

Inspiration
Self-learning fails for predictable reasons:
- The web has infinite content, but learners don't get a dependency-aware sequence; they discover prerequisites only after getting stuck.
- Most learning platforms are static and linear; personalization is shallow.
- "AI tutors" often behave like a chat session: they explain, but don't persist a curriculum structure, track mastery over time, or reliably attach trustworthy resources.
We wanted a system that behaves like an instructor + curriculum designer combined: it plans, persists, evaluates, and adapts.
What it does
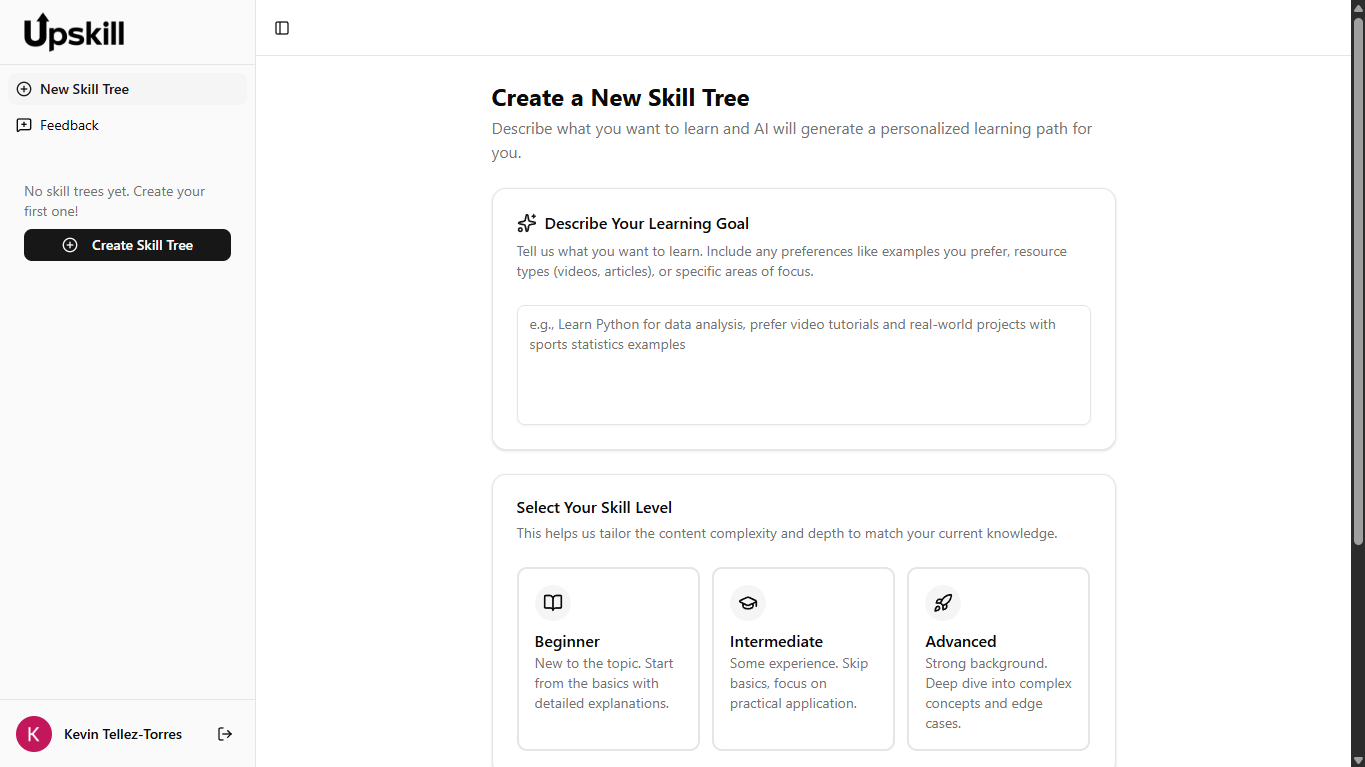
Upskill generates personalized skill trees from a single prompt. Describe what you want to learn, select your skill level (beginner/intermediate/advanced), and the system produces:
- A branching curriculum structure — not a linear course, but a graph of prerequisites where nodes unlock based on demonstrated mastery
- Rich instructional content per node with learning objectives, explanations, and embedded math/code rendering
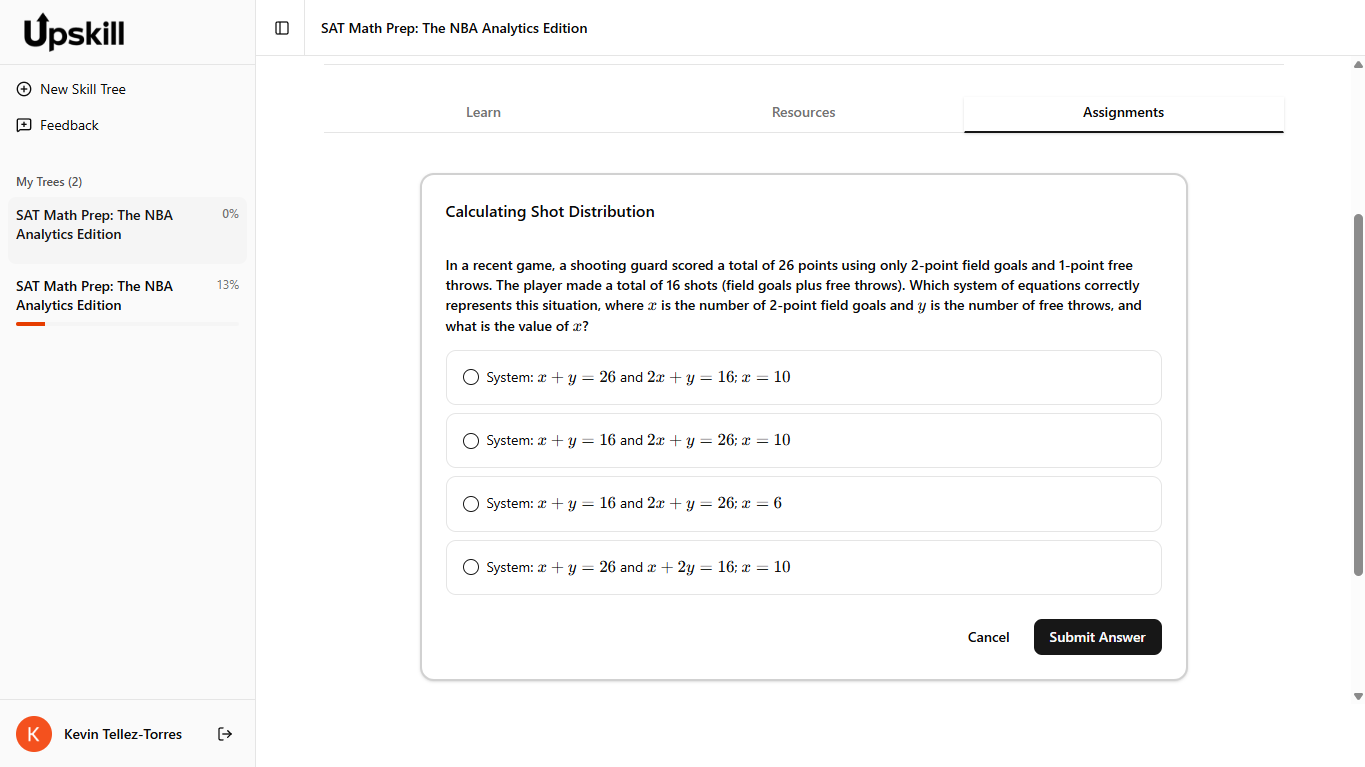
- Auto-graded assignments (multiple choice, open-ended, code tests) with unlimited resubmissions and AI feedback
- Curated external resources sourced via Perplexity API for each topic
- Adaptive remedial nodes — if you're struggling, request a focused micro-lesson that branches off the main tree
- Collaborative features — share trees via invite links; joiners get independent progress tracking
Progress persists across sessions. The tree visualization shows completion state at a glance with color-coded progress bars (red → green).
How we built it
Stack: Next.js 14 (App Router), TypeScript, Prisma, NeonDB (Postgres), Tailwind CSS, shadcn/ui
AI Pipeline (two-pass generation):
- Structure pass — Gemini generates the tree skeleton: titles, learning objectives, assignment types, prerequisite relationships
- Content expansion — Nodes are expanded in depth-first batches with full instructional content and assignments
- Validation — Custom curriculum validator checks for duplicate titles, depth limits, assignment-content alignment, and topic-appropriate assignment types
- Resource enrichment — Perplexity API attaches external learning materials per node
Grading:
- Multiple choice: deterministic evaluation with normalized option IDs
- Open-ended: Gemini-powered rubric evaluation with structured feedback
- Code tests: isolated-vm sandboxed execution with test case validation
Rendering: KaTeX for math notation, marked for markdown, DOMPurify for sanitization. The tree visualization uses ReactFlow with dagre for automatic layout.
Challenges we ran into
- LaTeX in JSON — Gemini outputs
\frac,\text, etc., which are invalid JSON escapes. We built a sanitizer that preserves legitimate escapes while double-escaping LaTeX commands. - Content-objective alignment — Early generations produced generic content that didn't teach toward stated learning objectives. We added explicit alignment instructions and post-generation validation scoring.
- Assignment type mismatches — The model would assign CODE_TEST to non-programming topics. We added topic inference and validation penalties.
- Grading persistence — Async job completion and database write ordering caused race conditions. Required careful transaction handling.
- Tree depth vs. breadth tradeoffs — Too deep and users get lost; too shallow and the curriculum lacks substance. We settled on max depth 4, 3-10 root nodes, 55 total node limit.
- Coding Learning Goals Assignments — Focused more on optimizing STEM related assignment.
Accomplishments that we're proud of
- Mastery-based progression — nodes unlock only when prerequisites are completed, preventing the "skip ahead and get lost" problem
- Remedial branching — the system generates targeted help without disrupting the main curriculum structure
- Zero hardcoded content — every tree is generated fresh from the user's prompt
- Production-grade validation — the curriculum validator catches structural issues before they reach the database
What we learned
- LLM outputs need defense-in-depth: prompt engineering alone isn't enough. Schema validation, content validation, and graceful fallbacks are all necessary.
- Two-pass generation (structure → content) produces better results than single-pass because it separates curriculum design decisions from content writing.
- Rate limiting and timeout handling matter more than expected when multiple API calls happen per generation.
What's next for Upskill
- More AI Tools — AI generated flash cards, AI generated quizzes with content from select nodes, etc.
- Implement Context Aware Curriculum AI Tutor — Can guide users through curriculum and can assist on assignments.
- Spaced repetition — resurface completed nodes for review based on forgetting curves
- Learning analytics — track time-to-mastery, common failure points, and suggest curriculum improvements
- Tree editing — let creators modify generated trees before sharing
- Mobile optimization — the current tree visualization is desktop-first; touch interactions need work
- Content moderation — AI-generated content needs quality gates before public sharing
- Additional assignment types — diagram labeling, drag-and-drop sequencing, interactive simulations, more!
- Commercialization — Set up pricing model and paywall
Built With
- dagre
- dompurify
- gemini-3
- katex
- marked
- nextjs
- perplexity
- postgresql
- prisma
- react
- react-flow
- shadcn/ui
- tailwind
- typescript
- zod

Log in or sign up for Devpost to join the conversation.