-
-
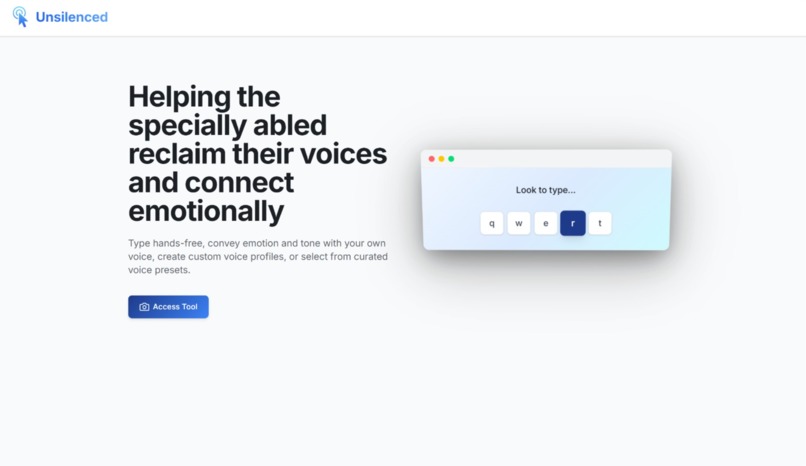
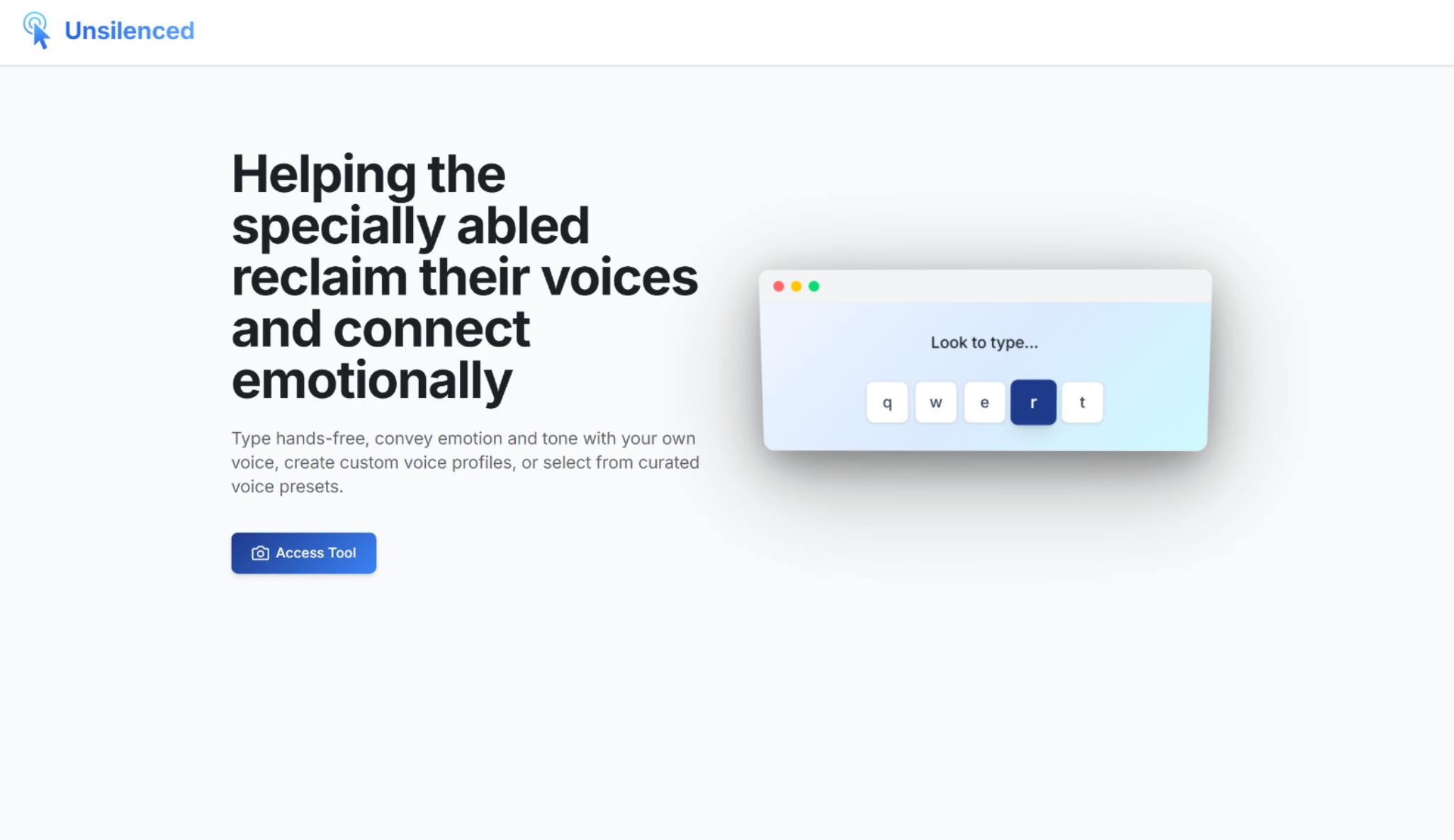
Landing Page
-
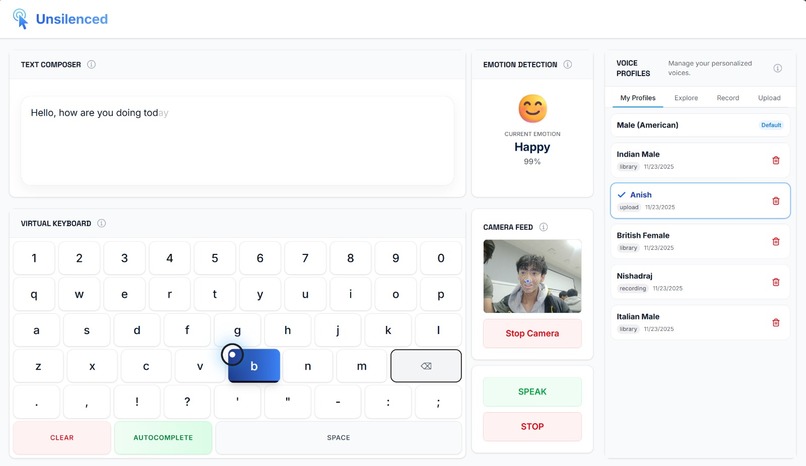
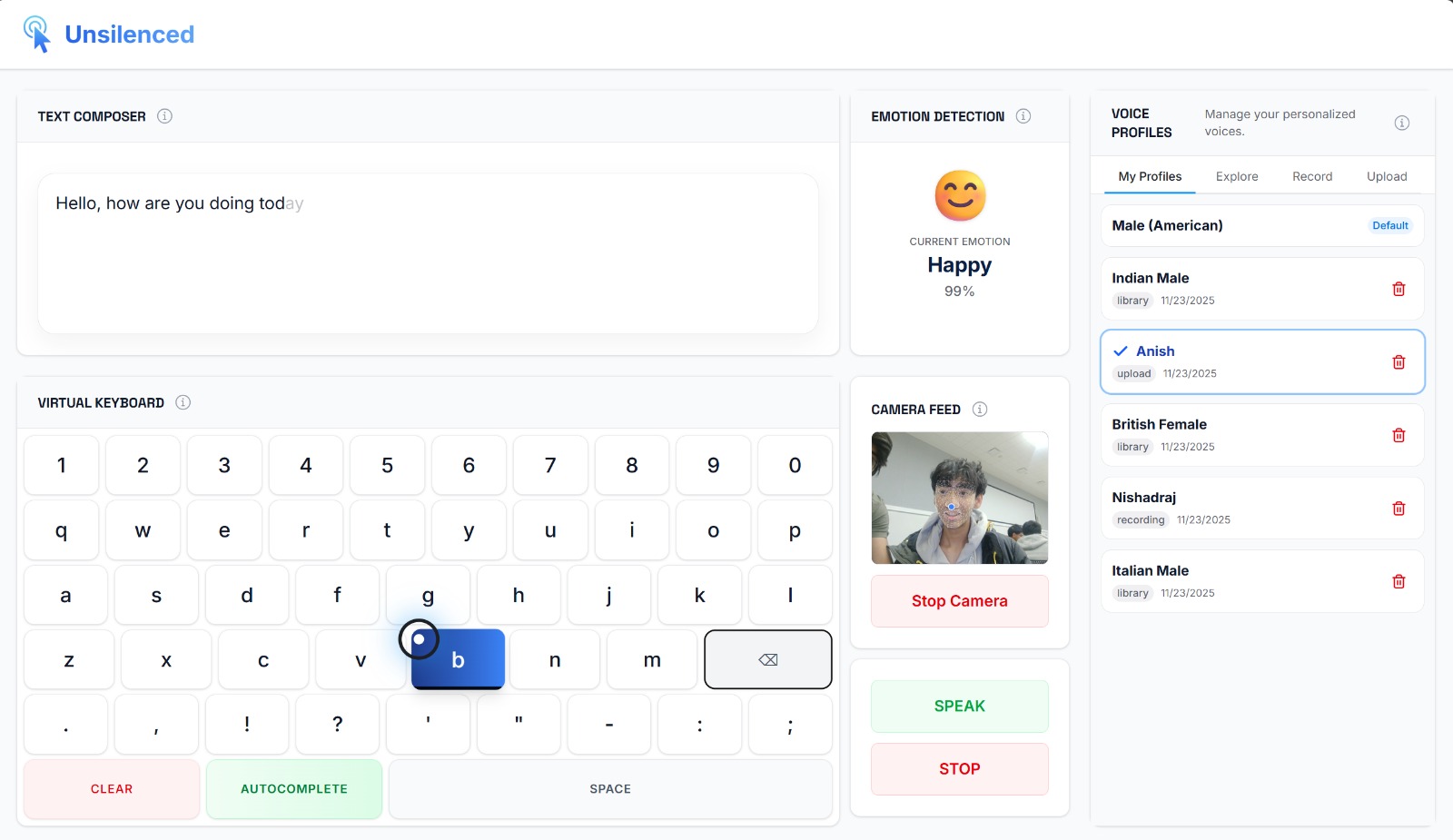
Home Page
Inspiration
Mainstream Augmentative and Alternative Communication (AAC) tools strip away the emotion and humanity from communication. This leads to robotic, monotone speech. A well-known case of this would be the AAC System connected to Dr. Stephen Hawking's famous chair. We wanted to help paralyzed and specially abled individuals not just communicate words, but express feelings in their assisted speech. This would help them reclaim the emotional connection that makes our conversations human.
What it does
Unsilenced is a hands-free AAC communication tool that uses the nose as a pointer to type and detect facial emotions in real time with the help of machine learning. It combines your typed text with detected facial emotions to generate natural-sounding speech through Fish Audio's AI. Fish Audio contextualizes the sentence for tone and modulation. Through the Fish Audio API, users can clone their own voice, search from thousands of curated AI voices, or create custom voice profiles tailored to themselves.
How we built it

The frontend is built using NextJS with MediaPipe Face Mesh for UV mapping and nose tracking. The emotion detection system is handled by Face API, which is powered by machine learning, for real-time facial expression analysis. This is where our track comes in: the voiceover is constructed by Fish Audio API for expressive TTS with emotion modulation. The backend is made with a Flask proxy server for voice cloning, as to avoid CORS errors from the browser. We also used the Fish Audio API to let users upload or record their own voices for use in the tool.
Challenges we ran into
About halfway through the project, we ran into a critical error. It was a CORS error that was caused by trying to access the Fish Audio API in a different domain without permission, and the error was being thrown by the browser for security reasons. To get past this, we created a proxy using Flask to act as a 'mediator' and the requests are passed to this proxy instead of directly to Fish Audio. Another challenge we ran into was that the AI had to output the same voice but with different tones depending on emotion. We tried a variety of options in the Fish Audio API to get exactly what we wanted, but in the end, modulating the speed and volume of the speech via the prosody object depending on the emotion was what worked for us in the end. The final major challenge we ran into was during the implementation of the (?) Information Bubbles. The tooltips were being cut off/hidden when you hovered over them because they were being clipped by their parent containers, but that was an easy fix with a little bit of custom CSS.
Accomplishments that we're proud of
We integrated a fully functional Computer Vision model that identifies emotions with ~84% accuracy, which is well above the average for even production-level models with long-term testing. Their average accuracy ranges from 75 to 80%. Both our model and the standard are measured on 6 classes and standard datasets. We built a back-end pipeline quick enough to keep up with real-time human conversations. We even ran a test to demonstrate this by comparing it to Dr. Stephen Hawking's voice synthesizer. Our question to the model was "Do you think we are alone in the Milky Way Galaxy as a civilization of our intelligence or higher?" The total time between typing and getting the output was 3 minutes and 21 seconds. At TED, Chris Anderson asked Hawking the same question. Hawking’s answer (about 35 words) took him seven minutes to generate via his speech‑synthesis system. Our model is over 100% faster than Dr. Hawking's synthesizer. And most importantly, we had fun :)
What we learned
We learned to work around browser CORS errors by building a Flask proxy, which acts as a server-side bridge for API calls. We also learned that the best way to pass the emotions to the Fish Audio API for our use case is through a prosody object. Combining MediaPipe, Face API, and Fish Audio required careful timing and state management to sync nose tracking, emotion detection, and speech synthesis. Processing facial recognition entirely client-side maintained privacy and improved performance. We found that small UX details like progress bars that cap at 95% until completion build more user trust than indefinite spinners even if it was not possible to make a fully accurate system. We also learned that breaking problems into smaller steps helped us pivot quickly when major obstacles appeared. Lastly, we realized that solving overlooked problems in accessibility technology can make a real impact even in the form of a hackathon project.
What's next for Unsilenced
We plan to continue developing Unsilenced. We will be adding support for multiple languages. This will continue utilizing Fish Audio API and its latest audio translation capabilities, and will make an impact on a much larger range of people around the world. It will ensure that people get access to our tool regardless of their ability to speak in English. We also plan to scale the tool into a full-blown application/product. Our first goal will be hitting 500 active users per month.
Built With
- css
- face-api.js
- fish-audio-api
- flask
- javascript
- mediapipe
- next.js
- python
- react
- tailwind
- typescript











Log in or sign up for Devpost to join the conversation.