-
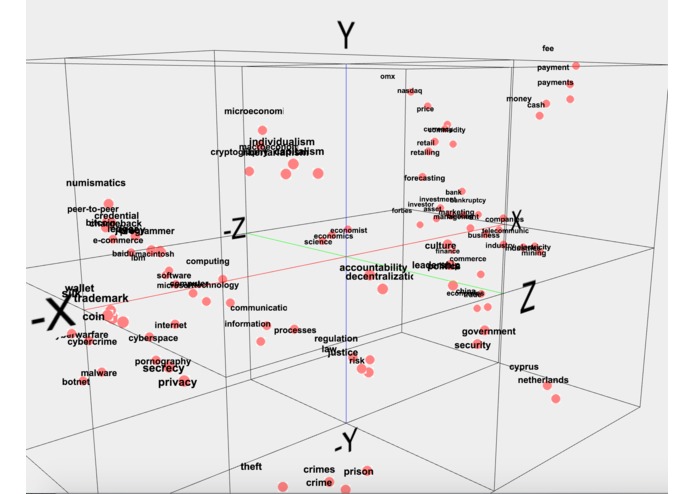
Visualization of text.

Inspiration
The web is filled with unstructured text, and in order for computers to understand that text, it needs to be in structured format. It's one more step in computer reading.
What it does
Extracts structured information from unstructured text, and visualizes different concepts and subjects of the text.
How we built it
We took datasets of parent -> child relationships from Wikidata and used it to 'train' our text analysis software (and verify whether our text analysis gave the correct answer or not), allowing it to determine what kind of relationship two words have to each other. As another approach to the same problem, we used GloVe to vectorize words in a given document, and used three.js to 3-dimensionally visualize the data in a semi-clustered form.
Challenges we ran into
Large data sets, inadequate time for training, designing experimental algorithms, too many carbs.
Accomplishments that we're proud of
The fact that we got both the visualization and the text analysis working well in 36 hours. We are happy we could approach a complex subject and have a product that shows definite progress. We're also happy that these accomplishments were accomplished with a group of strangers.
What we learned
Some new APIs, natural language processing, vectorization of words and visualization, how the different approaches compare to each other, and to bring some other food groups to the next TreeHacks.
What's next for Unstructured Text Analysis
Being able to scan a document and get completely structured text from it. Ideally, facts like "Berlin is the capital of Germany" from a sentence that doesn't explicitly state so. Another example of structured data would be a family tree, if given in a page, formed from analyzing who is the parent of who. Other awesome things.





Log in or sign up for Devpost to join the conversation.