-
-
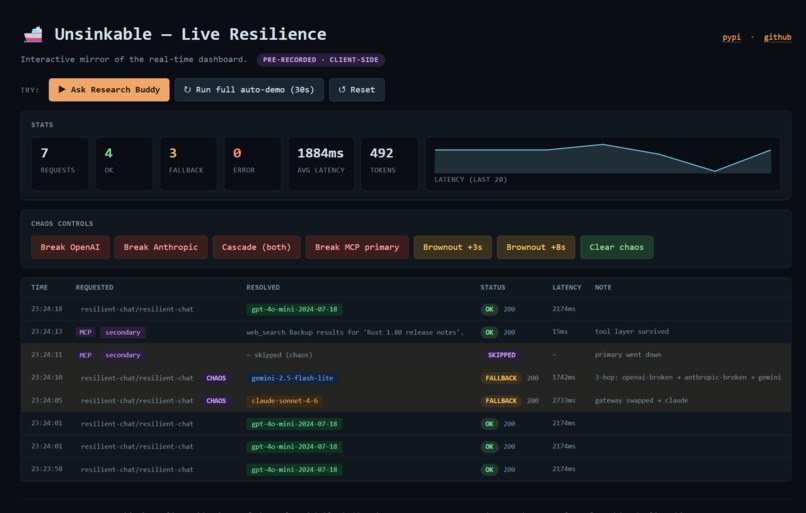
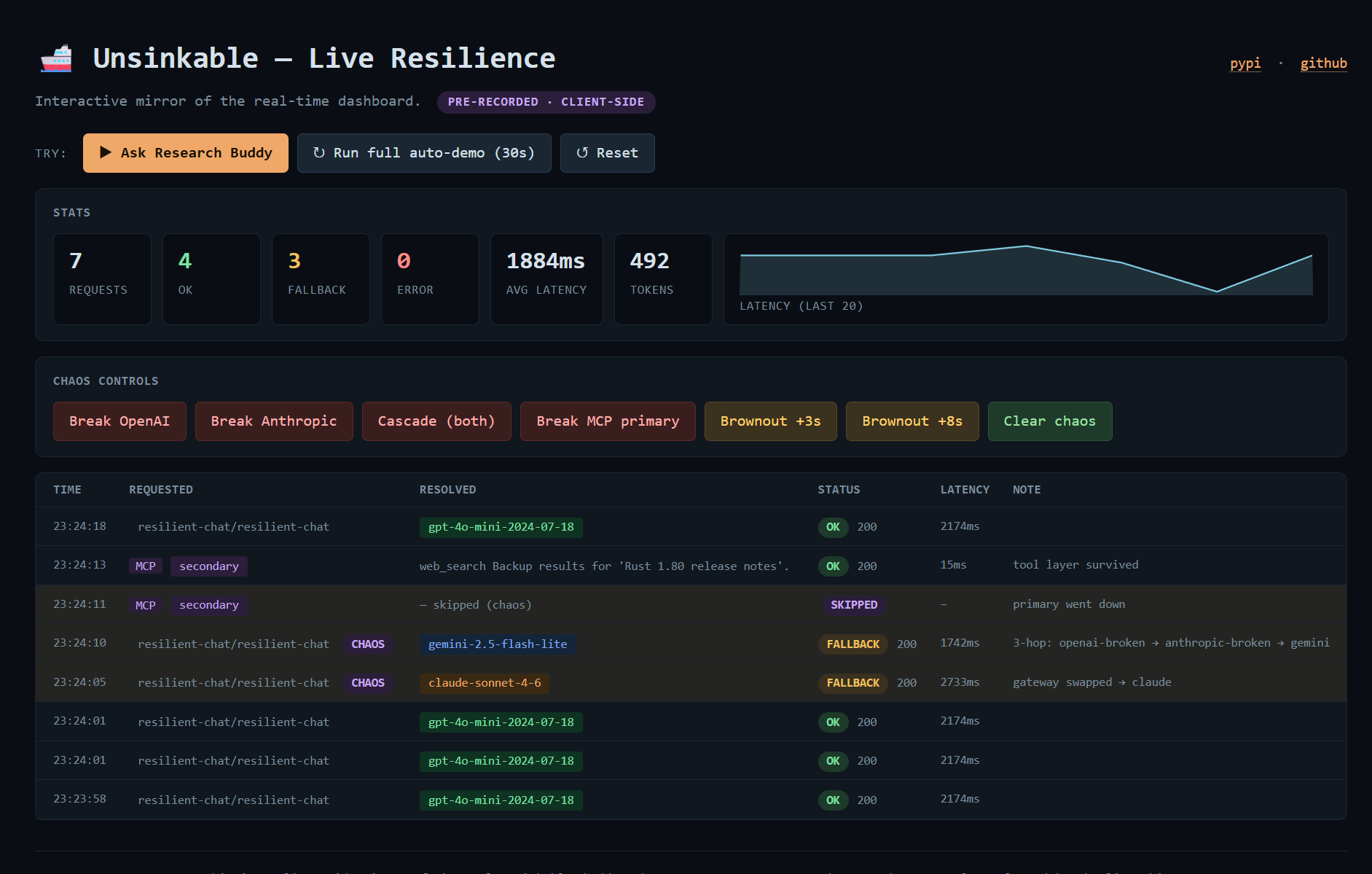
Live Dashboard
Inspiration
Production LLM applications are routinely one provider outage away from a status-page incident. We have all read the same retro: OpenAI brown-outs, the agent surfaces a 5xx, customer support lights up. Anthropic rate-limits the next morning, same story. The infrastructure to avoid this already exists — TrueFoundry's AI Gateway ships priority-based routing, retries, virtual models, observability, even a Virtual MCP Server for tool resilience.
What was missing was the on-ramp. To benefit from the gateway you had to change base_url, swap auth, refactor request shapes, configure routing YAML, and then build something to prove your new fallback chain actually fires under load. None of that is hard, but none of it is free either, and the sum is enough activation energy to keep most teams on raw openai.OpenAI(api_key=...) until the day production teaches them otherwise.
We wanted to collapse that activation energy to two lines of code, and pair it with a chaos engine and live observability so resilience could be demonstrated — not just promised — before shipping.
What it does
unsinkable is a Python package, published on PyPI, that wires any OpenAI- or Anthropic-SDK-compatible app to TrueFoundry's AI Gateway in two lines:
from unsinkable import OpenAI
client = OpenAI()
The shim subclasses openai.OpenAI (and openai.AsyncOpenAI), injects the gateway base URL and authentication from environment variables, and installs an instrumented httpx transport. Every chat.completions.create, embedding, streamed response, or tool-call request now flows through TrueFoundry's gateway with priority-based fallback (OpenAI → Anthropic → Gemini, or whatever chain you configure).
The package ships eight surfaces:
| Surface | What it provides |
|---|---|
unsinkable.OpenAI / AsyncOpenAI |
Drop-in subclass that preserves the full openai-python API while routing through the gateway. |
unsinkable.Anthropic / AsyncAnthropic |
Drop-in for anthropic.Anthropic. Translates the Messages API to OpenAI Chat Completions in flight so the gateway sees a uniform shape. |
unsinkable.mcp.ResilientMcpClient |
Client-side analogue of TF's Virtual MCP Server. Wraps multiple MCP backends — local stdio subprocesses or remote Streamable-HTTP endpoints — and fails over per tool call. |
unsinkable dashboard |
Local FastAPI + SSE server with in-page chaos controls, latency sparkline, p50/p95/p99 percentiles, token counter, and provider-color-coded badges. |
unsinkable chaos {break,brownout,clear,status} |
Six scenarios — openai, anthropic, cascade, rate-limit, truncate, mcp-{primary,secondary,all} — that produce real gateway-side fallback by swapping the outgoing model name to a pre-broken Virtual Model. |
unsinkable wire <target> [--dry-run] |
AST codemod (libcst) that rewrites from openai import ... and from anthropic import ... to from unsinkable import ... across an entire project. Whitespace and comments preserved. |
unsinkable demo |
Scripted 14-step resilience tour (~45 s) covering LLM fallback, brownouts, three-hop cascade outages, and MCP failover. |
| OpenTelemetry exporter | Set OTEL_EXPORTER_OTLP_ENDPOINT and every request event is emitted as a span alongside the dashboard. Optional install: pip install unsinkable[otel]. |
A production guardrail (UNSINKABLE_DISABLE_CHAOS=1) hard-disables the chaos engine even if a stale state file is present, so a developer-laptop scenario can never affect a deployed app. A live Vercel demo lets visitors play with the dashboard without installing anything.
How we built it
The shim lives in src/unsinkable/client.py. We subclass openai.OpenAI and openai.AsyncOpenAI and intercept transport rather than the SDK's resource methods, which preserves the full upstream surface area (chat, embeddings, images, streaming, tool use, structured outputs) without re-implementing anything:
class _InstrumentedSyncTransport(httpx.HTTPTransport):
def handle_request(self, request: httpx.Request) -> httpx.Response:
start = time.perf_counter()
requested = _extract_requested_model(request)
request, chaos = _apply_chaos(request) # body rewrite if active
brownout = current_brownout()
if brownout > 0 and request.method == "POST":
time.sleep(brownout)
response = super().handle_request(request)
response.read()
self._sink.emit(RequestEvent(
requested_model=requested,
resolved_model=_extract_resolved_model(response), # x-tfy-resolved-model
status_code=response.status_code,
latency_ms=(time.perf_counter() - start) * 1000,
chaos=chaos,
prompt_tokens=..., completion_tokens=...,
))
return response
The chaos engine (src/unsinkable/chaos.py) persists state as a single JSON file at /tmp/unsinkable-chaos.json so the CLI and any agent processes consulting the shim see a consistent view without an IPC layer. Each named scenario maps an "original" Virtual Model name to a "chaos" variant — or, for body-override scenarios like truncate, mutates the request payload directly:
SCENARIOS = {
"openai": {"resilient-chat/resilient-chat": "chaos-openai-down/chaos-openai-down"},
"anthropic": {"resilient-chat/resilient-chat": "chaos-anthropic-down/chaos-anthropic-down"},
"cascade": {"resilient-chat/resilient-chat": "chaos-cascade/chaos-cascade"},
"rate-limit": {"resilient-chat/resilient-chat": "chaos-rate-limit/chaos-rate-limit"},
}
BODY_OVERRIDE_SCENARIOS = {
"truncate": {"max_tokens": 1},
}
The chaos variants are pre-applied TrueFoundry Virtual Models whose priority-0 target uses a deliberately invalid integration (openai-broken with sk-broken-on-purpose as the API key). When chaos is active, the shim rewrites the model field in the outgoing JSON body so the gateway hits the broken target, gets a real error, and falls back through the rest of its priority chain. This makes the demonstration honest: there is no mocking — the gateway's own retry and fallback logic does the work.
Virtual Model manifests were applied via tfy apply -f gateway-config/*.yaml. The working schema (provider-account/virtual-model with integrations[].routing_config) was assembled by inspecting an existing provider account through the management API and adapting:
name: resilient-chat
type: provider-account/virtual-model
collaborators:
- role_id: provider-account-manager
subject: user:<email>
integrations:
- name: resilient-chat
type: integration/model/virtual
model_types: [chat]
routing_config:
type: priority-based-routing
load_balance_targets:
- target: openai/gpt-4o-mini
priority: 0
fallback_status_codes: ["401","403","404","408","429","500","502","503","504"]
retry_config: { attempts: 2, delay: 100 }
- target: anthropic/claude-sonnet-4-6
priority: 1
- target: google-gemini/gemini-2.5-flash-lite
priority: 2
The Anthropic adapter (src/unsinkable/anthropic_adapter.py) is a translation layer. TF's gateway exposes an OpenAI-compatible endpoint, so the adapter accepts the Anthropic SDK's messages.create(model, max_tokens, system, messages, ...) shape, normalizes content blocks to plain strings, lifts the system prompt to a {role: "system"} message, calls the OpenAI shim under the hood, and translates the response back to an Anthropic-shaped Message object with a proper stop_reason mapping (stop → end_turn, length → max_tokens, tool_calls → tool_use).
The codemod (src/unsinkable/wire.py) uses libcst so whitespace, comments, and aliases survive the rewrite. It refuses to silently drop unknown symbols (from openai import OpenAI, ChatCompletion leaves the whole line intact and emits a warning), refuses to touch import *, and warns on bare import openai patterns rather than guessing. A --dry-run flag prints unified diffs without writing.
The dashboard (src/unsinkable/dashboard.py) is a small FastAPI app with an in-memory ring buffer (capacity 500) and SSE streaming. Chaos buttons in the UI POST to /api/chaos/{break|brownout|clear}, which write the state file and synthesize a chaos-update event so the banner updates instantly without waiting for the next LLM request. The stats row now includes p50/p95/p99 latency percentiles computed from a rolling window of the last 50 events.
The MCP client (src/unsinkable/mcp.py) uses AsyncExitStack to manage sessions to multiple backends, dispatching on backend.kind between local stdio_client and remote streamablehttp_client. Each call_tool tries backends in priority order, skipping those matched by an active mcp-* chaos scenario; exceptions from one backend trigger an automatic attempt on the next.
Observability fan-out. A CompositeSink lets the instrumented transport emit each RequestEvent to multiple sinks — the local dashboard, an OpenTelemetry OTLP/HTTP exporter, or both. The OTel sink decorates spans with semantic-convention-ish attributes (tfy.requested_model, tfy.resolved_model, tfy.chaos_scenario, llm.usage.prompt_tokens, http.status_code) so traces correlate cleanly with downstream APM tools.
Distribution. Hatchling for builds, twine for the PyPI upload, two versions shipped (0.1.0 and 0.2.0). The 45-test pytest suite covers configuration parsing, the chaos state lifecycle (including the production-guardrail kill switch), body-rewrite invariants, Anthropic request/response translation, the codemod against representative import shapes, OTel span attributes via the in-memory exporter, and live MCP failover against two locally spawned FastMCP servers.
Challenges we ran into
TrueFoundry's Virtual Model schema is sparsely documented for tfy apply. The public docs describe the routing_config block but not the wrapping manifest. Our first attempts failed validation with must have required property 'integrations' errors from the server's JSON-schema validator. We unblocked by inspecting an existing provider account through GET /api/svc/v1/provider-accounts and reverse-engineering the working YAML — provider-account/virtual-model with the routing config nested one level deeper, inside integrations[].routing_config, not at the top level the docs implied.
The gateway is OpenAI-compatible only. TrueFoundry exposes /api/llm/openai/v1 but no native /api/llm/anthropic/v1. For the unsinkable.Anthropic adapter to inherit the same gateway resilience, we had to translate the Anthropic Messages API to OpenAI Chat Completions in flight — including normalizing structured content blocks, lifting the top-level system prompt into the messages list, mapping stop_sequences to stop, and reversing the finish_reason mapping on the response. The upside is that every Anthropic call site now benefits from the same fallback chain as the OpenAI ones, without configuring a separate gateway path.
Accomplishments that we're proud of
pip install unsinkableis real. Two versions shipped to PyPI during the hackathon (0.1.0 and 0.2.0), each verified with a clean-venv install: imports work, CLI works, all five subcommands present.- The chaos demonstration is honest. Clicking "Cascade" really does cause two provider failures at the gateway before Gemini answers. The model name the shim sends gets rewritten; the gateway tries
openai-broken/gpt-4o, fails for real, triesanthropic-broken/claude-sonnet-4-6, fails for real, lands ongoogle-gemini/gemini-2.5-flash-lite. Thex-tfy-resolved-modelheader in the response proves which target ultimately answered. No mocking, no theater. - The drop-in shim preserves the full
openai-pythonsurface area because we intercept transport, not the resource methods. Embeddings, streaming, tool calls, structured outputs — all work without us re-implementing anything. The Anthropic adapter shares the same transport, so observability, chaos awareness, and the production guardrail apply uniformly. - Forty-five tests green, including live MCP failover that spawns two
FastMCPstdio servers and asserts the resilient client switches backends when the primary is marked broken. - The
unsinkable wirecodemod rewrites an existing project'sfrom openai import OpenAIcalls tofrom unsinkable import OpenAIin one command, with--dry-rundiffs, alias preservation, and refusal to silently drop unknown symbols. - Production guardrail.
UNSINKABLE_DISABLE_CHAOS=1flips the chaos engine into a true no-op at the transport layer, so a stale state file from a developer laptop cannot affect a deployed agent. This was the smallest patch in v0.2.0 but it changes the operational story entirely. - End-to-end observability. Request events stream to a local dashboard and (optionally) to any OTLP-compatible APM via the new OTel exporter, so the same telemetry that drives the demo can land in Honeycomb, Datadog, or Grafana Tempo without re-instrumentation.
What we learned
TrueFoundry's gateway is genuinely powerful, but the developer story is the bottleneck. The two-line wiring, the codemod, and the drop-in Anthropic adapter together close the loop between "we have an LLM app" and "we have a resilient LLM app." The infrastructure was already there; what mattered was making the on-ramp invisible.
Mirror the resilience pattern at the client too. Even with a smart gateway, some failure modes are client-side problems: network partition between the app and the gateway, MCP tool servers that aren't behind the gateway, request payloads that need to be mutated rather than rerouted. The chaos engine's body-override scenarios (truncate) and the client-side MCP failover are the same discipline as gateway-side priority routing, just applied earlier in the request lifecycle.
Real chaos beats simulated chaos. Demoing actual gateway-level fallback is dramatically more compelling than mocked errors, and it isn't much more work once the model-name-swap trick is in place. The x-tfy-resolved-model header is the proof point — once you can show which target answered, the resilience story tells itself.
Translation adapters earn their keep. The Anthropic adapter is a hundred and fifty lines of request/response translation, but it lets every existing anthropic.Anthropic call site swap to from unsinkable import Anthropic with no other change and inherit the entire gateway fallback chain. Compatibility shims are unglamorous but they multiply reach.
Optional dependencies keep the install lean. Splitting opentelemetry and libcst into [otel] and [codemod] extras keeps pip install unsinkable to its core surface, while letting power users opt into the heavier integrations explicitly.
What's next for Unsinkable Ship
- Full-fidelity Anthropic adapter. The current translation layer covers
messages.createwith content blocks, system prompts,max_tokens,temperature, andstop_sequences. Streaming, tool use, and prompt caching are the next surfaces to translate so the adapter is a true superset ofanthropic-python. - More provider SDKs. Mistral, Cohere, and Google AI Studio all ship Python SDKs that could get the same drop-in treatment, with translation adapters where the provider's request shape diverges from OpenAI Chat Completions.
- Codemod expansion. Today
unsinkable wirerewritesfrom X import Ylines. The next step is handlingimport openaifollowed byopenai.OpenAI(...)constructor calls, and emitting a refactor commit that includes a CHANGELOG-style summary of what was modified. - Region-aware chaos. Simulate a regional outage by routing through a Virtual Model whose priority-0 target is a region-specific deployment of an integration, so the fallback story can be told at the geographic layer too.
- Sync with the gateway, both directions. Pair the shim with a TF policy exporter that emits
gateway-policyYAML alongside the application code, so the routing config that the app expects and the config the gateway enforces are always in lockstep. - Hosted dashboard. The current dashboard runs locally; a hosted-mode that accepts events from many agents over WebSockets would let teams see the same resilience picture in production without each developer running their own UI process.


Log in or sign up for Devpost to join the conversation.