-
Grafana
-
testsuite
-
CI
Inspiration
We wanted to go beyond "it works on my machine." The hackathon quest structure challenged us to build a URL shortener that doesn't just shorten links. It survives failures, monitors itself, and recovers automatically. The goal was to treat a simple CRUD app like a production system and learn what that actually takes.
What it does
A full-featured URL shortener API with:
- 17 REST endpoints for users, URLs, and click-tracking events
- Chaos engineering: a
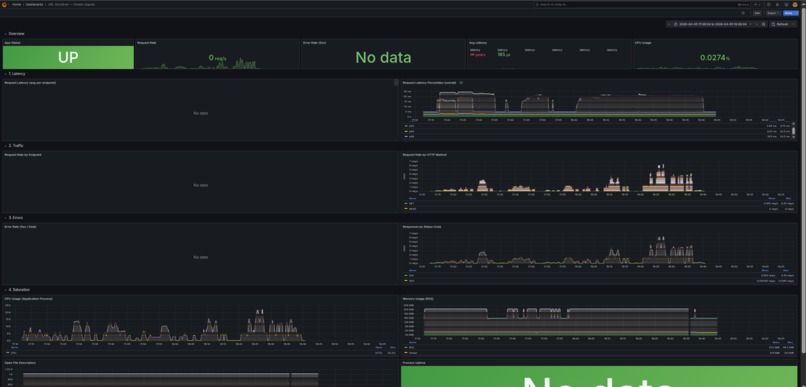
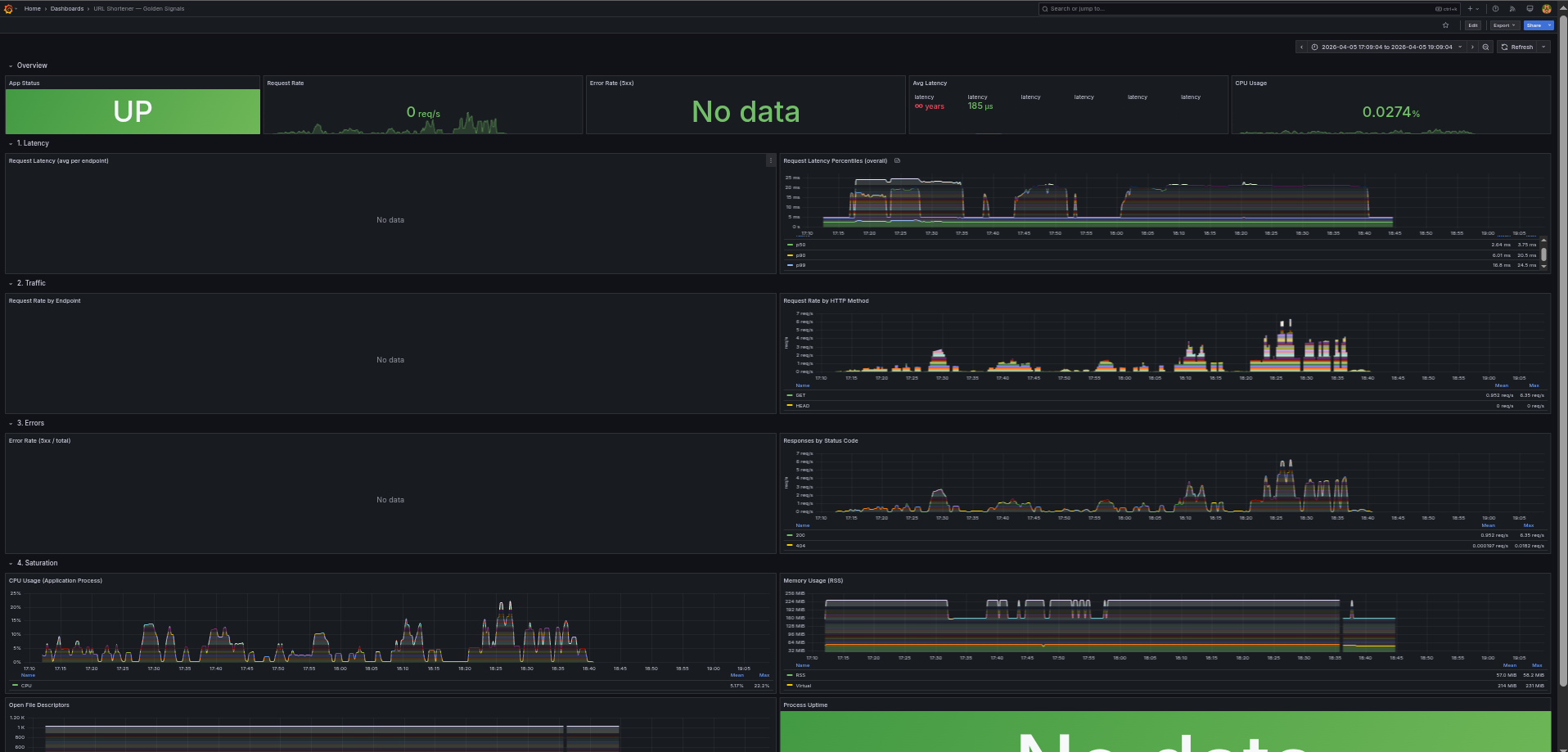
/chaosendpoint that deliberately crashes the server to prove it recovers - Self-monitoring: Prometheus metrics, 4 alert rules, Alertmanager → Discord notifications, and Grafana dashboards with runbook references
- Structured JSON logging with a live
/logsendpoint for real-time inspection
How we built it
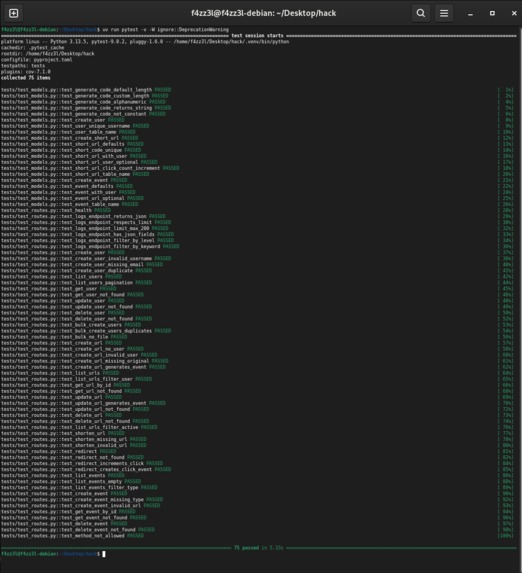
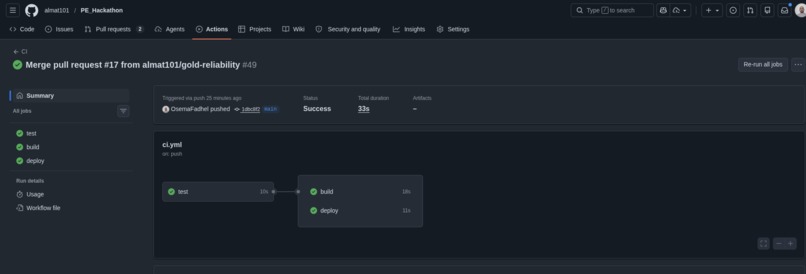
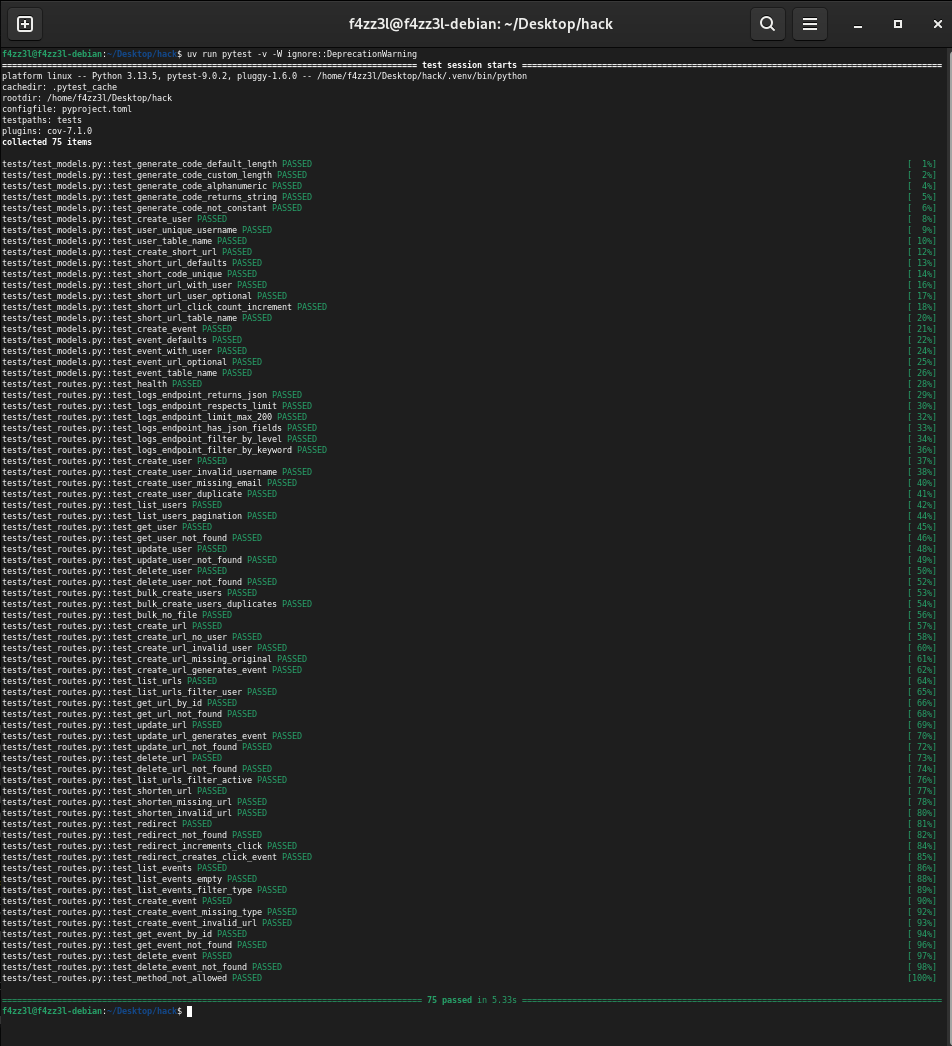
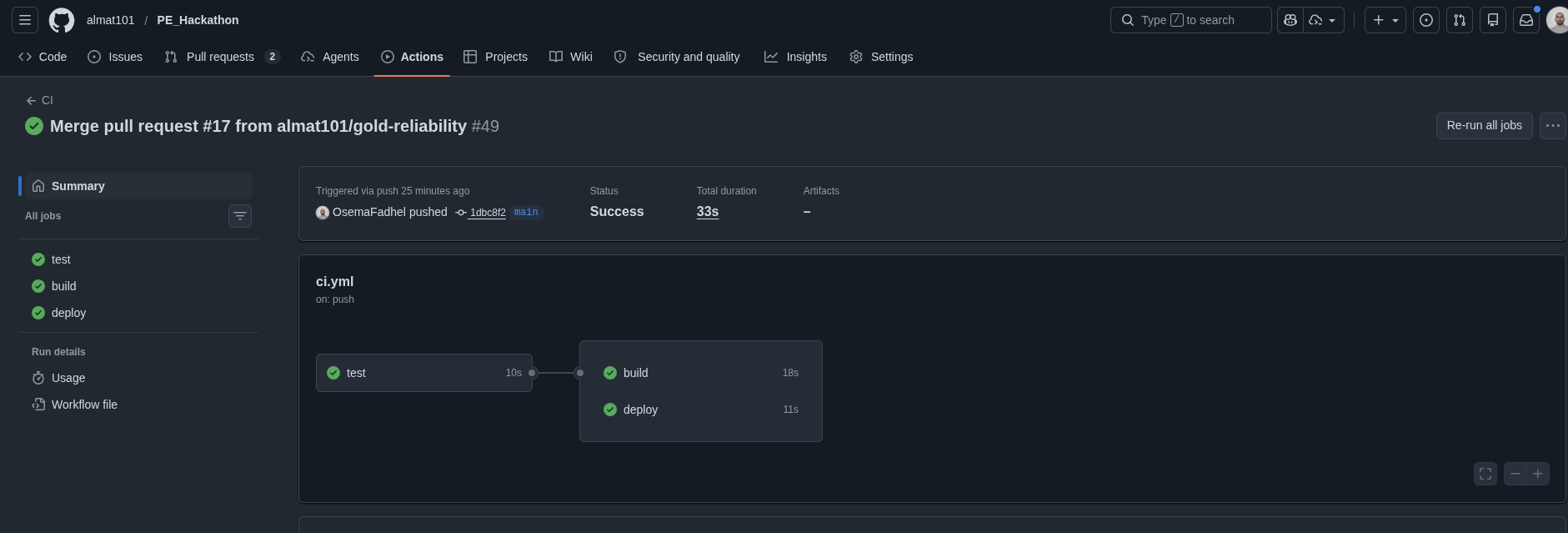
The stack is Flask + Gunicorn behind Nginx, with PostgreSQL for storage, all orchestrated in Docker Compose (7 services total). CI/CD runs through GitHub Actions: tests with a 70% coverage gate, Docker image builds with BuildKit caching, and SSH deployment to a DigitalOcean droplet.
We started with the core API, then layered reliability on top: health checks, connection pooling, per-request database lifecycle, graceful error handling, and finally the full observability stack. Grafana is auto-provisioned with datasources (Prometheus + Alertmanager) and a Golden Signals dashboard covering Latency, Traffic, Errors, and Saturation. Load testing with k6 validated that the system handles 200 concurrent users with sub-10ms p95 latency (2 replicas).
We also built an RCA drill playbook with 3 simulated incidents (ServiceDown, HighErrorRate, LatencySpike) so the team can practice diagnosing failures using the dashboard before real incidents happen.
Challenges we ran into
- Gunicorn as PID 1: Getting the chaos endpoint to actually kill the container required understanding that
os.kill(1, SIGTERM)only works when Gunicorn is PID 1. Shell wrappers swallow the signal. - Database connection management: Stale connections from the pool caused intermittent 500s. Solved with per-request connect/disconnect hooks and
stale_timeout=300. - 1 vCPU bottleneck: Load tests on the droplet showed 5.4x lower throughput than local. CPU, not memory or I/O, was the constraint. Horizontal scaling (2 replicas) with Nginx round-robin was the fix.
- Test isolation: SQLite for tests vs. PostgreSQL in production meant some ORM behaviors differed. We had to carefully design the
DatabaseProxyswap pattern.
What we learned
- Documentation is a feature. Writing runbooks and capacity plans forced us to actually understand our own system's limits.
- Chaos testing builds confidence. Breaking the system on purpose revealed recovery gaps we never would have found otherwise.
Built With
- alertmanager
- digitalocean
- docker
- docker-compose
- flask
- github-actions
- grafana
- gunicorn
- k6
- nginx
- peewee
- postgresql
- prometheus
- python
- uv


Log in or sign up for Devpost to join the conversation.