-
-
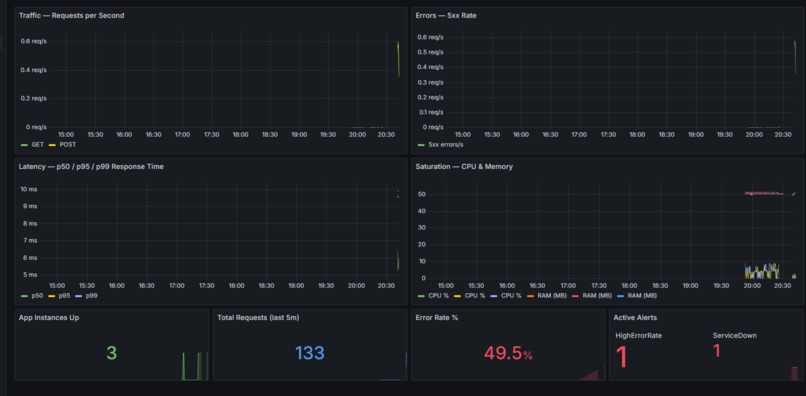
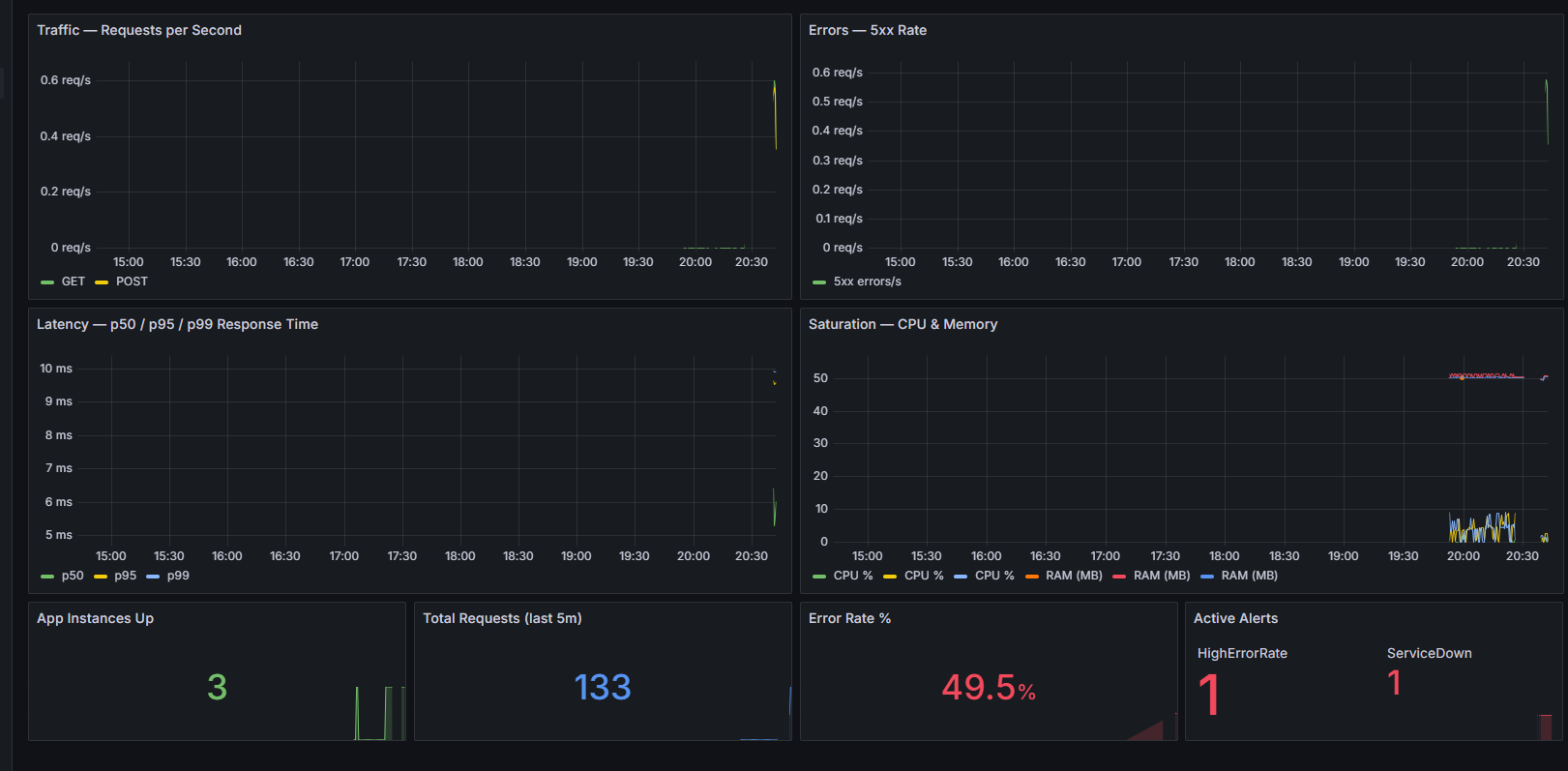
incident-gold-dashboar
-
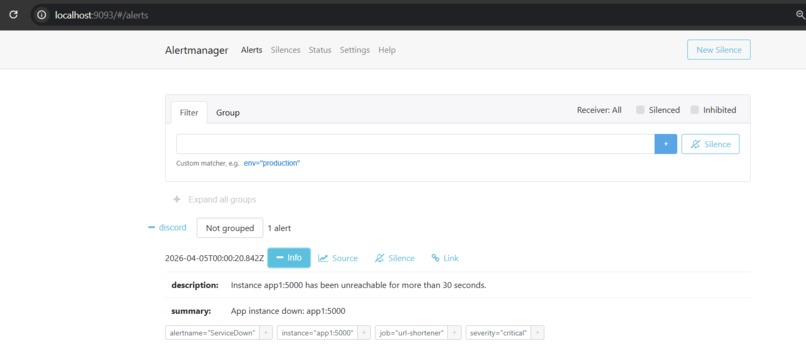
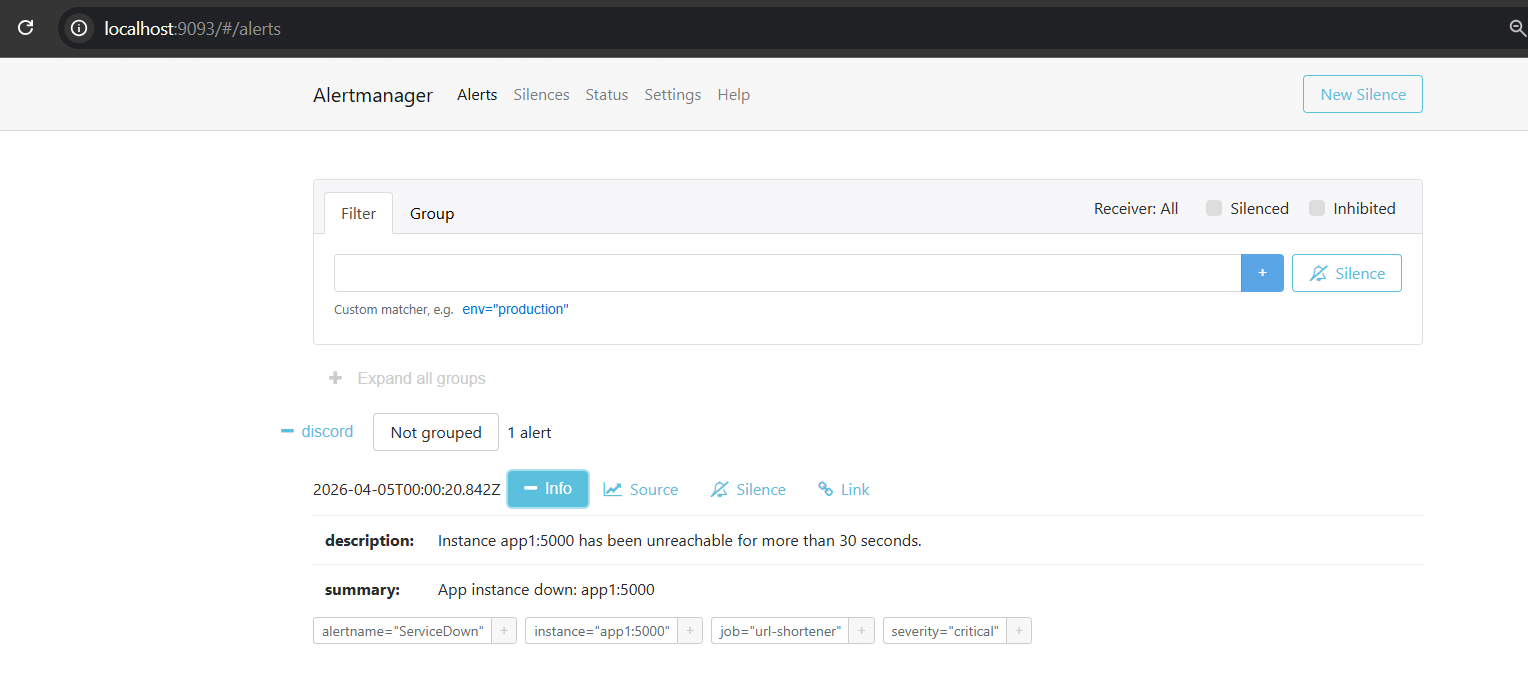
incident-silver-alertmanager
-
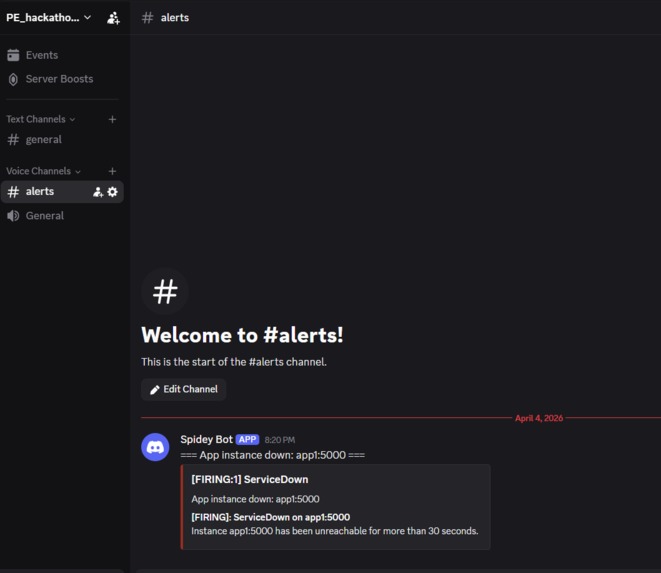
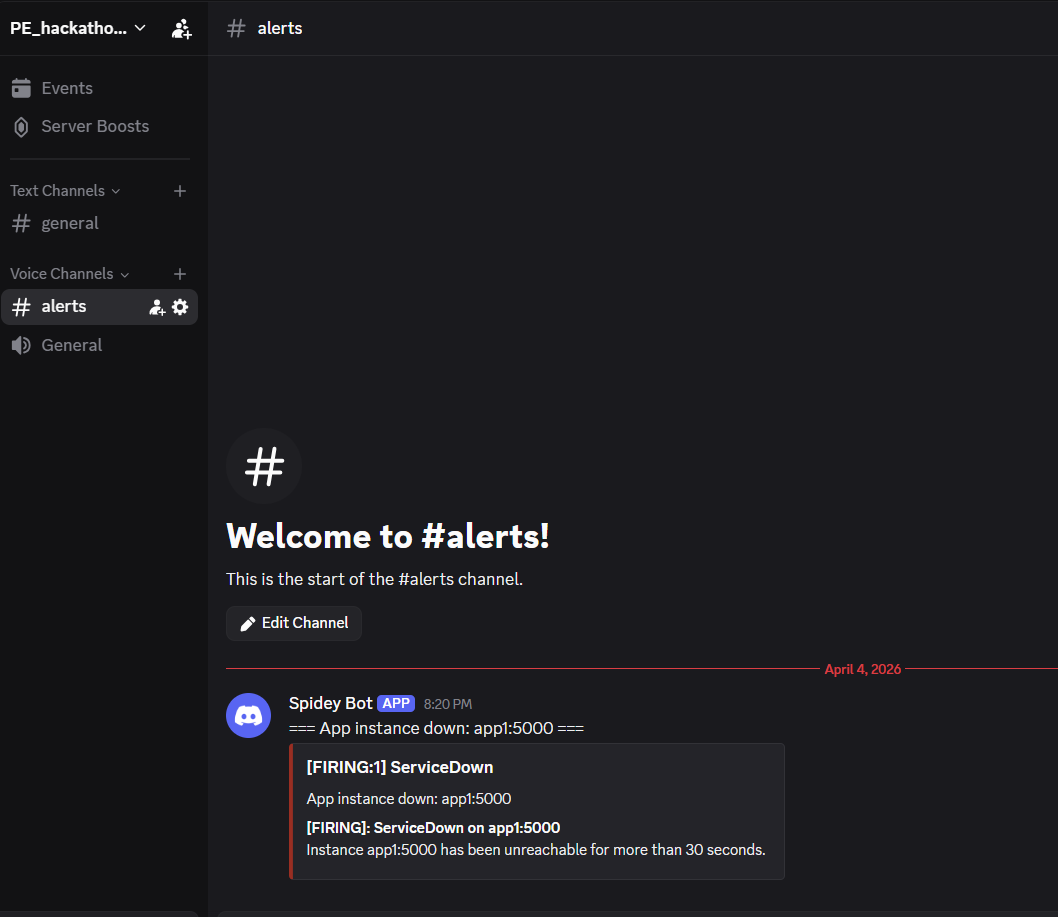
incident-silver-discord-alert
-
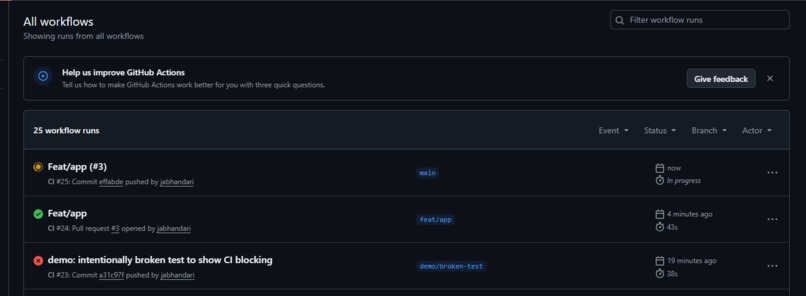
silver-blocked-deploy.png
-
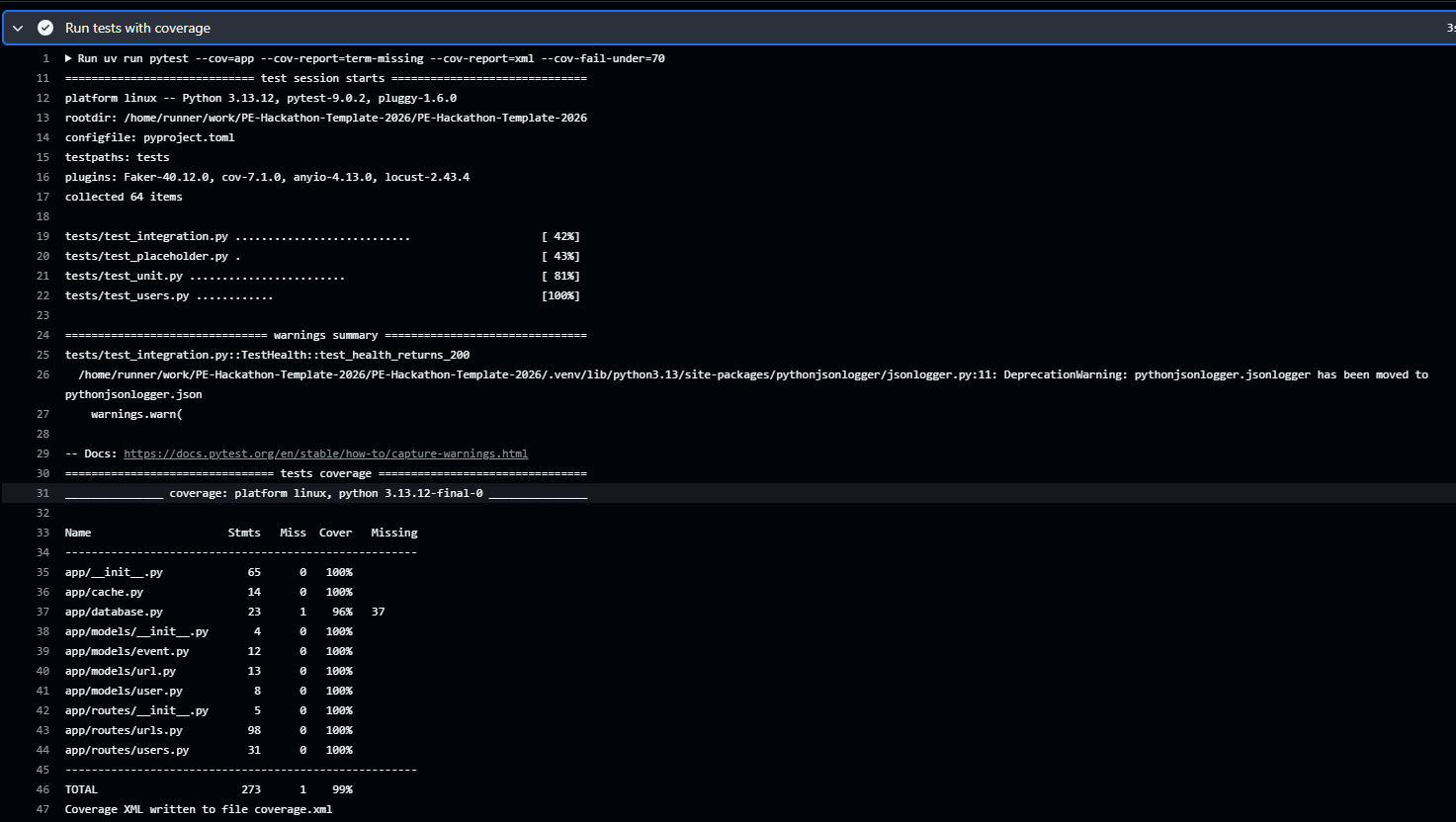
silver-coverage-table.png
-
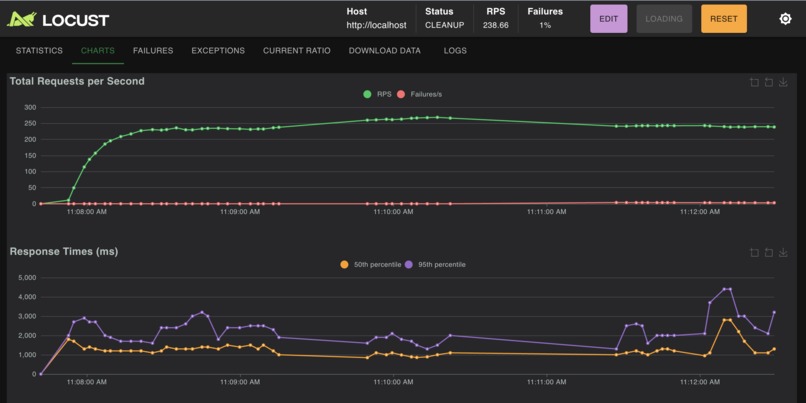
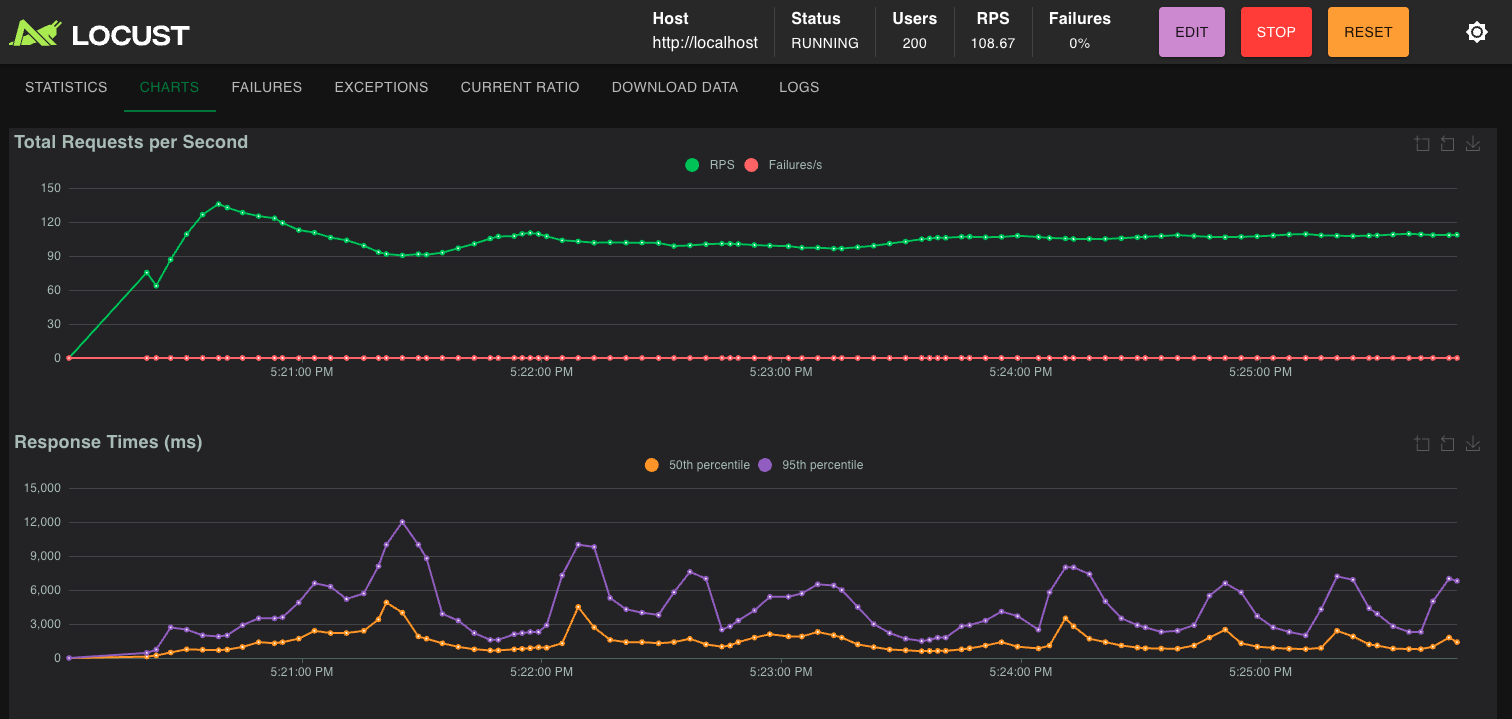
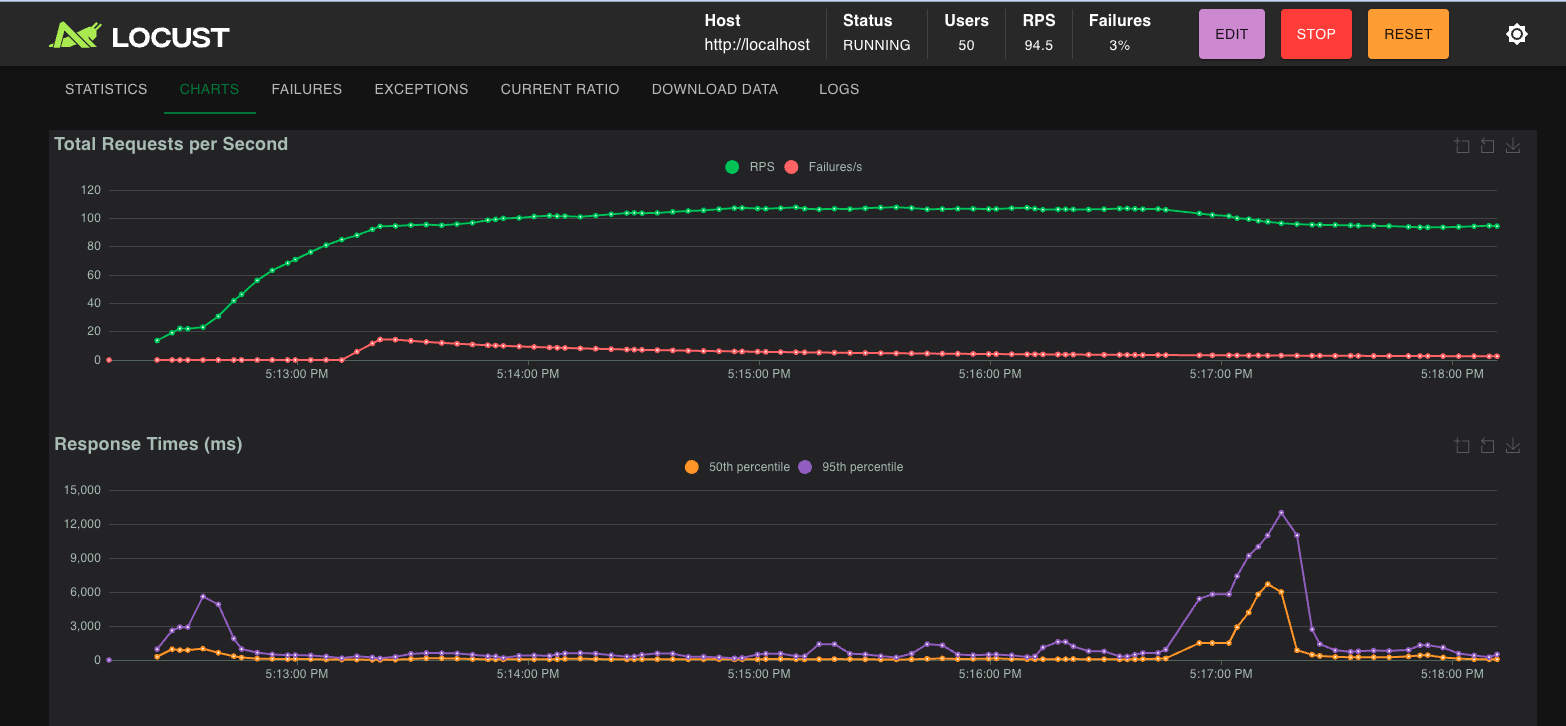
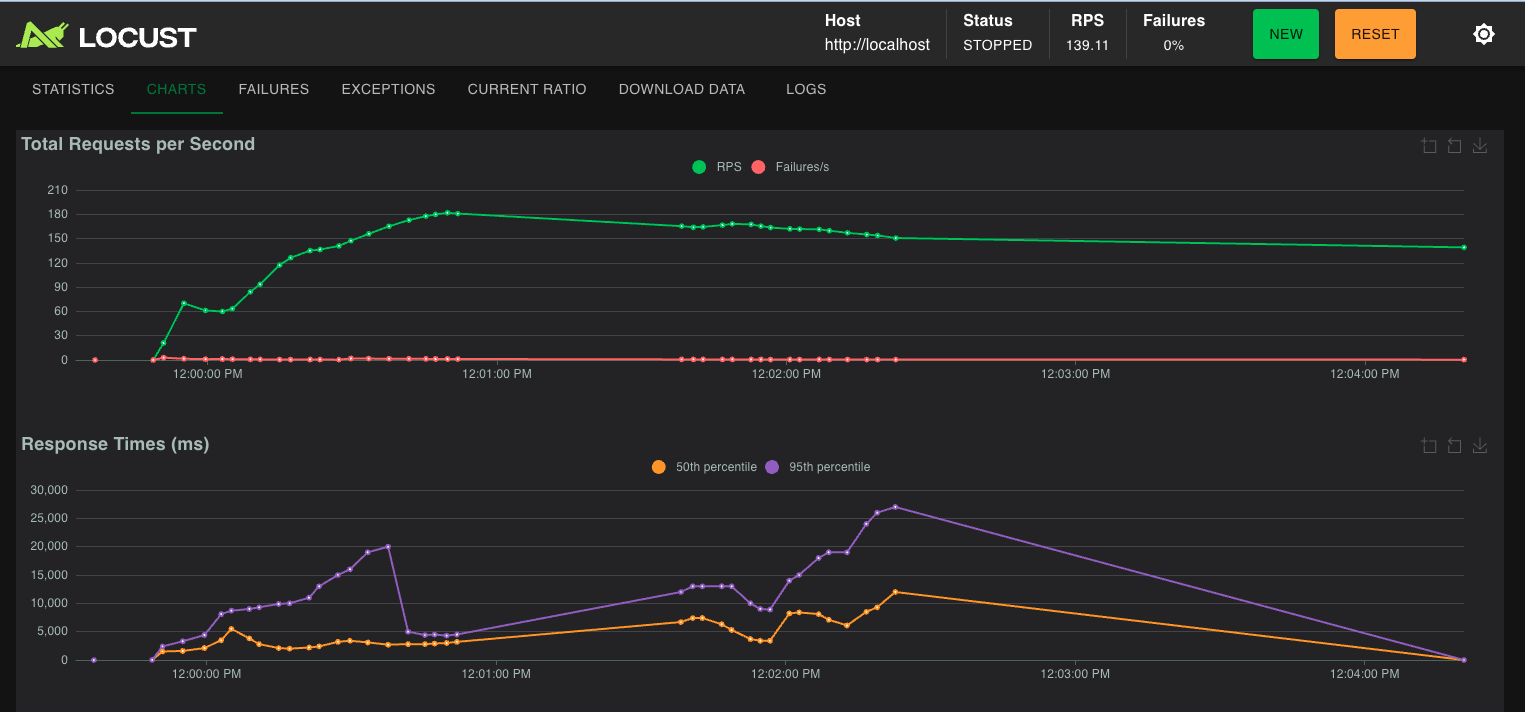
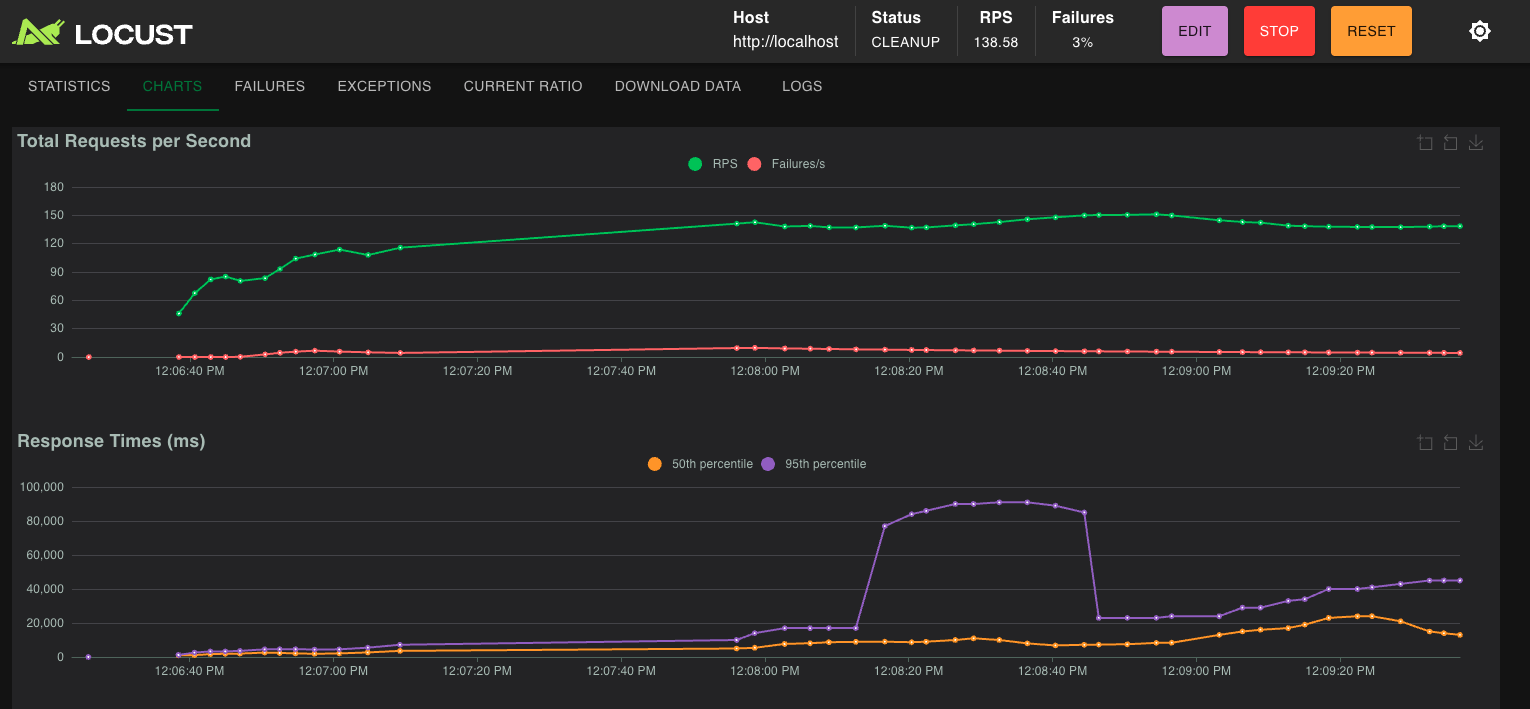
silver-locust-200-users-after
-
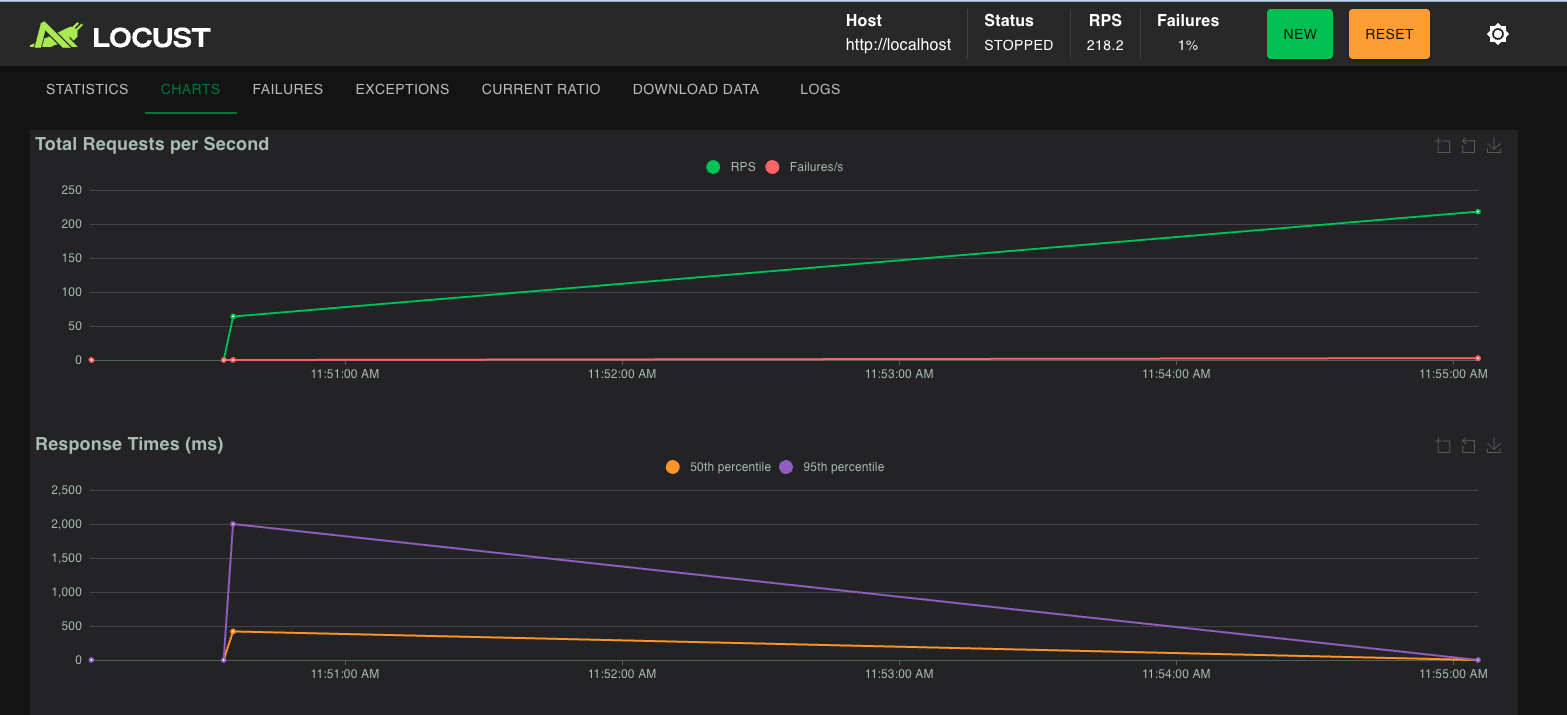
silver-locust-200-users-before
-
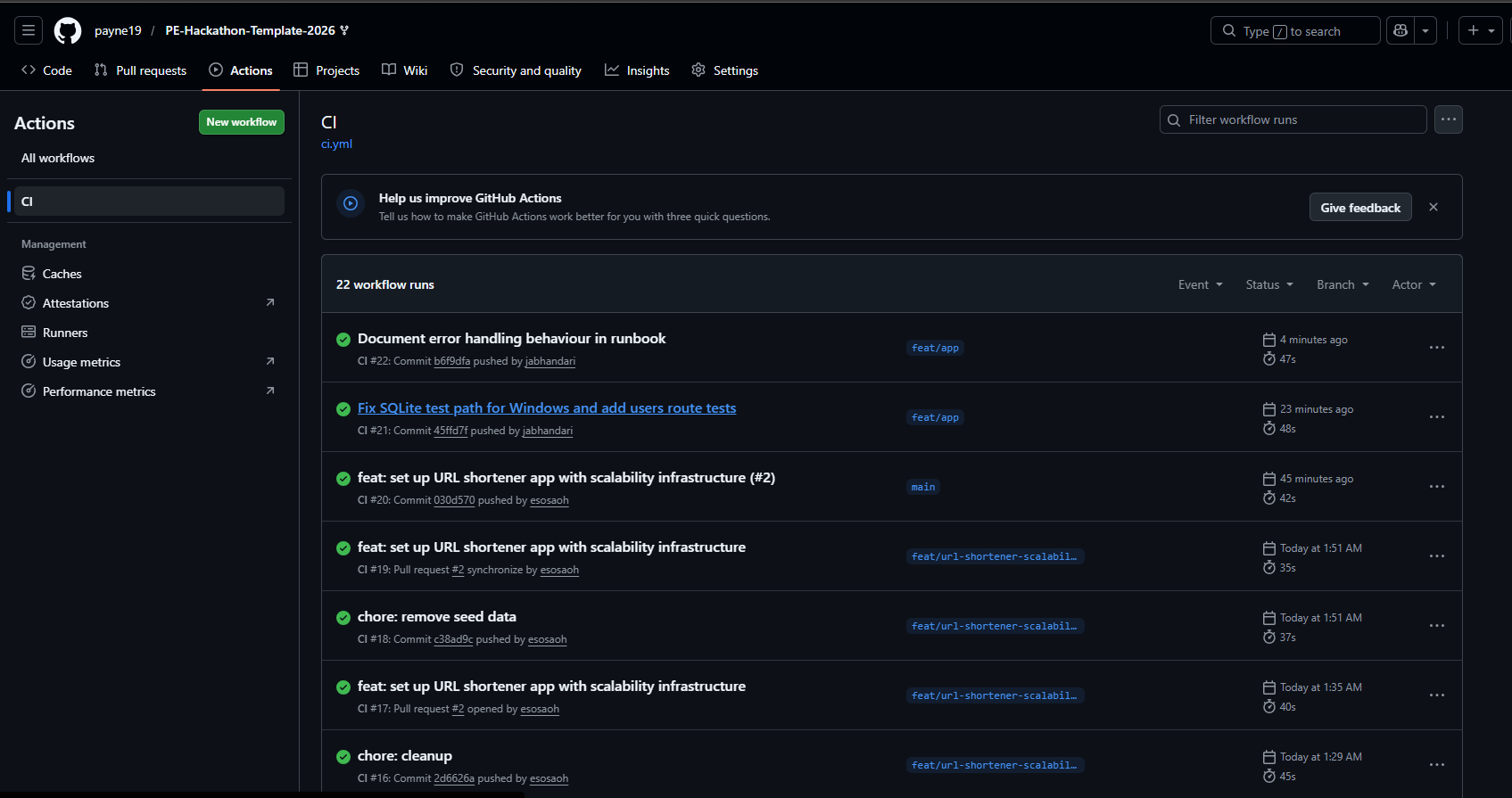
bronze-ci-green.png
-
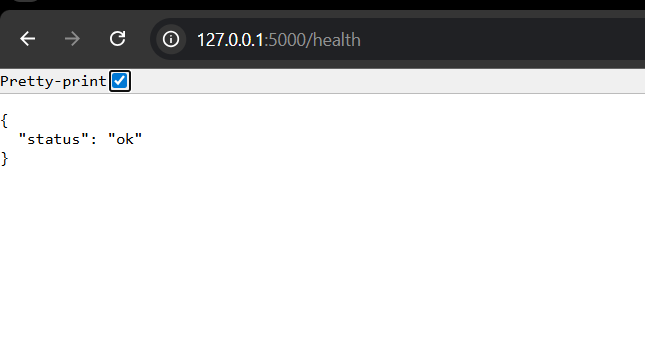
bronze-health-check.png
-
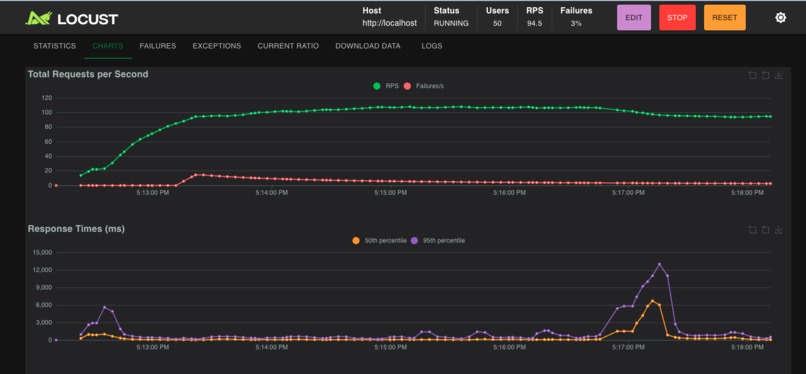
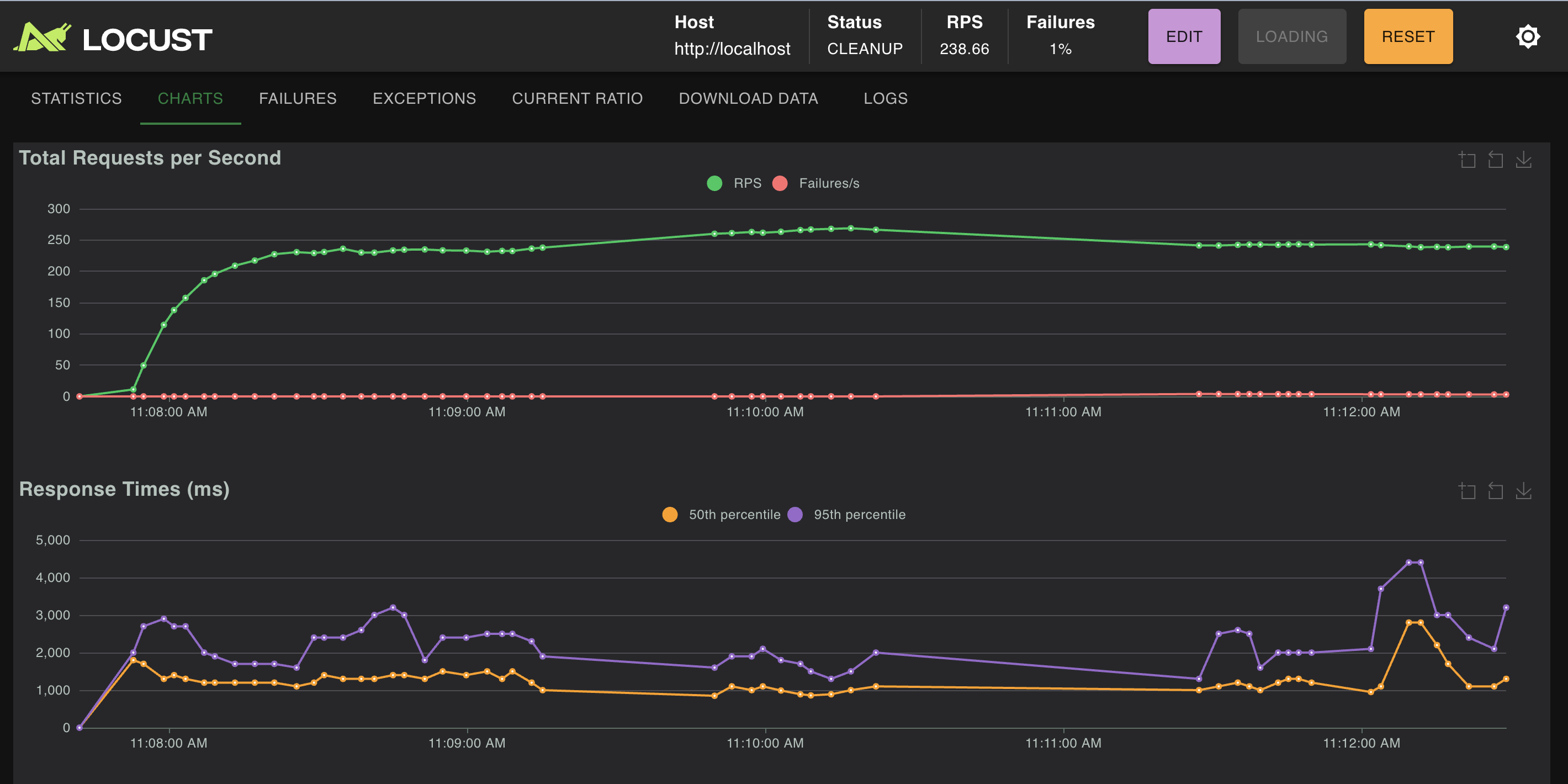
bronze-locust-50-users
-

gold-graceful-failure
-
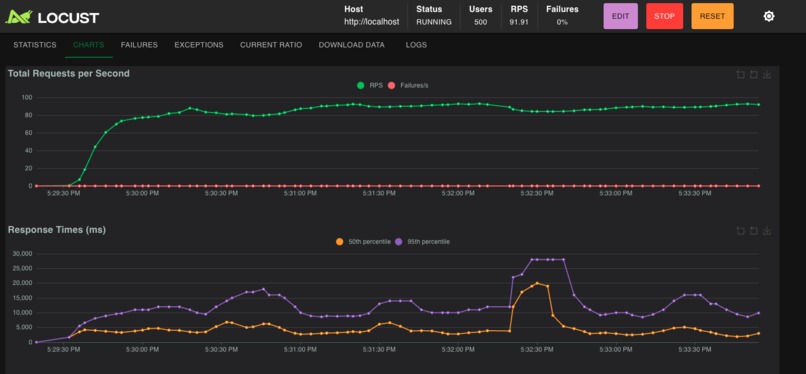
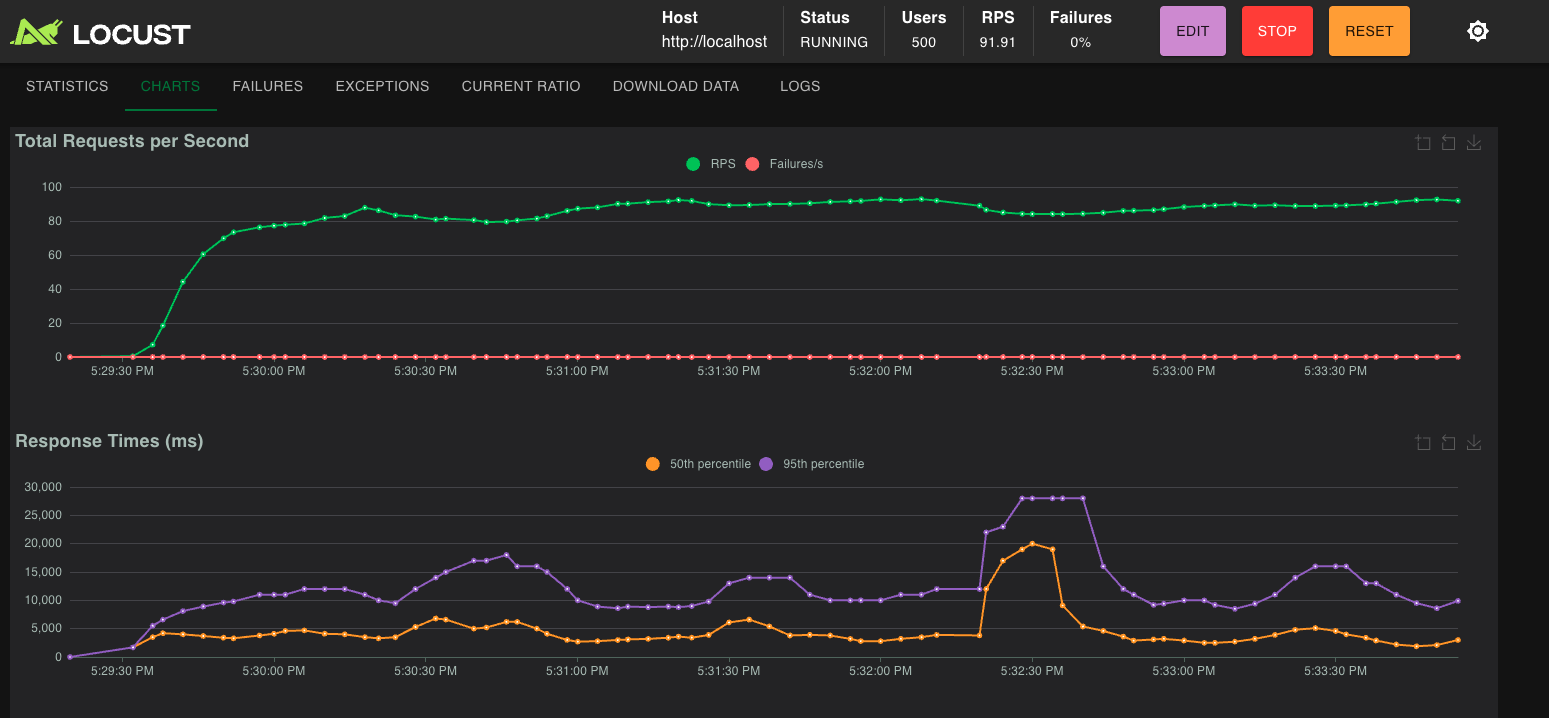
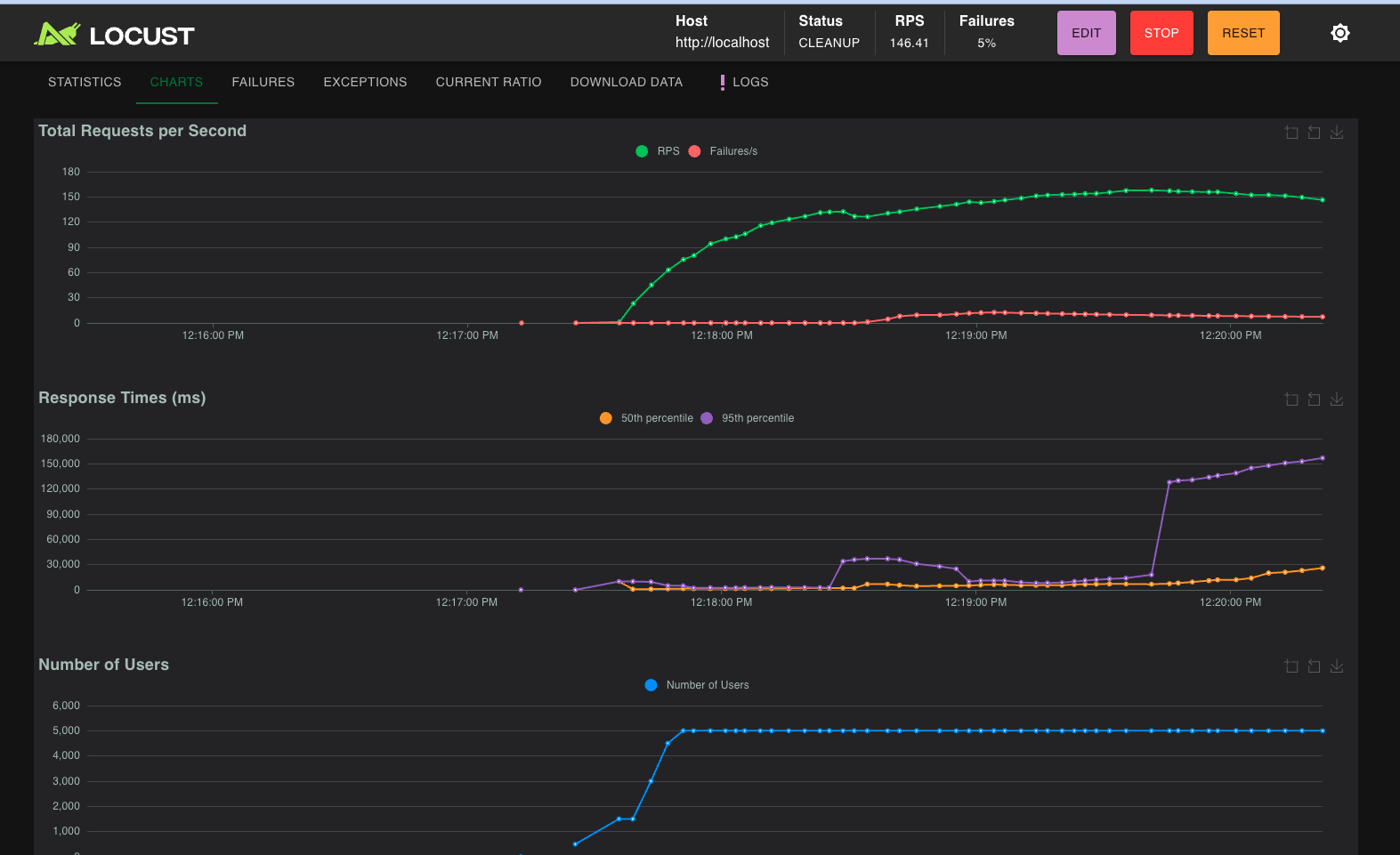
gold-locust-500-users-after
-
gold-locust-500-users-before
-
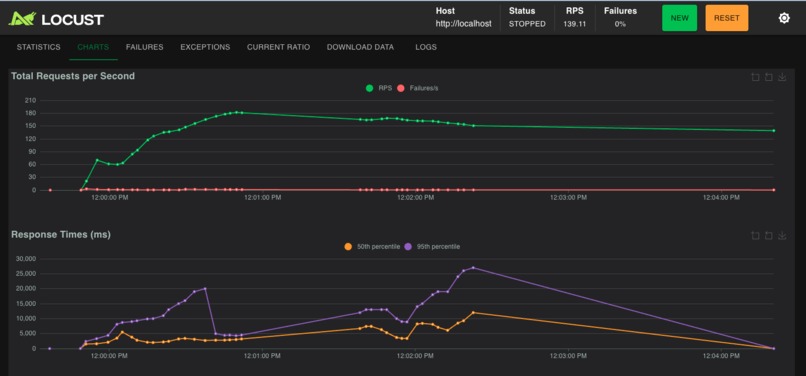
gold-locust-1000-users-after
-
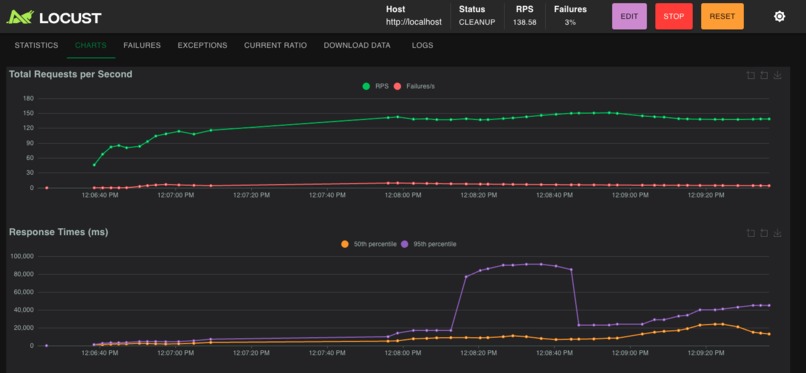
gold-locust-2000-users-after
-
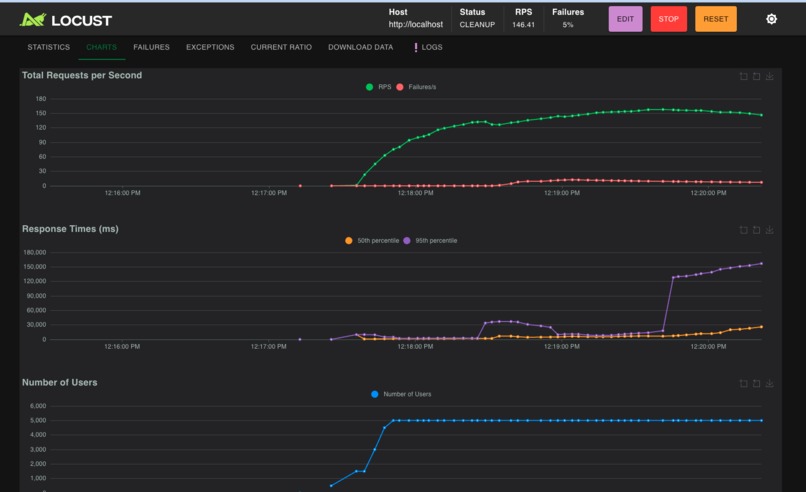
gold-locust-5000-users-after
-

incident-bronze-logs
-
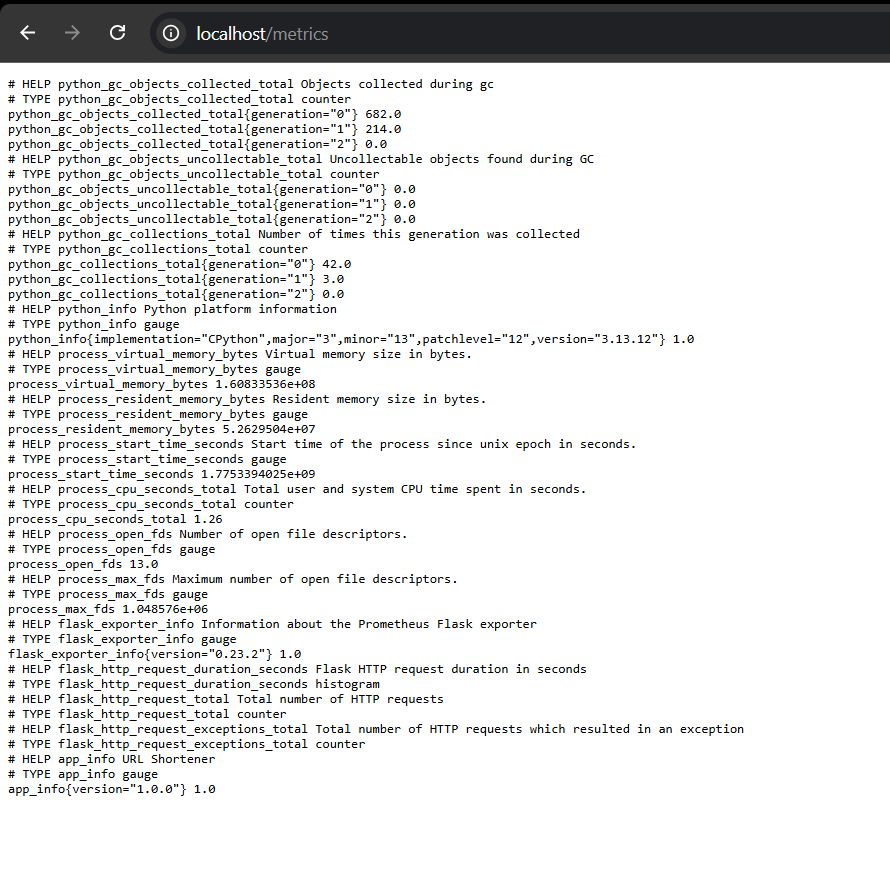
incident-bronze-metrics


A production-grade URL shortener with load balancing, caching, connection pooling, observability, alerting, resilience, and CI-enforced reliability.
Inspiration
Most hackathon projects are built to work once. Production Engineering is about building systems that keep working when things go wrong: traffic spikes, dependency failures, bad inputs, and 3am incidents.
We wanted to build something that reflects what real infrastructure work looks like and designing a system that is observable, scalable, fault-tolerant, and deployable.
A URL shortener felt like the perfect challenge: simple enough for anyone to understand instantly, but deep enough to expose real bottlenecks across the full stack.
What it does
This project is a production-grade URL shortener designed like a real service you’d be comfortable handing to an on-call engineer.
Users can:
- Submit long URLs and receive short, shareable links
- Visit short links and get redirected instantly
- Benefit from fast response times through caching and optimized backend handling
But the real focus is what happens behind the scenes:
- Traffic is balanced across multiple app replicas
- Redis speeds up repeated redirects
- PgBouncer protects the database under concurrent load
- Prometheus + Grafana provide live observability
- Alertmanager sends incident alerts directly to Discord
- Containers automatically recover from failure
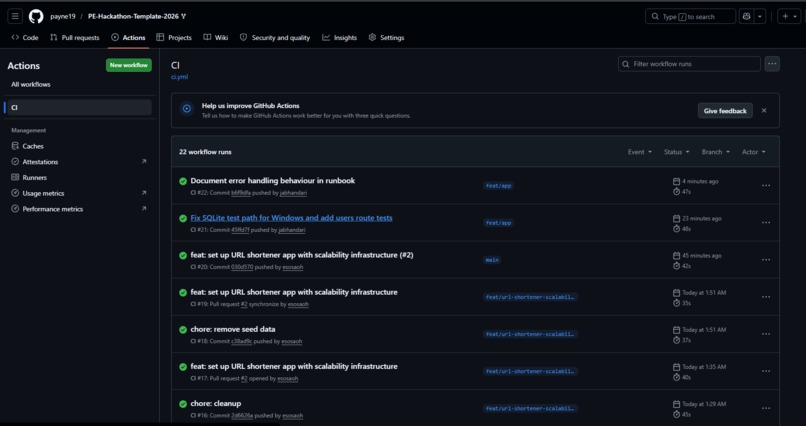
- CI prevents broken code from shipping
How we built it
We built the project as a multi-service production stack, where each component solves a real operational problem.
Core stack
- Backend API: Flask + Gunicorn (
gthreadworkers) - Reverse Proxy / Load Balancer: Nginx using
least_conn - Scaling: 3 backend replicas
- Database: PostgreSQL
- Connection Pooling: PgBouncer
- Caching: Redis
- Monitoring: Prometheus
- Visualization: Grafana
- Alerting: Alertmanager → Discord
- Logging: Structured JSON logs
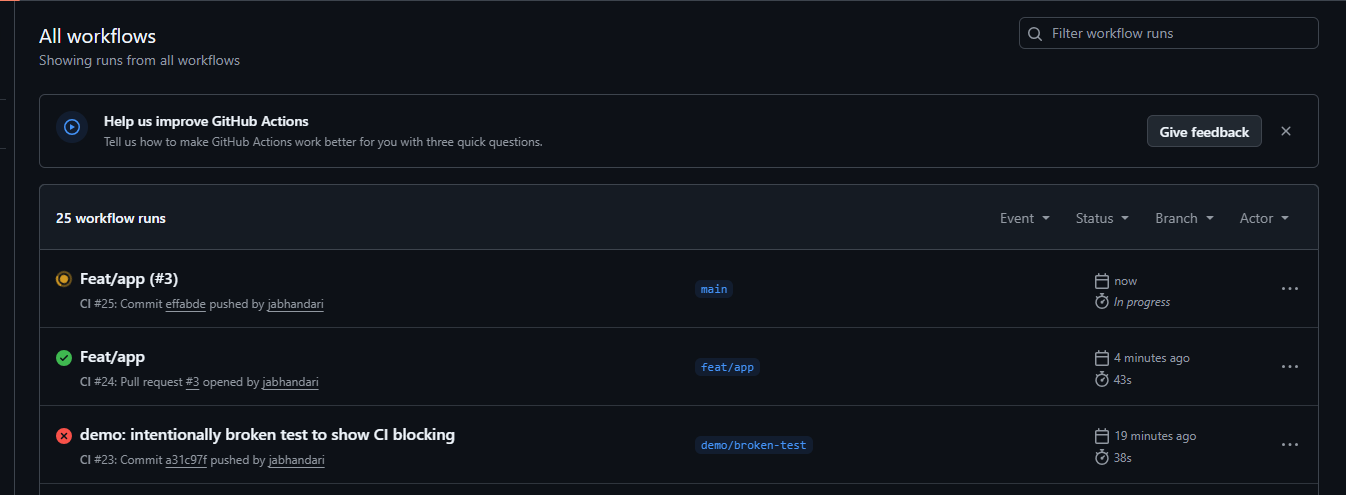
- Testing / CI:
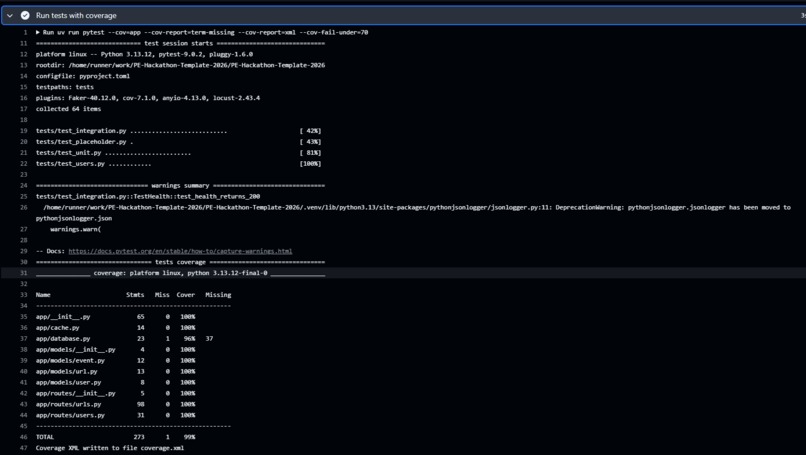
- 106 automated tests
- 99% coverage
- CI blocks failing deploys
Architecture flow
Client
↓
Nginx Load Balancer
↓
Flask App Replicas (x3)
↓
Redis Cache / PgBouncer
↓
PostgreSQL
Monitoring:
Prometheus → Grafana
Alerts:
Alertmanager → Discord ```
### Engineering approach
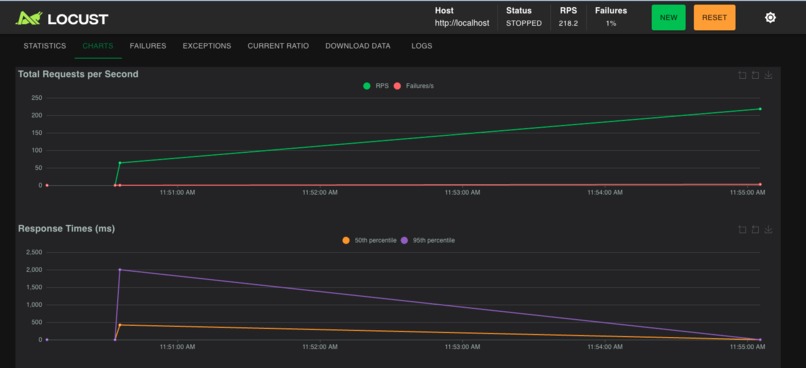
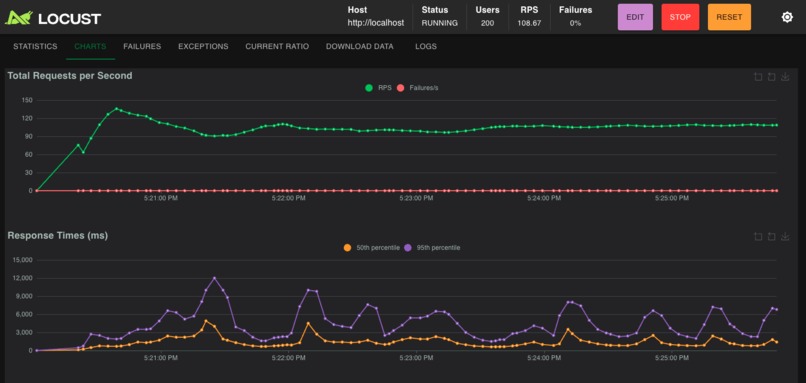
We wanted to build something that behaved like a real service under real pressure with load testing.
So instead of treating performance, observability, and reliability as “extra features,” we treated them as part of the product from the beginning.
Our workflow was:
1. Build a working baseline
2. Stress the system with load
3. Find the bottlenecks
4. Improve the architecture
5. Measure the impact
That mindset changed how we built everything.
Rather than asking, **“Can this app run?”**, we kept asking:
- **Can it handle concurrency?**
- **Can it recover from failure?**
- **Can we see what’s going wrong in real time?**
- **Can someone else operate this at 3am without guessing?**
That is what pushed the project from being a normal Flask app into something much closer to a real Production Engineering system.
## Accomplishments
We’re proud that this project feels like **something you could actually run**, not just working as a demo.
Key highlights:
- Built a **full production-style architecture** end-to-end
- Implemented **scaling, caching, pooling, monitoring, alerting, and resilience**
- Achieved **106 automated tests with 99% coverage**, blocking broken deploys via CI
- Turned a simple URL shortener into a **realistic Production Engineering showcase**
- Every component exists for a purpose not just to make the diagram look impressive
This project demonstrates that reliability and observability can coexist with a simple, understandable app.
## What’s Next
We plan to push the system closer to real-world production standards:
- Add **rate limiting** and abuse protection
- Introduce **user accounts and per-link analytics**
- Implement **rolling or canary deployment strategies**
- Simulate deeper chaos scenarios, like:
- database failures
- slow upstream services
- network partitions
- Deploy to a **real cloud environment**
- Add **tracing** for deeper observability





Log in or sign up for Devpost to join the conversation.