Language is the most powerful tool because it's what we use to communicate with each other. As specification and precision with language increases, people become close to understanding each other.
We built Lingle because we were interested in machine learning APIs, and because all of the team members have had to learn English as a second language, so it was interesting to learn about English linguistics and linguistic computing, such as syntax, salience, etc.
As students we have to read a lot of research papers. Being a citizen in the digital age means there is a plethora of online news. We hoped to make a web application that could identify focal entities in text (e.g. Person, Organization, etc.) and the negative, positive, mixed, and neutral connotations surrounding that entity in each sentence to isolate key sentences.
Introduction to this project
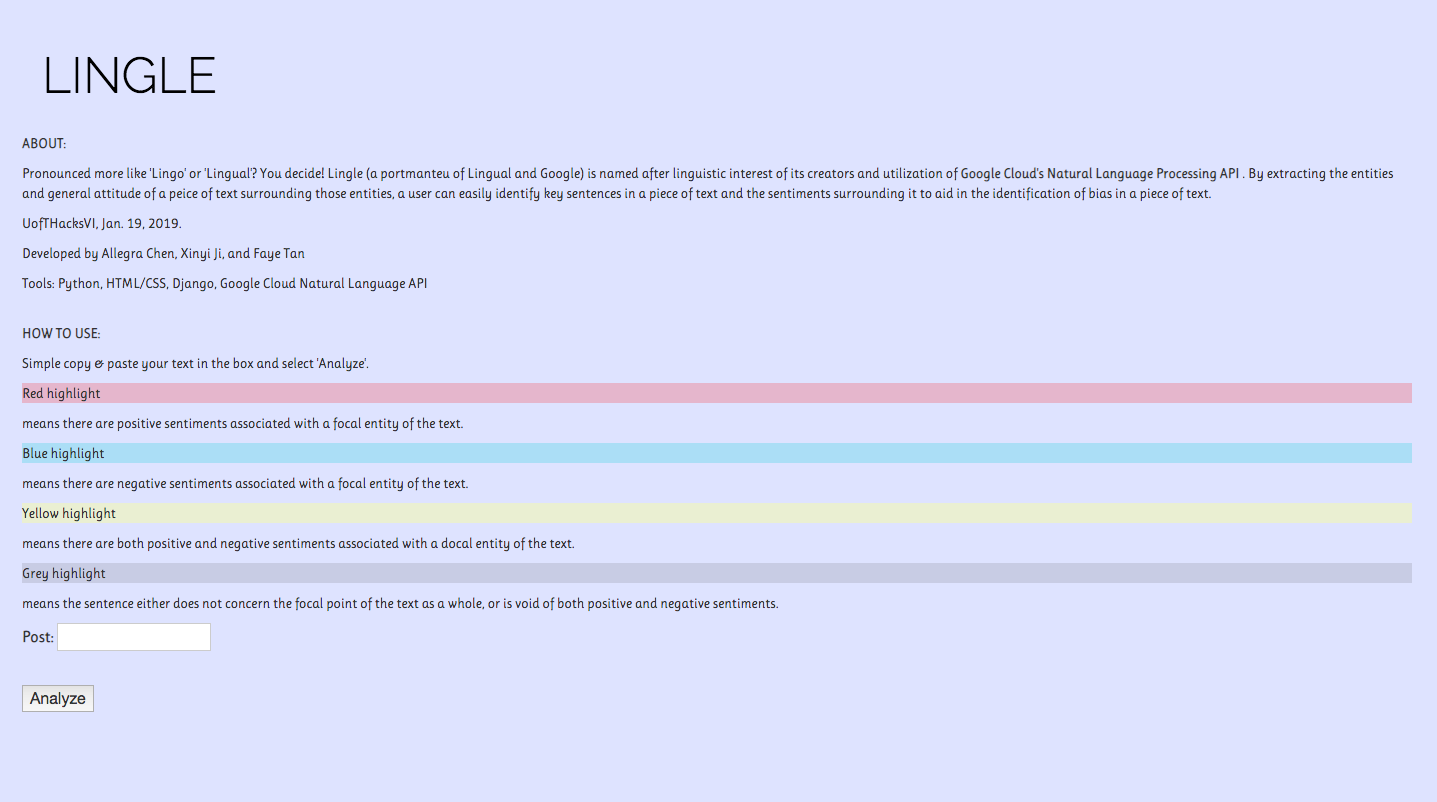
The purpose of Lingle is to try to read text, whether it be news or a research paper, and extract the significant sentences in the article based on the key entities (focal points) of the text, and analyze the sentiment around them (positive, negative, neutral, etc.)
Basic Functions
After pasting the whole article on the dialog box and click on the "analyze" button, Lingle will show you the significant sentences placed in different categories ( positive attitude, negative attitude and neutral attitude). - Then you can now read the text much easier by just looking at the sentences extracted and knowing what kind of attitude these sentences represented.
Great Features
With the sentences being in different categories, users can get the general attitude of the whole article by just skim those sentences.
Provides a quick, visual sweep of long text inputs to identify key sentences concerning focal entities mentioned by the text.
How we built it
Built on the Django framework with Python and HTML/CSS, we utilized the Natural Language Machine Learning APIs from Google to analyze the context of the text entered in the form ( Thanks Google)
Challenges we ran into
We spent some time trying to show the context on the website with python connecting with html, css, Django framework which will show the sentences.
This was our first time using Django and Machine Learning APIs. We were (pleasantly) surprised at how much data Google's Natural Language Processor, but it took a lot of effort to comb throw the seemingly endless dictionaries and lists.
What we learned
We learned how to utilize Machine Learning API, to access and analyze the data and perform operations on it to benefit a user
We also learned about Python to HTML/CSS we development in Django, a completely new environment.
We even learned a little Javascript on the go in while trying to implement a feature on our webpage.
What's next
We didn't have enough time, but we have a constant in our code called NUM_ENTITIES, that sets the number of entities which the program looks for in the text with the highest salience (prevalence to text). We were hoping to let the user enter a number (e.g. 5) to denote the top n entities sentiment analysis would perform on.
We would also like to provide some interactive ways to visualize the information by offering identification of key entities, so the user can select exactly which ones are used in the algorithm
Notes
To run, you need to install django and google-cloud




Log in or sign up for Devpost to join the conversation.