Project Story —UrbanSentinel: AI Public Safety Intelligence
Inspiration
Cities generate massive volumes of public signals every day — news reports, citizen complaints, social media posts, government alerts. But most of this information stays fragmented and unprocessed. Critical warnings get buried in noise, and institutions struggle to respond in time.
This problem directly connects to UN SDG 11 (Sustainable Cities and Communities) and SDG 16 (Peace, Justice and Strong Institutions). I wanted to build a system that could transform raw, unstructured public signals into prioritized, actionable intelligence — helping city decision-makers focus on what matters most.
How I Built It
I builtUrbanSentinel as a full-stack Python application with four core layers:
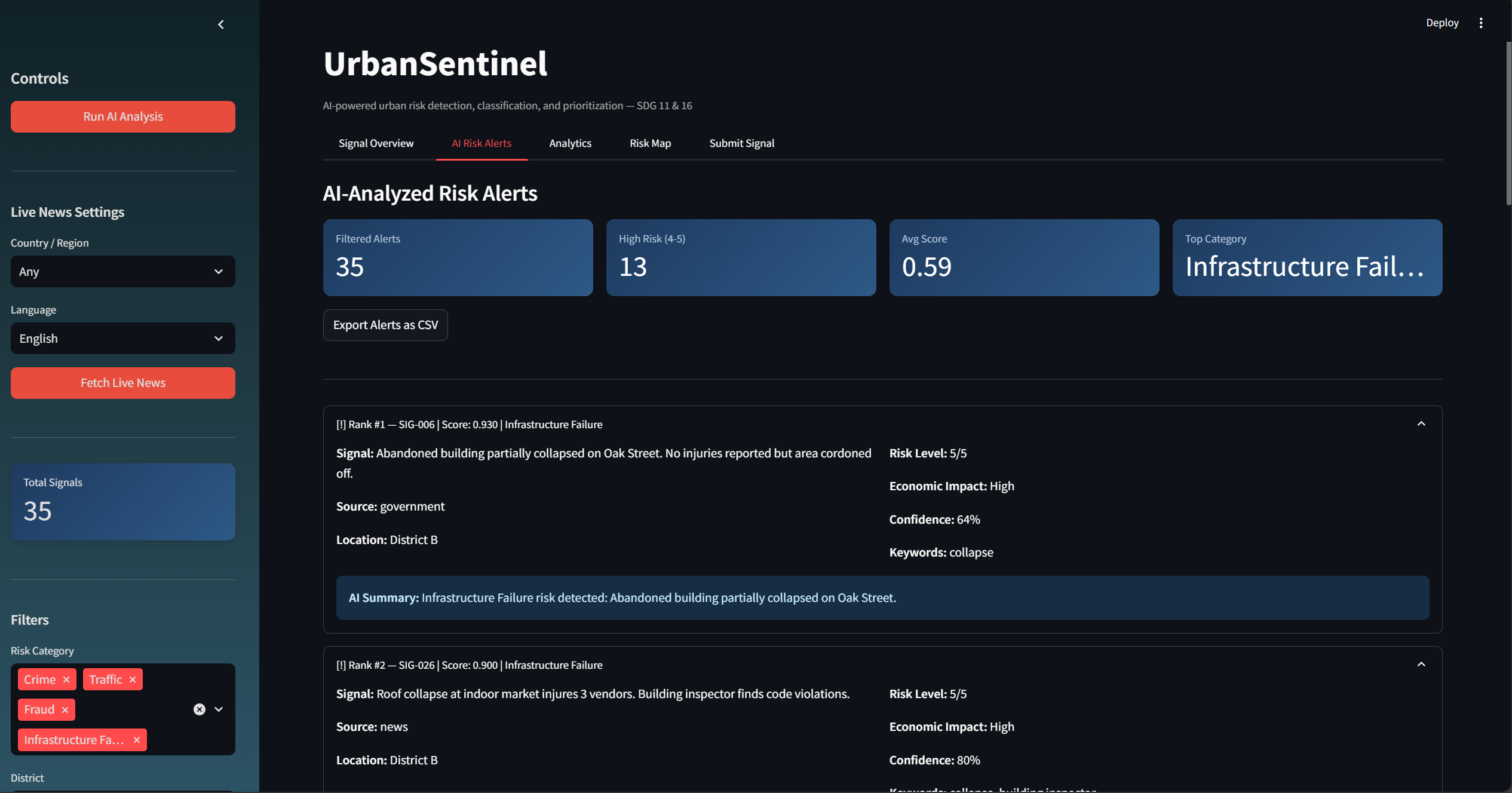
A hybrid NLP engine that fuses TF-IDF + Naive Bayes machine learning (40% weight) with keyword-based rule matching (60% weight). This gives both statistical learning power and domain-specific precision.
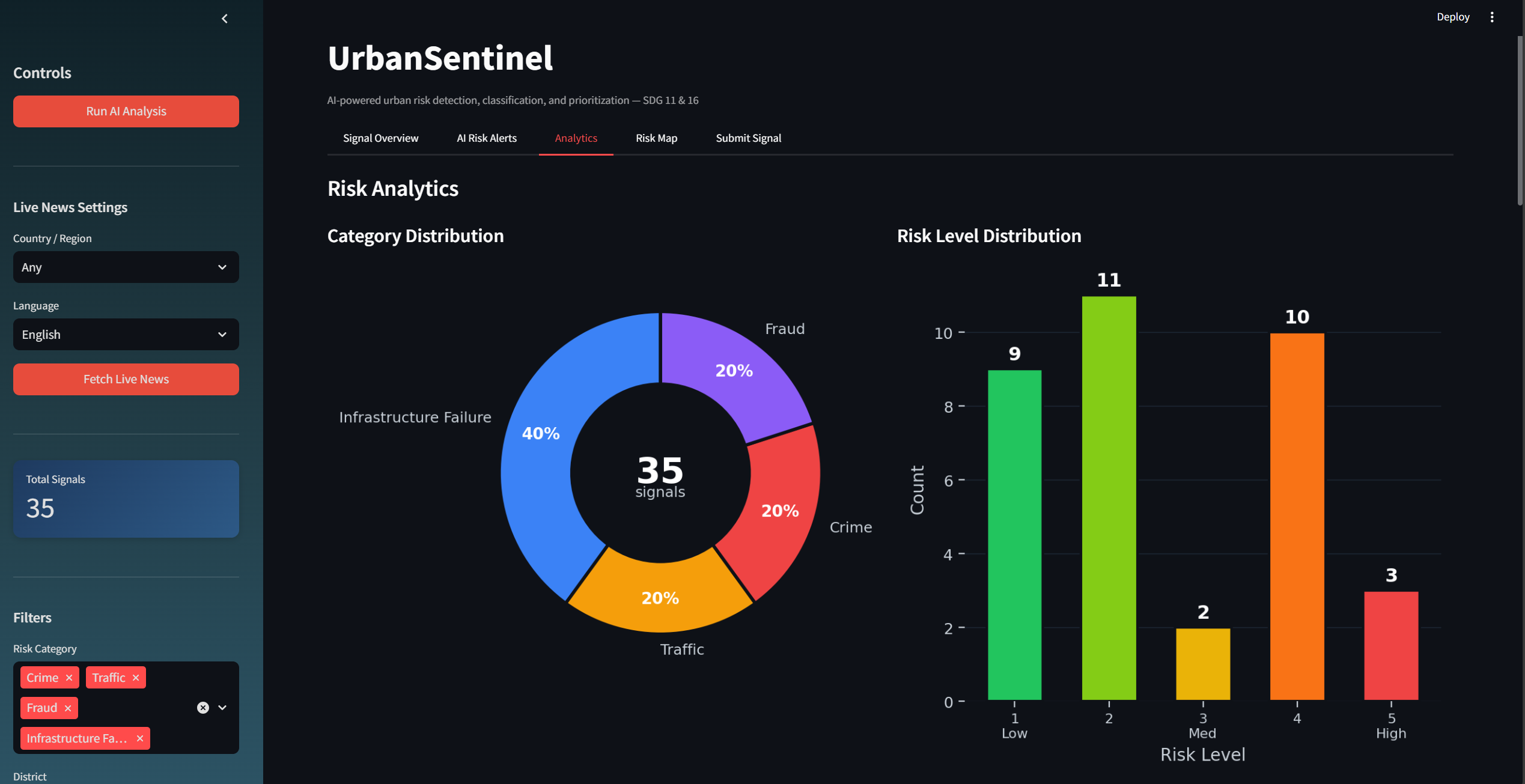
A weighted priority scoring algorithm: Score = 0.4 × Risk + 0.3 × Economic Impact + 0.2 × Source Credibility + 0.1 × Recency. This converts qualitative risk narratives into quantifiable, comparable indicators.
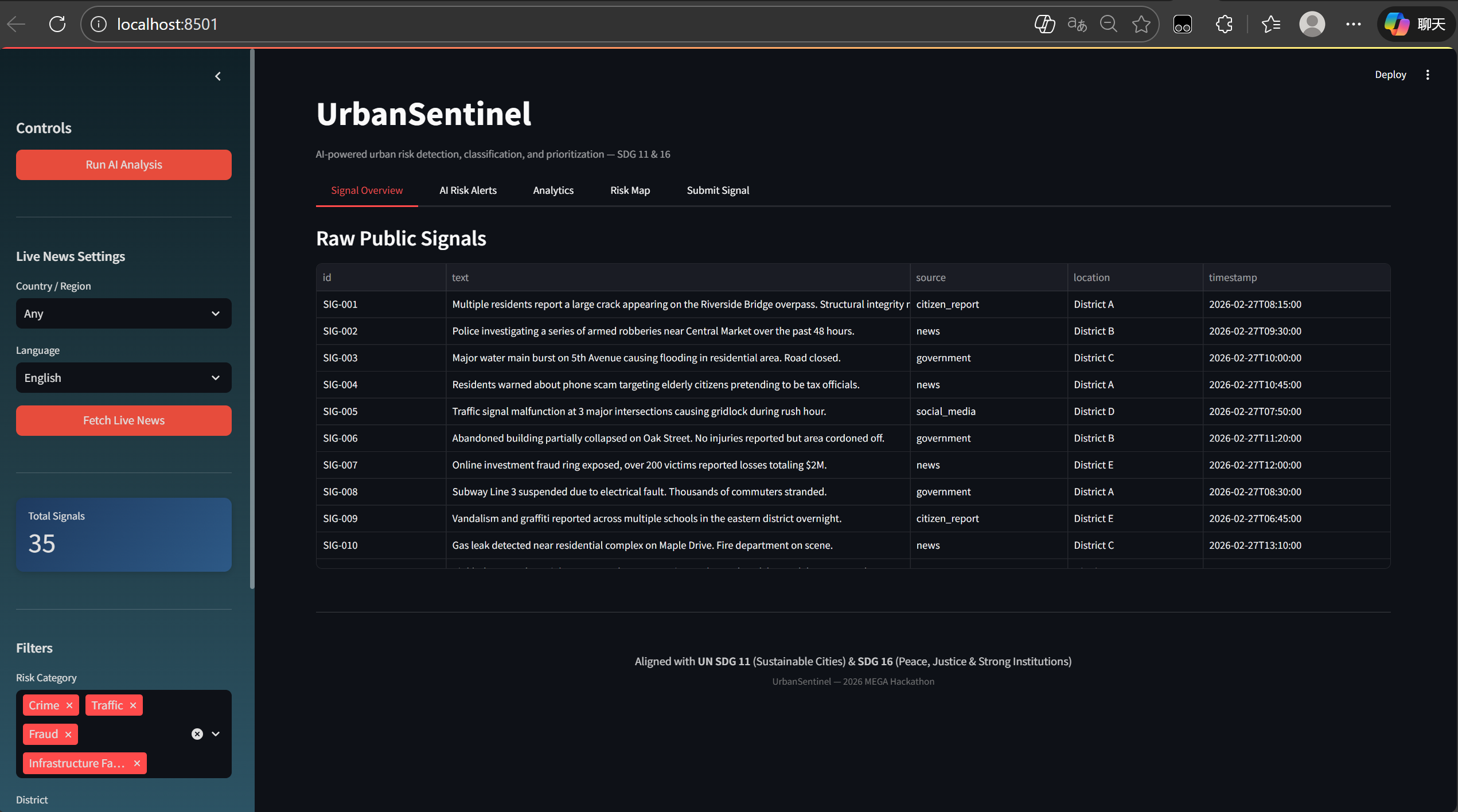
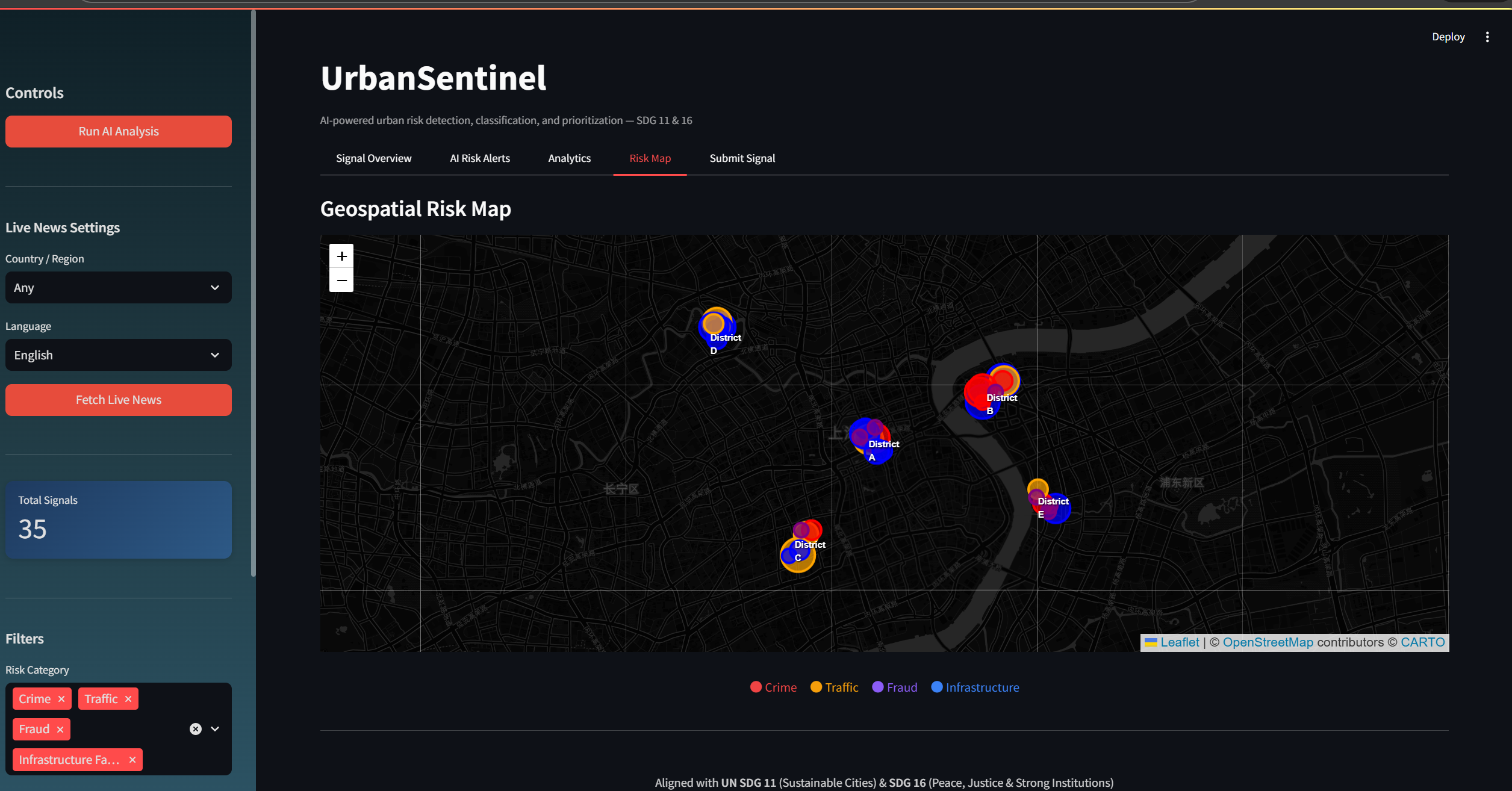
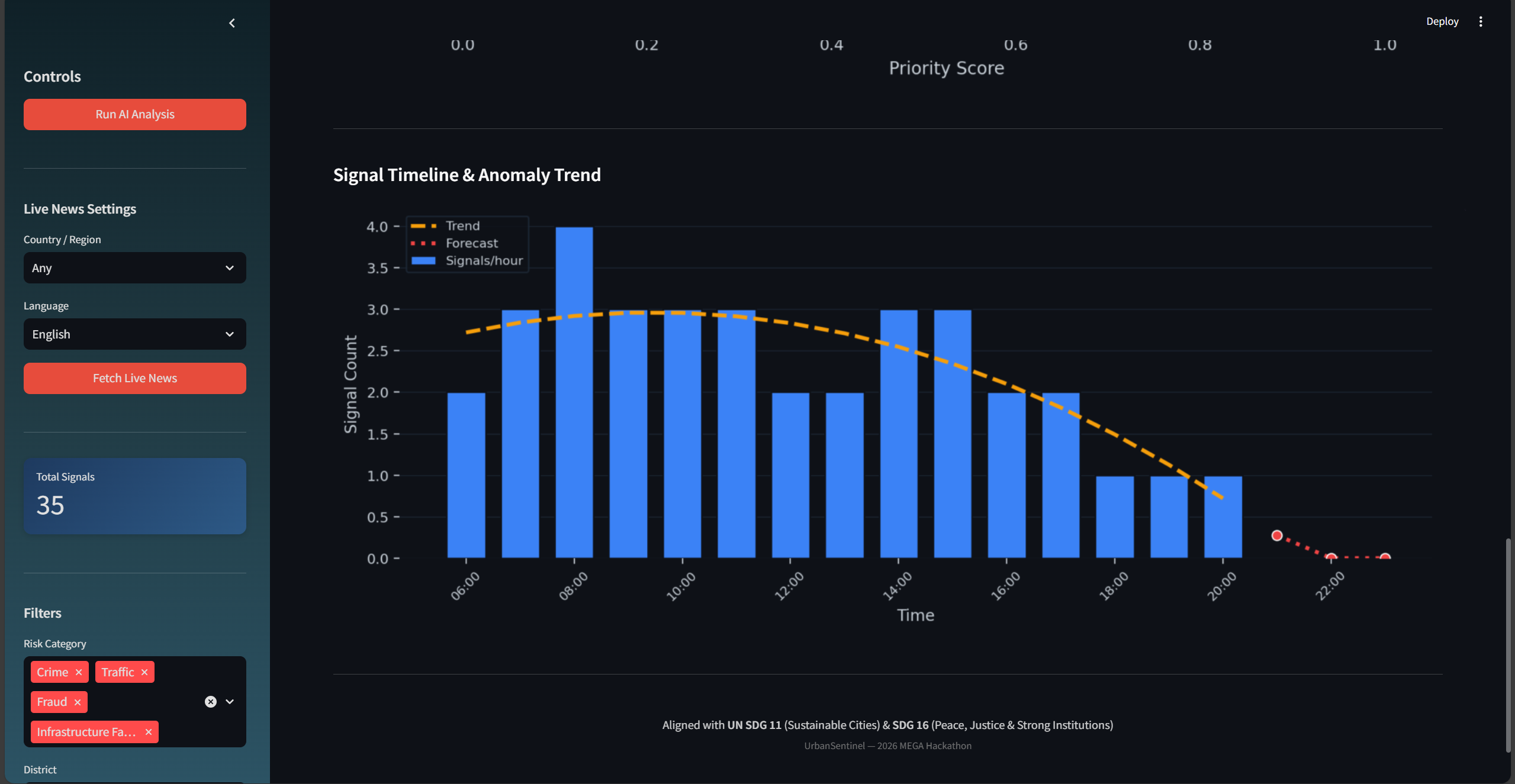
A Streamlit dashboard with five modules — Signal Overview, AI Risk Alerts, Analytics with anomaly trend prediction, an interactive Folium geospatial risk map, and a Signal Submission form.
Real-time news integration via GNews API with multi-language and country/region filtering, allowing live monitoring of urban risk events worldwide.
The system supports both English and Chinese input through automatic language detection (regex-based CJK character ratio analysis), with dedicated Chinese keyword classification rules.
I wrote75 unit tests across 6 test modules covering the analyzer, language detection, ML classifier, news fetcher, scorer, and data models — all passing.
What I Learned
Hybrid AI design: combining ML models with rule-based systems produces more robust and explainable results than either approach alone, especially with limited training data. Weighted scoring models: translating multi-dimensional risk factors into a single priority score requires careful weight calibration and normalization. Geospatial visualization: Folium with Streamlit integration enables powerful interactive mapping without heavy frontend frameworks. Session state management: Streamlit's session_state is essential for maintaining dynamic data (like fetched news) across UI rerenders. Test-driven development: writing comprehensive tests early caught edge cases in language detection and scoring boundary conditions that would have been hard to debug later. Challenges
The biggest challenge was the lack of labeled urban risk datasets. There's no ready-made corpus of city safety signals with category and severity labels. I solved this by generating a synthetic training corpus based on domain knowledge and fusing the ML model with keyword rules — the keyword layer provides a reliable baseline while the ML layer captures patterns the rules might miss.
Multi-language support was another hurdle. The TF-IDF + Naive Bayes pipeline was trained on English text, so it couldn't directly classify Chinese signals. I addressed this by building a language detection module that routes Chinese input to a dedicated keyword classification engine with Chinese risk vocabulary, while English input goes through the full hybrid pipeline.
Finally, working within a tight hackathon timeline as a solo developer meant making pragmatic architecture decisions — choosing lightweight tools (Streamlit over React, Folium over Mapbox, scikit-learn over deep learning) that could deliver a complete, functional system without sacrificing analytical depth.

Log in or sign up for Devpost to join the conversation.