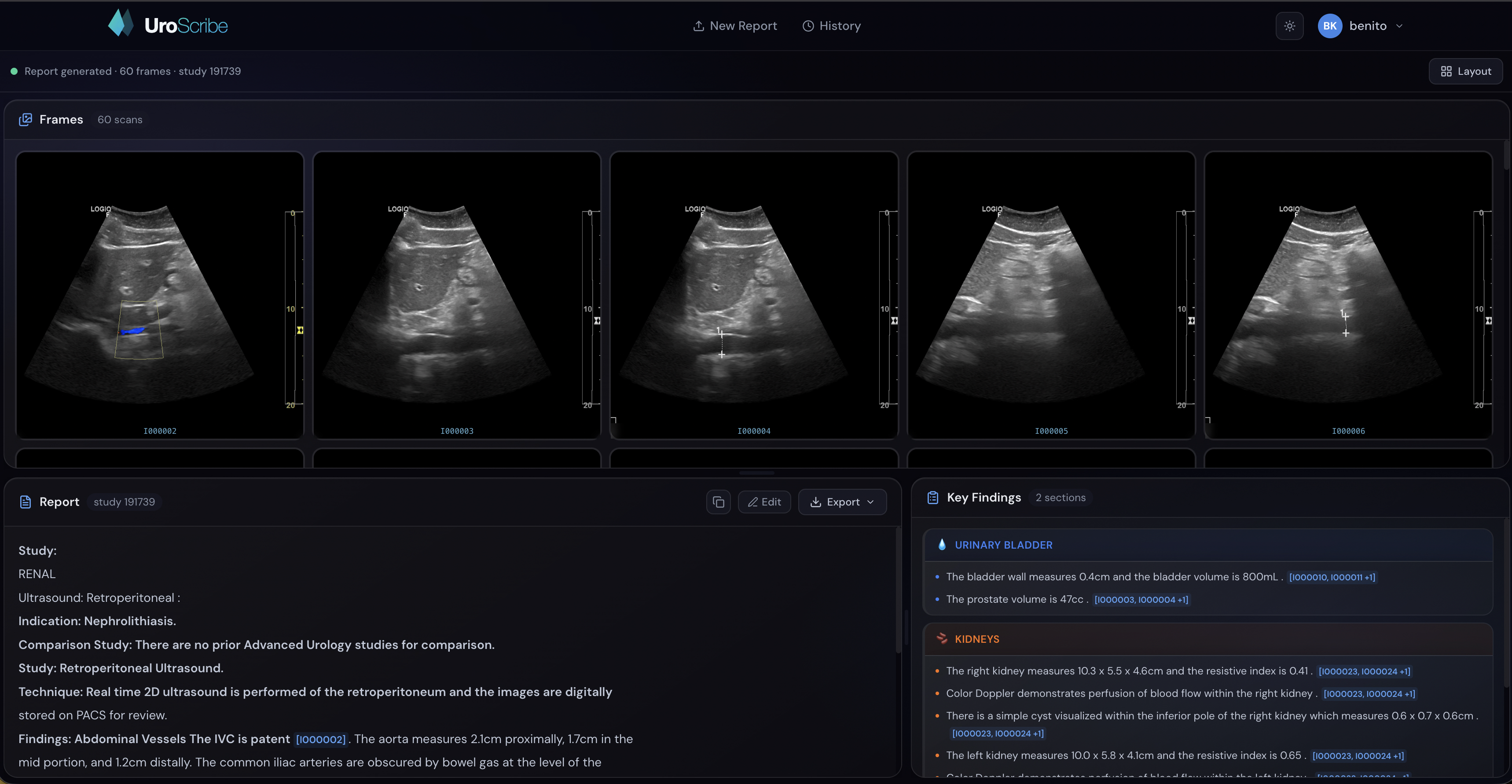
Image-focused view of the dashboard
-
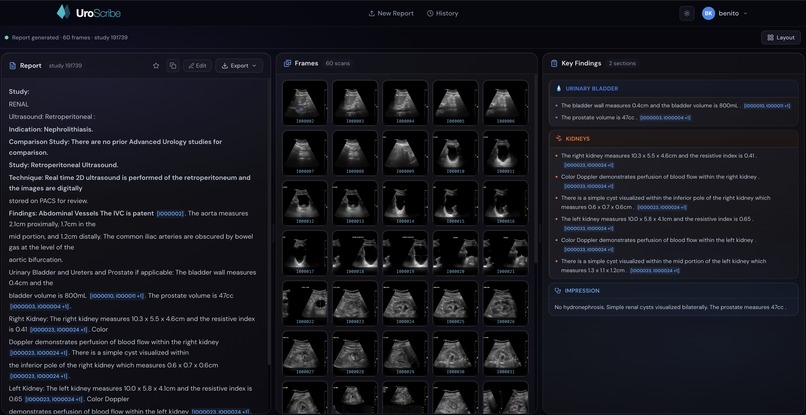
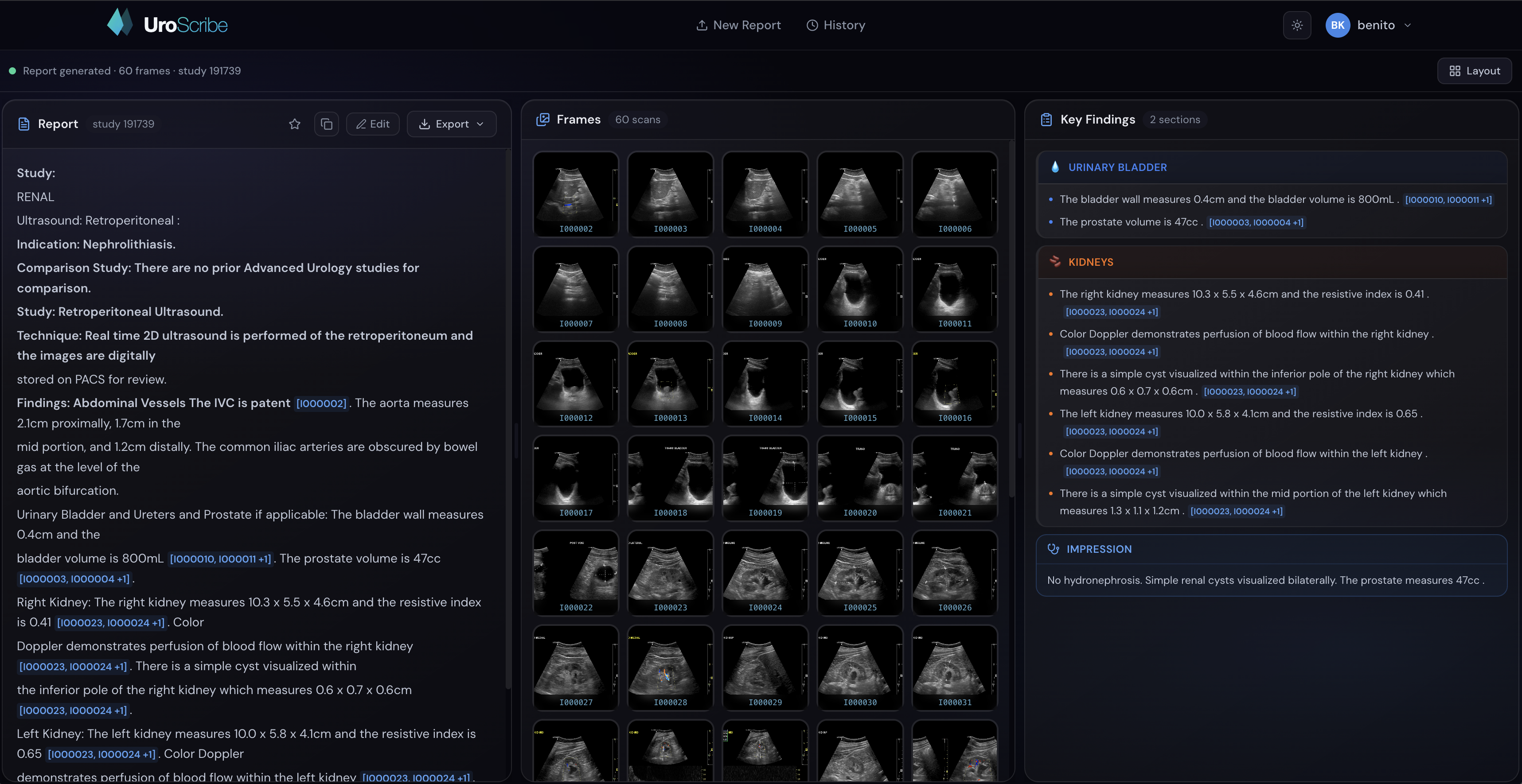
Analysis-focused view of the dashboard
-
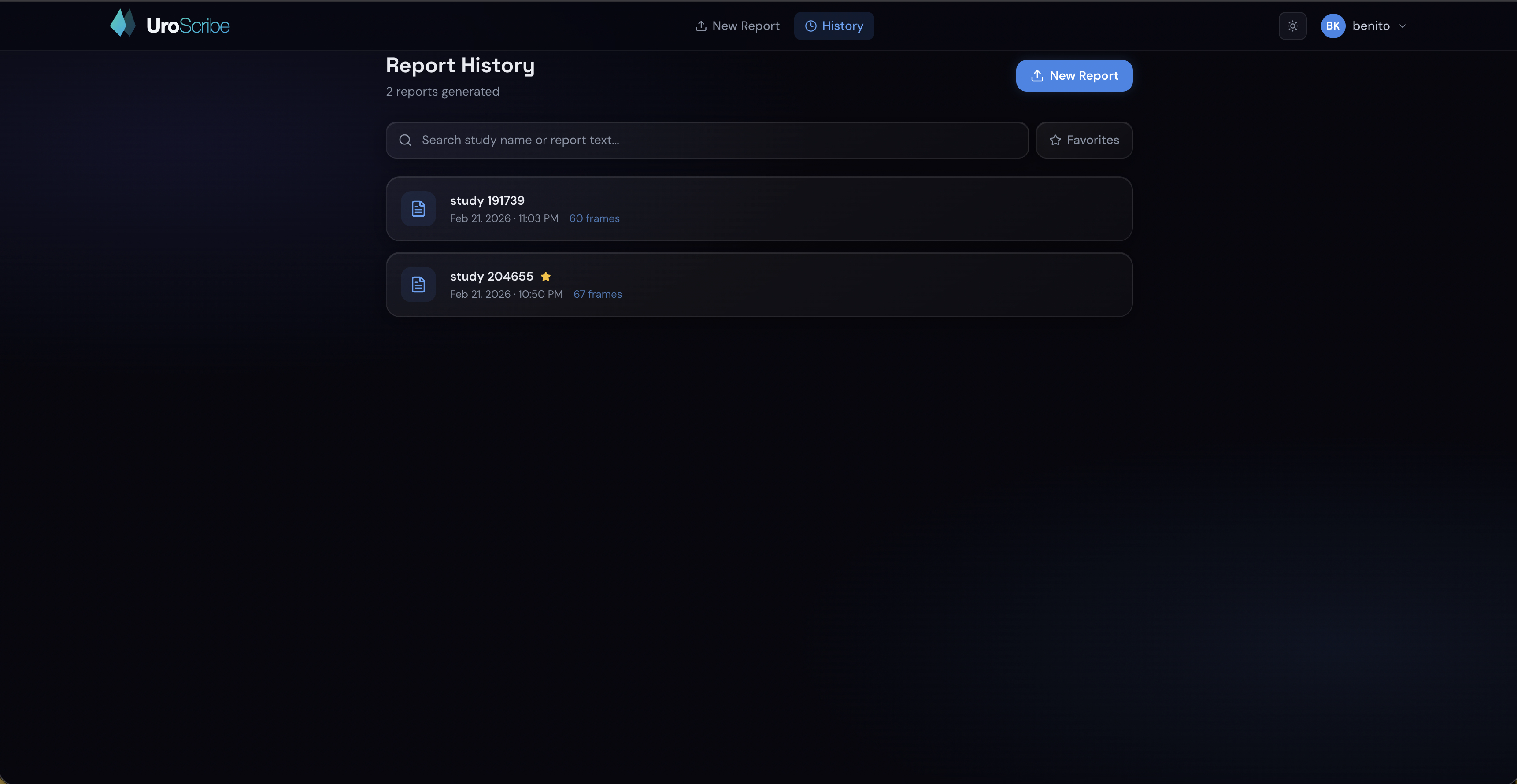
History Screen
Inspiration
Urologists spend a significant portion of their clinical time writing structured reports from ultrasound imaging — time that pulls them away from patient care. We wanted to see if we could automate that process end-to-end using modern medical vision-language models, turning a raw ultrasound image into a fully structured radiology report in seconds.
What it does
UroScribe takes urology ultrasound images as input and generates a structured, clinically formatted radiology report. A clean dashboard UI lets you upload images and instantly see the AI-generated findings, impressions, and recommendations — the same format a urologist would write by hand.
How we built it
We fine-tuned MedGemma-4B, Google's medical vision-language model, using QLoRA (4-bit quantization + LoRA adapters) on a curated dataset of urology ultrasound images paired with structured radiology reports. Training was done on high-performance GPU infrastructure (PACE ICE). The fine-tuned model is hosted on Hugging Face. The frontend and backend are both built with Next.js 14 (React + TypeScript + Tailwind CSS). Since real-time inference requires HPC-grade hardware (H200 GPU), the web app serves from a pre-generated cache of 66 urology ultrasound studies — the same outputs produced by the fine-tuned MedGemma model running on Georgia Tech's PACE ICE cluster.
Challenges we ran into
- During training, we were limited to processing a maximum of 20 images per study before hitting out-of-memory errors on the GPU. We resolved this by implementing Flash Attention, which significantly reduced memory overhead and allowed us to train stably across full batches.
- Fine-tuning a vision-language model for a highly specialized medical subdomain required significant prompt engineering and iteration to get clinically coherent output.
- Working with medical imaging data introduced unique preprocessing and formatting constraints.
Accomplishments that we're proud of
- The fine-tuned model achieved a 95.5% BiomedCLIP cosine similarity score to the ground truth reports
- Successfully fine-tuned a medical VLM to produce structured, coherent urology reports from raw ultrasound images
- Built a clean end-to-end pipeline from image upload to formatted report output
- The generated reports follow real clinical structure with findings, impressions, and recommendations
What we learned
Fine-tuning a medical foundation model for a narrow clinical domain is surprisingly effective with limited data — our LoRA adapter on ~500 studies achieved 95.5% BiomedCLIP semantic similarity against radiologist reports. The harder problem was the citation layer: mapping free-text findings back to the exact ultrasound frame that supports them required building a custom OCR-based frame label extraction and semantic matching pipeline. On the product side, we learned how to design a demo that feels real-time despite inference taking minutes on an H200.
What's next for UroScribe
Expanding the training dataset, reducing inference latency, and exploring integration into real clinical workflow tooling for urology practices.
Built With
- hugging-face
- medgemma
- next.js
- pace
- peft
- python
- pytorch
- qlora
- tailwind
- transformers
- typescript


Log in or sign up for Devpost to join the conversation.