

Inspiration
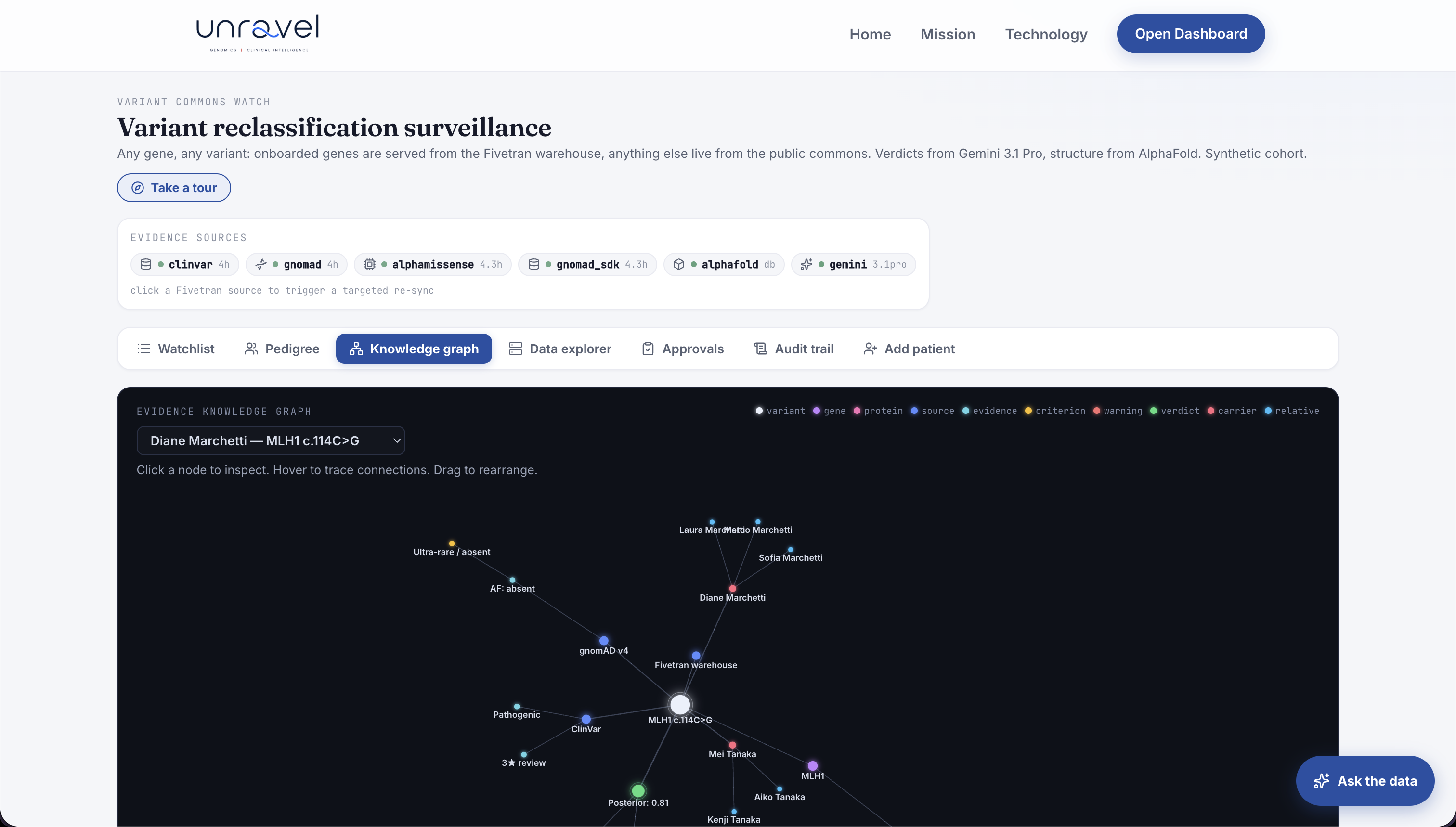
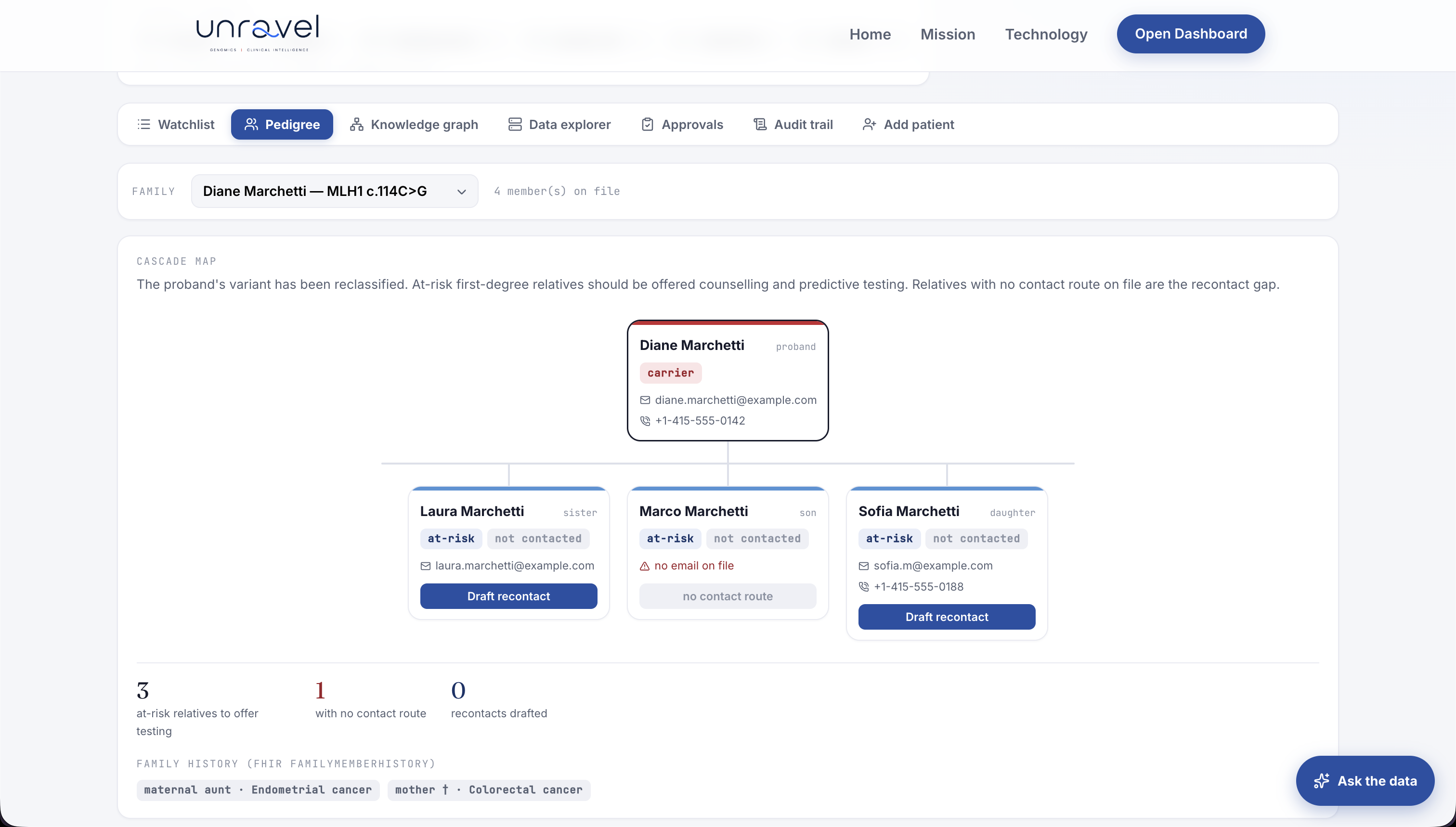
In 2019, a patient I'll call Diane, 44, had surgery for colorectal cancer. Her germline panel returned a Variant of Uncertain Significance (VUS) in MLH1, a Lynch syndrome gene. "Uncertain" means do nothing, so nothing was done; her oncologist said, "if it ever changes, we'll let you know." It changed, in 2023 a ClinGen expert panel reclassified that exact variant to likely pathogenic, and the update never reached Diane. Her 22-year-old daughter, who could have begun colonoscopies the day it flipped, later presented with a tumour Lynch surveillance is built to catch early.
This is the one diagnostic loop in medicine that stays open for years. I'm a cancer geneticist; the heart of my work, and my PhD, is deciding which genetic variants actually matter and which are harmless. So I meet this gap from the inside: I can spend years working out what a variant means, the field can move the answer, and still nothing carries it back to the family it was about. The interpretation is my discipline; the delivery of a changed interpretation is the part no one owns. That missing layer is what I built Unravel to be.
The science is mature; the automated response barely exists. Around 25% of reported VUS in hereditary-cancer testing are eventually reclassified (Mersch 2018, JAMA; 1.45M individuals), 41% of broad-panel patients carry at least one VUS, the burden higher in non-European ancestries (Chen 2023, JAMA Netw Open), and the duty to recontact when evidence changes remains an open question in the genetics literature (Otten 2015; Appelbaum 2020). That gap is Unravel.
What it does
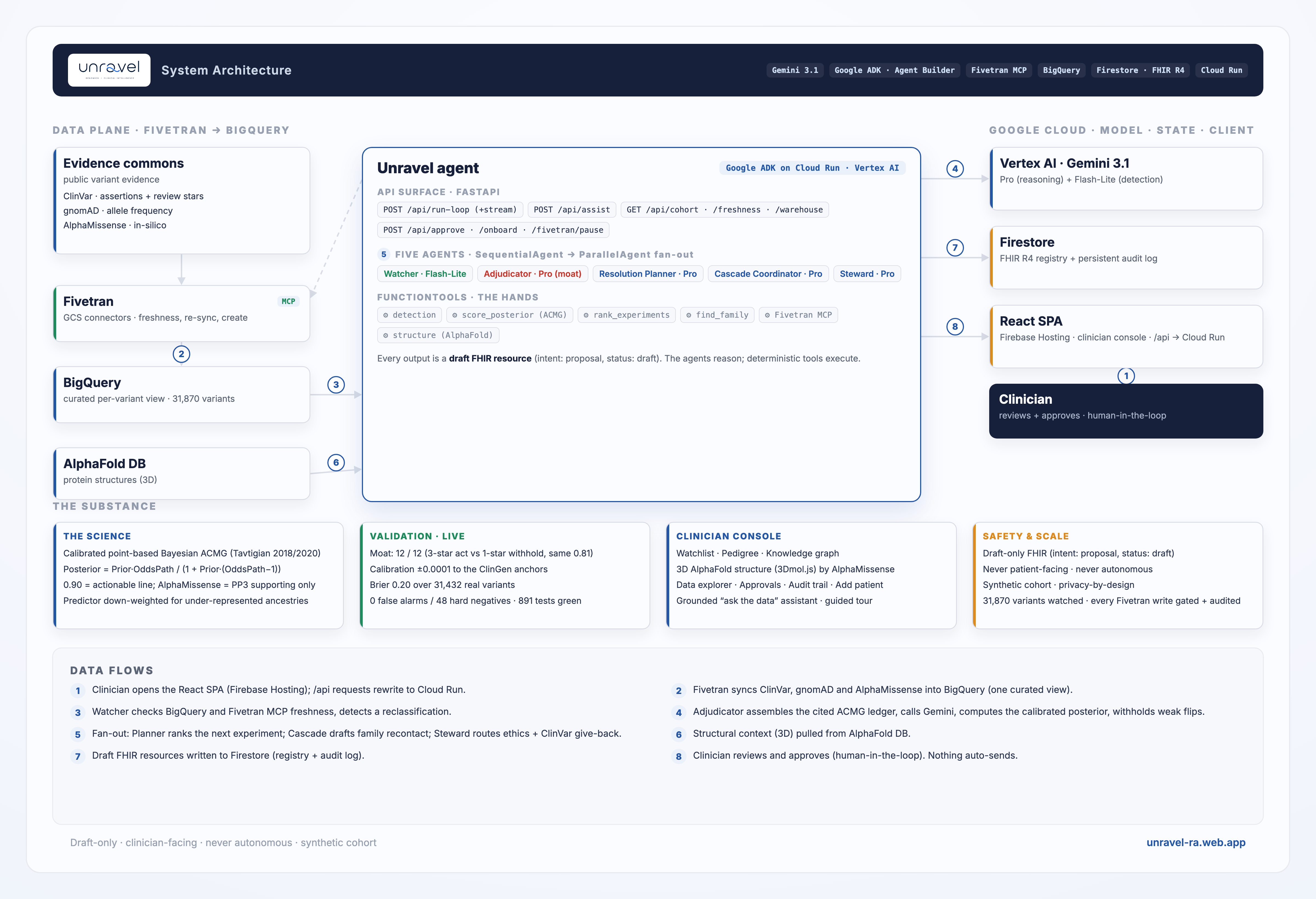
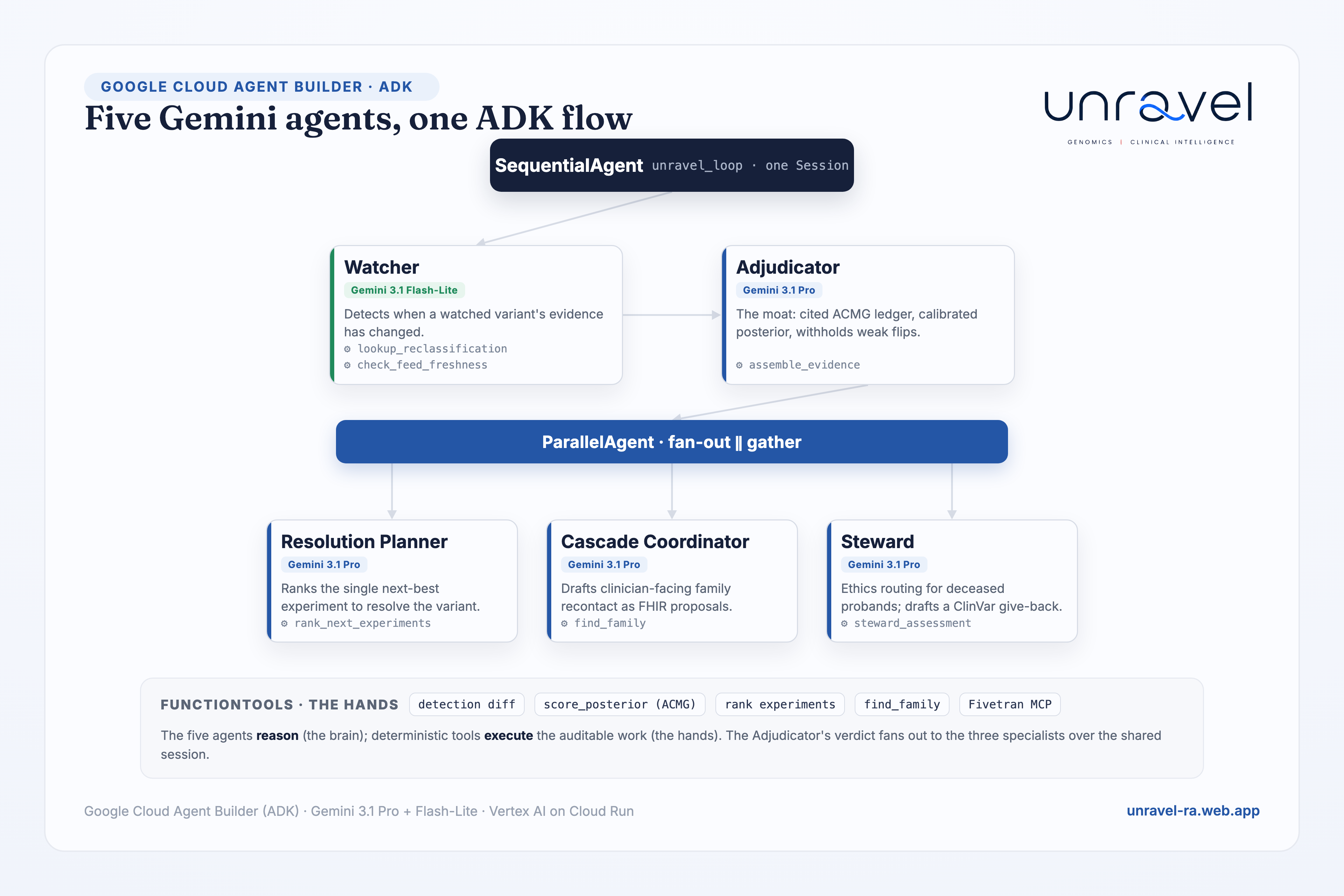
Unravel is the missing active layer between the global evidence commons (ClinVar, gnomAD, AlphaMissense) and the individual family, a genuine five-agent ADK system sharing one Session, each agent calling deterministic tools for the auditable work:
- Watcher (Gemini 3.1 Flash-Lite). Detects when a watched variant's evidence changes, against a clinic's registry of historical VUS. Fivetran is its heartbeat.
- Adjudicator (Gemini 3.1 Pro), the moat. Assembles a cited ACMG/AMP evidence ledger, computes a calibrated posterior probability of pathogenicity, and decides triage and action, withholding low-confidence flips.
- Resolution Planner (Gemini 3.1 Pro). For a variant short of the line, ranks every possible next experiment (segregation, tumour MMR/IHC, functional, splicing) by information value and names the single highest-yield move, in ACMG currency.
- Cascade Coordinator (Gemini 3.1 Pro). On a confirmed actionable upgrade, identifies at-risk relatives and drafts the clinician alert plus the family fan-out as draft FHIR resources.
- Steward (Gemini 3.1 Pro). Routes deceased-proband cases to ethics review (never a direct letter), and drafts a ClinVar submission back to the commons when evidence resolves a variant.
Asymmetric by design. Because most reclassifications are downgrades, Unravel surfaces the rare, life-changing upgrade loudly and handles the common downgrade as quiet reassurance. Its value is correct triage, not an alarm on every change.
Why this needs AI, not a rules engine
Three judgements a deterministic script cannot make, that the agent makes over cited evidence:
- Trust, not arithmetic. Two variants can carry identical molecular evidence, same rarity, same AlphaMissense score, same 0.81 posterior, yet warrant opposite actions because one is a 3-star expert-panel call and the other a 1-star conflicting submission. The agent acts on the 3-star and withholds on the 1-star, reasoning over review quality; a threshold cannot tell them apart. (This is Diane vs Eric in the demo.)
- Reconciling discordant evidence. Conflicting lab assertions, free-text criteria, population frequency and computational scores rarely agree. Weighing contradictory, cited evidence into a single calibrated posterior is reasoning, not a lookup.
- The next-best experiment. Computing which single unrun test would move a variant furthest toward resolution, in ACMG currency, is an inference no rule encodes.
Where determinism belongs, and stays: as tools the agents call, the change-detection diff, the posterior math, the FHIR envelope, plus the draft-only safety gate. The plumbing is auditable; the five agents do the judgement. That split is a deliberate design choice, not a compromise.
How we built it
- Agents: five real Gemini agents in a code-first Google ADK (Agent Builder) flow, a
SequentialAgentroot running Watcher → Adjudicator → aParallelAgentfan-out of Planner ‖ Cascade ‖ Steward over one shared Session; the deterministic work (detection, the calibrated posterior, experiment ranking, family matching, Fivetran MCP) runs asFunctionTools the agents call (the brain/hands split). On Cloud Run. - Models: Gemini 3.1 Flash-Lite for high-volume delta detection; Gemini 3.1 Pro for the hard reasoning (adjudication, planning, drafting).
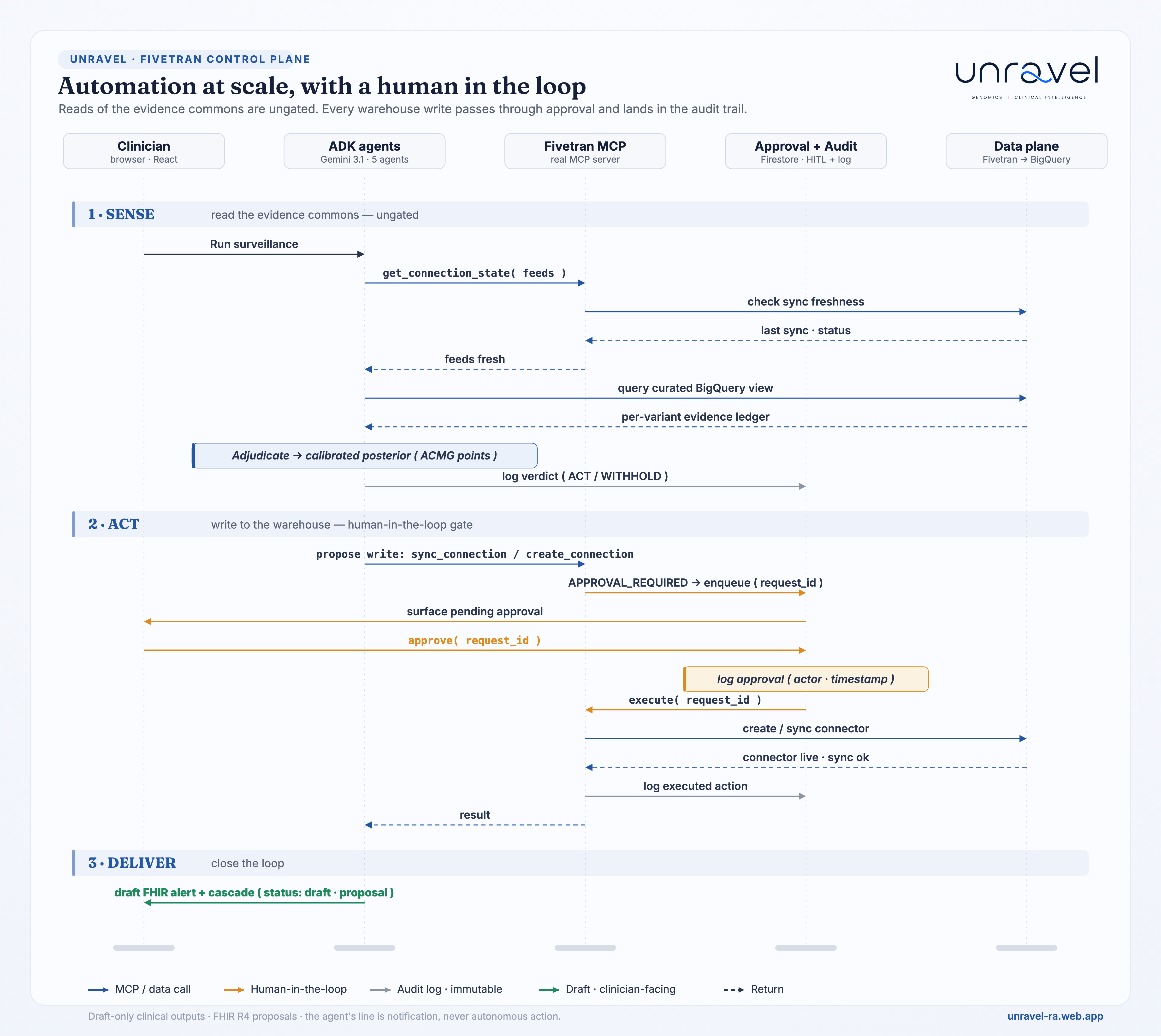
- Partner superpower, Fivetran (deep MCP): Fivetran syncs the evidence feeds into BigQuery, and the agent drives the real Fivetran MCP server inside the reasoning loop, baked into the Cloud Run image so the live app spawns the actual MCP, not just the REST API. It checks each feed's freshness before it rules, triggers targeted re-syncs, pauses and resumes connectors, and creates new connectors on demand (
create_connection) to onboard a gene into the warehouse once it is looked up often enough. Full CRUD on live connectors through natural agent actions, every one logged, not a singlecurl. - Evidence warehouse: BigQuery, a unified per-variant view joining ClinVar (assertions + decoded 0-4 star review status), gnomAD v4 allele frequency, and AlphaMissense on the GRCh38 coordinate (31,870 Lynch-gene variants).
- The science: a calibrated point-based Bayesian ACMG engine (Tavtigian 2018/2020). Total ACMG points convert to a posterior via
Posterior = (Prior x OddsPath) / (1 + Prior x (OddsPath - 1)),Prior = 0.10,OddsPath = 350^(points/8); anchors 6 pts = 0.90 (actionable), 10 pts = 0.994. AlphaMissense enters asPP3at the ClinGen-recommended calibrated strength (Pejaver 2022), never as the classifier, and is down-weighted a tier for carriers of under-represented ancestries (predictor-bias mitigation). - Structural story: the real AlphaFold model plus per-residue AlphaMissense, with pathogenic-neighbour clustering, so a one-line variant blooms into an interpretable 3D argument (3Dmol.js).
- Registry + write-back: FHIR R4 (Patient, Observation, FamilyMemberHistory) in Firestore; every output a draft FHIR resource (
intent: proposal,status: draft). - Frontend: React + TypeScript + Vite on Firebase Hosting, which rewrites
/apito the Cloud Run service (same-origin, no CORS). - Requirements, mapped (all invoked at runtime, no competing AI/cloud): Gemini 3.1 (Pro + Flash-Lite) on Google ADK / Agent Builder, called in
backend/unravel/agents.py(LlmAgent/SequentialAgent/ParallelAgent/Runner); a Fivetran destination (three GCS→BigQuery connectors + a curated view,sql/variant_evidence.sql) and the Fivetran MCP server spawned inbackend/unravel/fivetran_mcp.py(freshness, re-sync, pause/resume,create_connection); human-in-the-loop (draft-only outputs, every Fivetran write gated by approval); reproducible (scripts/setup_fivetran.py); live on Cloud Run + Firebase. All three required techs execute on every loop, verifiable in the app and the audit trail.
Validation and results
What carries the weight is the agents' judgement, validated on the live model, with the deterministic steps validated as correctness checks.
| What we measured | Result | What it shows |
|---|---|---|
| The moat, on the live Gemini 3.1 Pro Adjudicator | 12 / 12 correct, across 8 genes | With the molecular posterior held identical (0.81), it acted on every 3-star escalation, withheld on every 1-star at the same posterior, and reassured on every benign downgrade, the "arithmetically identical, opposite verdict" a threshold cannot make. |
| Calibration of the posterior | within 0.0001 of the ClinGen anchors | The engine reproduces the published Bayesian probabilities exactly. |
| Computational evidence alone | Brier 0.20 over 31,432 real Lynch variants | gnomAD + AlphaMissense do not determine classification, exactly why AlphaMissense is capped as supporting evidence. |
| Detection specificity | 0 false alarms on 48 hard negatives | The Watcher ignores cosmetic ClinVar text churn and fires only on real category crossings. |
| Validation cohort | 600 synthetic FHIR patients, 16 genes | Carrying variants with real ClinVar reclassification history; 484/600 of under-represented ancestry. |
| Test suite | 74 functions, 891 cases (all green) | Engine + all five agents: abstention, withhold, deceased-proband routing, cascade fan-out. |
| A real-data finding (ours) | ~78% of reclassifications are downgrades (1,003 / 1,285) | The empirical basis for the asymmetric design. |
The moat result is precisely scoped: the agent is given the clinical principle, not the per-case answer, so it demonstrates reliable, generalising judgement, not a single demo pair.
Every result here is one we can stand behind. The headline evidence, the live Adjudicator's judgement and the calibration on 31,432 real variants, is independent and non-trivial; the deterministic steps are validated as correctness checks. The cohort is synthetic patients carrying real variants: a research prototype, rigorously evaluated, not yet clinically validated.
Challenges we ran into
- Real, dated reclassification data. A backtest is only credible on variants that genuinely changed over time, so we mined ClinVar's public
variant_summary+submission_summarydumps into a balanced 100-variant ground-truth set with dated trajectories. - Holding the eval to an honest bar. Our first detection backtest scored a perfect 1.0, until we caught that it was effectively grading itself. We rebuilt it around the live Adjudicator and hard negatives, so the headline numbers measure the AI's judgement, not the plumbing's.
- Deep partner integration. Wiring multiple Fivetran MCP operations into the reasoning loop (freshness, targeted re-sync) rather than a one-shot pull, and making it run on Cloud Run.
- Calibration that survives an expert. Implementing the published Bayesian framework exactly, so the posterior is defensible to a geneticist, not a confidence number we invented.
Accomplishments we're proud of
- A genuine five-agent system with distinct data and distinct clocks, not one prompt in a trench coat, shipped live end to end (Firebase + Cloud Run + Vertex/Gemini + BigQuery + Firestore), no login.
- A calibrated, cited posterior whose maths is published science, validated to the anchor probabilities.
- The ancestry-aware bias mitigation, visible live: the same variant yields a lower molecular posterior for an under-represented-ancestry carrier, while the expert review still drives the action.
- The structural story: a confusing text variant rendered as a real 3D AlphaFold structure with its pathogenic neighbourhood.
- Built solo, by a cancer geneticist, so the next-best-evidence reasoning encodes clinical judgement a code-only competitor cannot fake.
What we learned
- The science of variant interpretation is mature and well-cited; the automation of the response is nearly absent. That gap is the opportunity.
- Intellectual honesty is a feature, not a weakness: naming the limits (predictor bias, the downgrade majority, the recontact ethics debate, a circular metric) is what earns a clinician's trust. In clinical AI, overclaiming is what destroys credibility.
- Tight, deep scope beats breadth: one loop done fully, and that focus is what let several genuine differentiators emerge, the calibrated withhold (identical posterior, opposite verdict), the next-best-evidence planner, ancestry-aware predictor bias mitigation, the deep Fivetran MCP control plane, and the 3D structural argument.
What this is NOT (the honesty section)
- Not a diagnostic device. It is clinical decision support; ACMG classification stays with experts.
- Draft-only, clinician-facing, never patient-facing, never autonomous. The agent draws its line at notification, not action.
- Privacy-safe by design. The demo processes only synthetic patients, so no PHI and nothing HIPAA or GDPR governs is ever handled. The architecture embodies the principles those frameworks require (data minimization, privacy-by-design, full provenance, human-in-the-loop). It is built to slot into a clinical compliance program; the remaining work to a real deployment is organizational (BAAs, DPAs, security audit), not architectural. We do not claim to be "compliant", that is an audited status.
- AlphaMissense is capped supporting evidence, not the authority, and carries known ancestry bias (Pathak 2024; Livesey & Marsh 2024). We contain its influence (multi-source ledger, ancestry down-weighting) and disclose its limits; we do not claim to have fixed the bias.
- Asymmetric on downgrades. We do not imply every VUS is a ticking bomb.
- The deceased-proband path routes to ethics review, not a letter. There are no settled guidelines for disclosing a dead patient's reclassified VUS to relatives.
- Synthetic patients, real variants. A research prototype: the patients are synthetic, the variants and their reclassification histories are real. Not a clinical product, and not yet clinically validated, the natural next step is a counsellor-in-the-loop study.
What's next for Unravel
- Onboard more genes into the Fivetran warehouse. The engine is already disease-agnostic, any gene resolves live from the commons; warehoused genes are simply served faster and richer. And add evidence feeds: OncoKB / CIViC and a splicing predictor (SpliceAI).
- A prospective evaluation: run the live Adjudicator over a larger held-out set than the current 12-case sample.
- Move from FHIR-shaped JSON in Firestore to a real FHIR server (e.g. HAPI FHIR), exposing the standard FHIR REST API an EHR can query and validate against, and wire the give-back to the actual ClinVar submission API.
- A clinician pilot, with a genetic counsellor in the loop, to validate the draft outputs in a formal study.
Try it
- Live demo (no login): https://unravel-ra.web.app
- Repository: https://github.com/faith-ogun/Unravel
- 3-minute video: https://youtu.be/xJBBBiFeQWk
- Control plane, in one frame: the sequence diagram in the media gallery (
unravel-handshake-sequence) traces every handshake end to end, between the clinician, the five ADK agents, the live Fivetran MCP server, the approval queue and the data plane. Reads of the evidence commons are ungated; every warehouse write passes through a human approval and lands, immutable, in the audit trail. - Track: Fivetran
- Built by: Faith Ogundimu (solo), cancer geneticist (PhD cancer genomics)
References
Bayesian ACMG framework:
- Richards S, et al. Genet Med. 2015.
- Tavtigian SV, et al. Genet Med. 2018.
- Tavtigian SV, et al. Hum Mutat. 2020.
Computational predictors at calibrated strength:
- Cheng J, et al. AlphaMissense. Science. 2023.
- Pejaver V, et al. Am J Hum Genet. 2022.
- Bergquist T, et al. Genet Med. 2025.
ClinGen interpretation rules:
- Abou Tayoun AN, et al. (PVS1) Hum Mutat. 2018.
- Brnich SE, et al. (PS3/BS3) Genome Med. 2019.
- Walker LC, et al. (splicing) Am J Hum Genet. 2023.
- Thompson BA, et al. (InSiGHT MMR) Nat Genet. 2014.
ClinVar discordance:
- Landrum MJ, et al. Nucleic Acids Res. 2014.
- Harrison SM, et al. Genet Med. 2017.
- Balmaña J, et al. J Clin Oncol. 2016.
Reclassification prevalence / reanalysis:
- Mersch J, et al. JAMA. 2018.
- Chen E, et al. JAMA Netw Open. 2023.
- Mighton C, et al. Genet Med. 2019.
- Wright CF, et al. Genet Med. 2018.
- Wenger AM, et al. Genet Med. 2017.
Cascade / recontact / ethics:
- Frey MK, et al. J Clin Oncol. 2022.
- Caswell-Jin JL, et al. J Natl Cancer Inst. 2019.
- Otten E, et al. Genet Med. 2015.
- Bombard Y, et al. Am J Hum Genet. 2019.
- Appelbaum PS, et al. Genet Med. 2020.
FHIR genomics / interoperability:
- Alterovitz G, et al. J Am Med Inform Assoc. 2015.
- Warner JL, et al. J Am Med Inform Assoc. 2016.
- Osterman TJ, et al. (mCODE) JCO Clin Cancer Inform. 2020.
Population frequency:
- Karczewski KJ, et al. (gnomAD) Nature. 2020.
- Gudmundsson S, et al. Hum Mutat. 2022.
National genomics initiatives:
- All of Us Genomics Investigators. Nature. 2024.
- 100,000 Genomes Pilot Investigators. N Engl J Med. 2021.
- Sosinsky A, et al. Nat Med. 2024.
AI + the predictor-bias caution:
- Singhal K, et al. (Med-PaLM) Nature. 2023.
- Frazer J, et al. (EVE) Nature. 2021.
- Pathak AK, et al. bioRxiv. 2024.
- Livesey BJ, Marsh JA. bioRxiv. 2024.
Protein structure:
- Jumper J, et al. (AlphaFold) Nature. 2021.
- Rego N, Koes D. (3Dmol.js) Bioinformatics. 2015.
Reclassification impact, recontact, cascade (added):
- Makhnoon S, et al. Cancer Med. 2023.
- Ahsan MD, et al. PEC Innov. 2023.
- Lascurain E, et al. J Genet Couns. 2024.
Built With
- 3dmol.js
- alphafold
- alphamissense
- bigquery
- cloud-run
- fastapi
- fhir-r4
- firebase-hosting
- firestore
- fivetran
- fivetran-mcp
- gemini-3.1-flash-lite
- gemini-3.1-pro
- google-adk
- pytest
- python
- react
- typescript
- vite

Log in or sign up for Devpost to join the conversation.