-
-
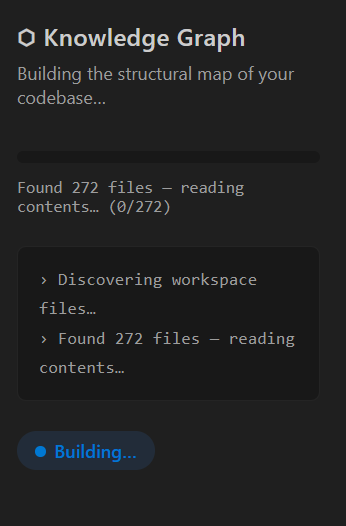
Knowledge graph
-
-

github repo
-
-
-
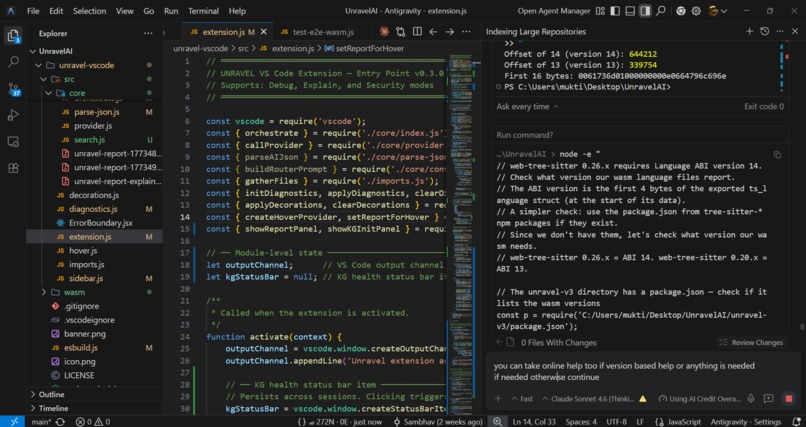
VS code extension
-
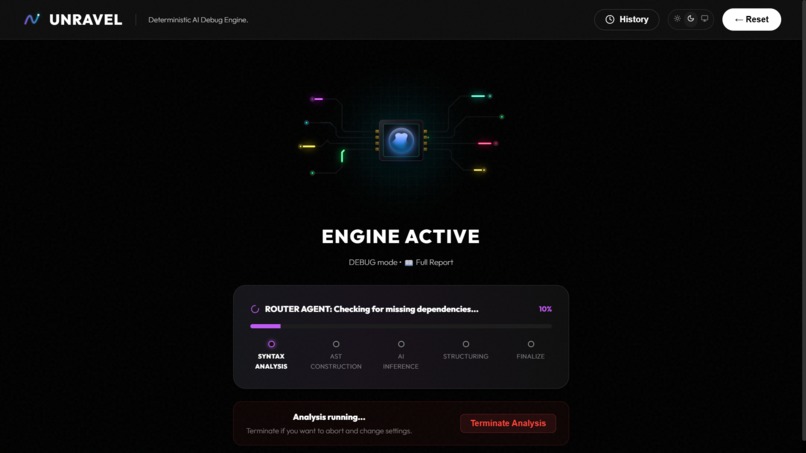
Webapp

I built Unravel because I kept running into the same problem while coding with AI.
I am a developer myself, and once I started using AI coding tools seriously, they sped up my work a lot. I could scaffold faster, debug faster, explore unfamiliar code faster, and generally move through development with much less friction.
But the more I used AI for real coding work, the more I noticed the uncomfortable part: AI is not just fast. It is also very good at sounding confident when it is wrong.
At first, I thought the main problem was hallucination.
- The AI might invent a root cause.
- It might cite a piece of code that does not exist.
- It might suggest a fix that sounds correct but is not actually supported by the code.
- And in larger codebases, it often loses track of what it read earlier.
So the first idea behind Unravel was simple: make AI debugging evidence-based.
Instead of letting an agent guess first, Unravel forces the workflow to start with real code evidence.
The core model became:
$$\text{Reliable AI Debugging} = \text{Verified Code Evidence} + \text{Structured Reasoning} + \text{Claim Verification}$$
But while building it, I discovered something more subtle.
Hallucination is the obvious failure. Context decay is the harder one.
When an AI agent reads one file, it may understand it well. But after reading four, five, or six files, the earlier details start turning into vague impressions. The specific line number, the invariant, the reason a section was ruled out, the connection between two files — all of that begins to blur.
By that point, the agent is not always hallucinating from nothing. It is often working from summaries of summaries.
That became one of the most important insights in Unravel: for large-codebase debugging, the problem is not only "does the AI know the answer?" It is also "can the AI preserve the right evidence long enough to reason correctly?"
What Unravel Does
Unravel is a reliability layer for AI coding agents.
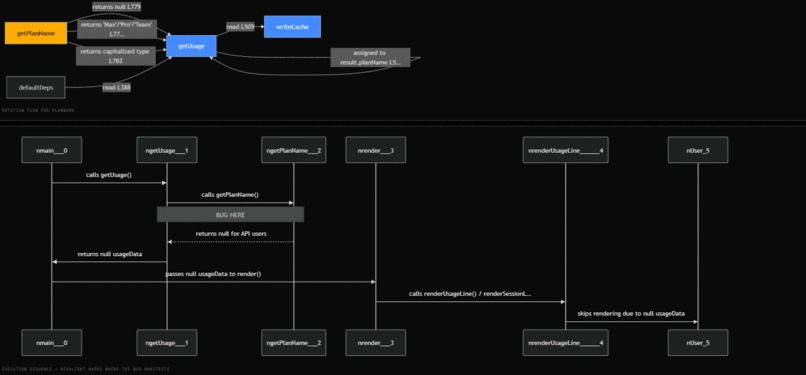
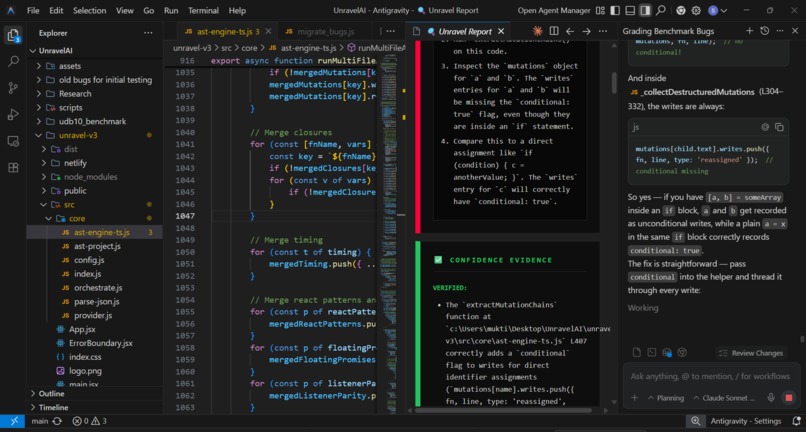
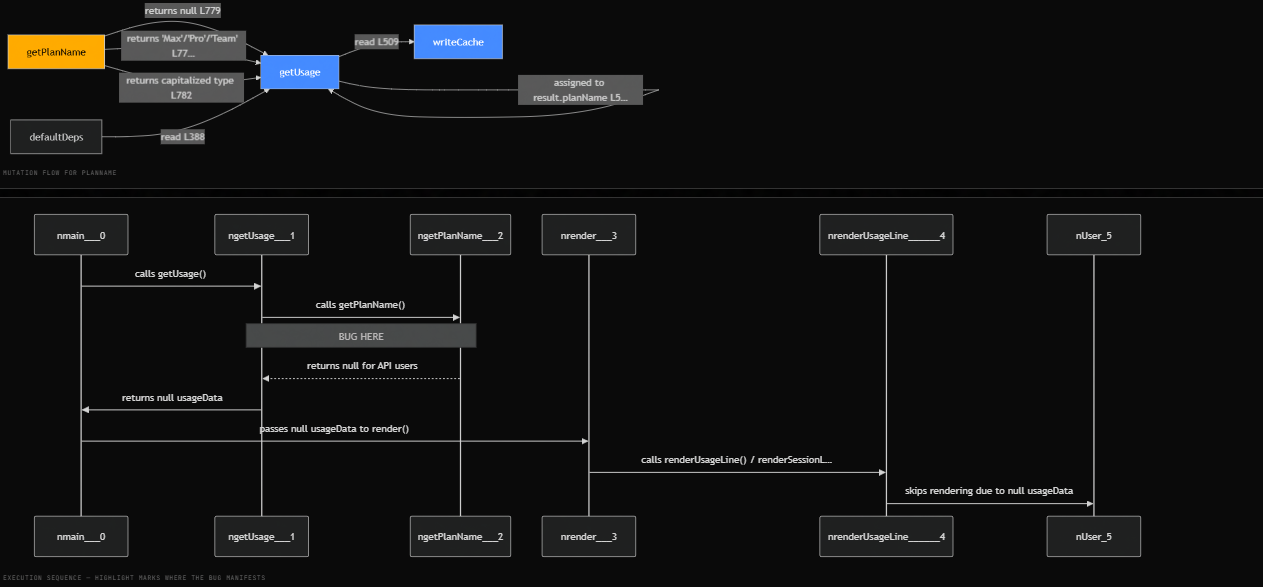
It uses deterministic static analysis to extract structural facts from code before the AI starts reasoning. It can surface evidence such as mutation chains, closure captures, async boundaries, race conditions, floating promises, constructor argument flows, property access maps, and cross-file call relationships.
The important design principle is that the AI model is not treated as the source of truth. The code is.
Unravel follows a Sandwich Protocol:
| Layer | Step | What happens |
|---|---|---|
| Base | analyze() |
Extracts verified AST facts from source code |
| Filling | Agent reasoning | Forms competing hypotheses — no jumping to one answer |
| Top | verify() |
Checks root cause, evidence, and fix against the real files |
This makes the agent slower to guess and better at proving what it claims.
The reasoning pipeline enforces structure at each phase:
- Hypothesis generation — exactly 3 mutually exclusive hypotheses, each with
falsifiableIf[]conditions stated upfront - Evidence mapping — per hypothesis:
supporting[],contradicting[],missing[], verdict - Adversarial confirmation — actively try to disprove each surviving hypothesis before committing to it
- Invariant check — state the invariants the fix must preserve, verify each one, revise once if violated
The verify() gate is the hard enforcement layer. It physically rejects any diagnosis that cites a
file:line pair absent from the parsed AST — not a warning, a PROTOCOL_VIOLATION.
How I Built It
Unravel exposes an MCP server with the following tools:
analyze— extracts structural evidence from source files via tree-sitter WASMverify— checks whether a diagnosis is actually grounded in the codebuild_map— builds a Knowledge Graph of a project (files, functions, imports, call edges)query_graph— routes a bug symptom to the most relevant files using keyword + semantic search + graph expansionquery_visual— screenshot-based routing for UI bugsdoctor— reports health and freshness of Unravel's project knowledge
For larger repositories, Unravel builds a Knowledge Graph that combines keyword routing, semantic embeddings, and graph expansion to find which files are likely relevant to a bug — so the agent knows where to look before it opens a single file.
I also built four compounding memory layers that grow with use:
| Memory layer | What it stores |
|---|---|
| Pattern Store | Structural bug signatures from verified fixes |
| Diagnosis Archive | Past verified diagnoses as embeddings for future recall |
| Task Codex | Task-scoped discoveries, decisions, and skip zones |
| Knowledge Graph | File structure, call edges, JSDoc summaries, embeddings |
The Task Codex became one of the most important parts of the project. It is not just a search system — it is a context-preservation system.
During a debugging task, the agent records only four types of entries:
| Marker | Meaning |
|---|---|
DECISION |
This exact line matters |
BOUNDARY |
This section is not relevant — skip it next time |
CONNECTION |
This file links to another file in the bug path |
CORRECTION |
An earlier assumption was wrong |
That means future sessions do not have to rediscover the same things from scratch. More importantly, the current session does not lose its own reasoning trail halfway through the task.
Challenges I Faced
The hardest part was separating three things that AI often blends into one confident paragraph:
- what the code proves
- what the agent suspects
- what the agent wants to fix
That led to strict gates:
- Root causes must cite real files and line numbers
- Hypotheses must be generated before verification begins
- Evidence strings must match actual file content
- Past memory can guide the agent, but cannot replace checking the current code
- Structural facts can be strong evidence, but they are not automatically a bug
Another challenge was large-codebase routing. Throwing an entire codebase into context and hoping the model keeps everything straight does not work. Unravel needed routing, graph search, semantic recall, and Codex pre-briefings to work at real scale.
The bigger lesson: anti-hallucination is not one feature. It is an architecture.
You need evidence extraction, hypothesis discipline, verification, memory, and honest uncertainty working together. Pull out any one piece and the others compensate poorly.
What I Learned
The biggest thing I learned is that hallucination is only the visible failure mode.
The deeper failure mode is context decay.
An AI agent can read the correct file, see the correct line, and still make a bad edit later because that evidence has degraded into a vague memory. This is especially dangerous in multi-file debugging, where the right fix depends on preserving small facts across many files.
That changed how I think about AI coding tools. The next generation should not only be better at generating code — they should be better at maintaining evidence over time.
Unravel is built around that idea: make the agent carry forward the exact things that matter, discard what does not, and verify claims before turning them into fixes.
We can express the core claim formally. Let \(F\) be the set of verified structural facts extracted from the AST, \(S\) the set of observed symptoms, and \(R\) the proposed root cause set. A reliable diagnosis requires:
$$R \subseteq F \quad \text{and} \quad R \vdash S$$
The LLM handles the inference \(R \vdash S\). The AST enforces \(R \subseteq F\). Neither can do the other's job.
Validation
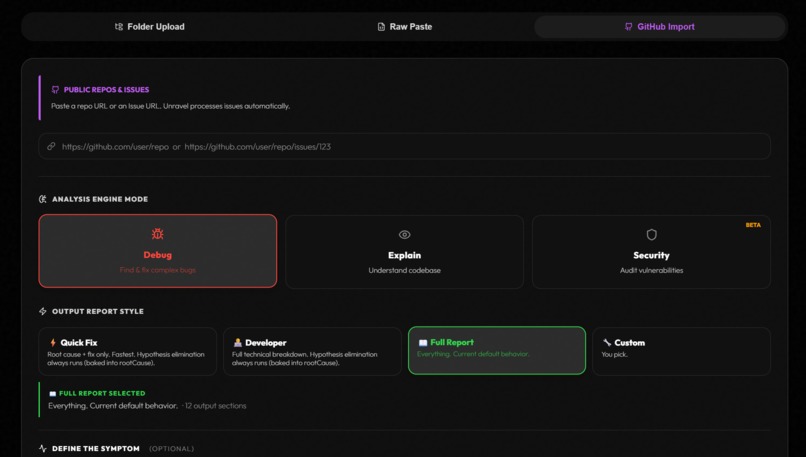
I tested Unravel through benchmark packages, manual blind trials, and real open-source contributions.
Benchmark results:
- 22 ground-truth packages
- 22/22
analyzecontracts passed - 19/22 root-cause files routed into top-K
Blind trial — no-API A/B on super-bug-ghost-tenant:
| Score | |
|---|---|
| Baseline (no Unravel) | 2 / 6 |
| Unravel-guided | 6 / 6 |
The strongest real-world validation was using Unravel on actual open-source repositories. I used it while working on issues that resulted in merged PRs in tldraw and cal.com — real codebases, real maintainers, real review, real acceptance criteria.
That is the signal I care about most: Unravel is not just passing controlled tests. It has already helped produce changes accepted in serious production-grade repositories.
What's Next
The next direction has three parts.
Opening the benchmark.
All 22 benchmark packages are publicly available for anyone to run, inspect, and verify independently. Every ground-truth file, symptom description, and expected root cause is documented. If you want to test Unravel against a specific bug, or challenge a result, the packages are there. The benchmark was constructed and graded honestly by me — which is exactly why the next step is moving toward something more credible.
Independent benchmarking.
The current benchmark suite was author-constructed and author-graded. That is an honest starting point, but the next step is evaluation against an independent, standardized benchmark — one where the issues, the ground truth, and the grading are not authored by the same person building the tool. The exact benchmark is still being scoped, since most existing benchmarks are designed to evaluate autonomous agents end-to-end rather than a diagnostic protocol that runs on top of one. That framing problem is itself worth solving correctly rather than quickly.
Real-world validation at scale.
Unravel's structural advantage is most visible on large repositories — the kind where an LLM either refuses to reason about the full codebase, consumes an enormous token budget to partially process it, or confidently produces a diagnosis that is not actually grounded in the code. The merged PRs on tldraw and cal.com were an early signal that Unravel works in that environment. The next step is to do this more systematically: take real open GitHub issues on large, active repositories, run Unravel-guided diagnoses, and submit fixes. Each accepted PR is a data point that does not depend on controlled conditions or author-graded rubrics.
The goal is a simple, honest answer to the question: does Unravel help fix bugs in real codebases that LLMs generally struggle with? Not on a synthetic benchmark. On actual code, with actual maintainers deciding whether the fix is correct.
Repo Atlas.
Beyond validation, the next architectural direction is the Repo Atlas — a deliberate, human-authored
knowledge layer at .unravel/atlas/ that captures what code structure alone cannot reveal:
- why a subsystem exists
- which APIs are frozen for backwards compatibility
- which flows carry legal or compliance constraints
- which invariants must never be violated even if the code technically allows it
This is architectural intent. No automated system can generate it correctly — it has to be human-gated, closer to Architecture Decision Records than generated summaries. If the Atlas becomes hallucinated documentation, it defeats the whole purpose.
The long-term vision is for Unravel to combine four layers:
$$\text{Understanding} = \underbrace{\text{Code Structure}}{\text{KG}} + \underbrace{\text{Past Bugs}}{\text{Archive}} + \underbrace{\text{Current Task}}{\text{Codex}} + \underbrace{\text{Architectural Intent}}{\text{Atlas}}$$
AI agents that do not just write code faster — but understand the evidence, preserve context, respect architecture, and verify their claims before acting.
Unravel is available as an MCP server, a Webapp, and as a VS code extension too, but the MCP version is what i am working on prominently due to its ease of access and functionality.
Future is Local first
Most AI coding agents depend on three fragile assumptions:
- The cloud LLM is available.
- The MCP/tool layer keeps working.
- The agent remembers enough context to stay reliable over long tasks.
Unravel challenges all three assumptions.
The current system focuses on making agent work auditable through evidence, verification, Task Codex memory, and real-world PR validation. The next architecture, unravel-local, makes this resilience local-first: local embeddings, local reasoning, local codebase memory, local pattern learning, and local pre-commit prevention.
If cloud LLMs fail, Unravel does not collapse into a blank error. It degrades into local evidence + local memory + local model. If the agent forgets, Task Codex and the diagnosis archive restore working context. If a risky pattern reappears, the pattern store and pre-commit guard can catch it without needing a cloud call at all.
Built With
- anthropic-claude-api
- embeddings
- faiss
- gemini-api
- github-actions
- graph
- javascript
- knowledge
- mcp
- node.js
- sarif
- search
- semantic
- sqlite
- tree-sitter-wasm
- vector
- vs-code-extension-api

Log in or sign up for Devpost to join the conversation.