-
-
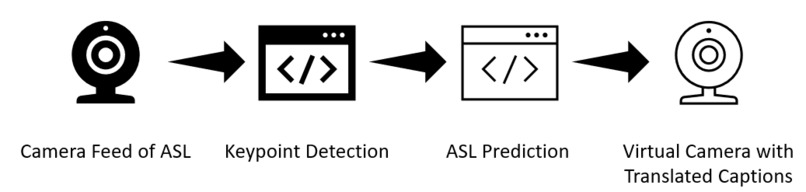
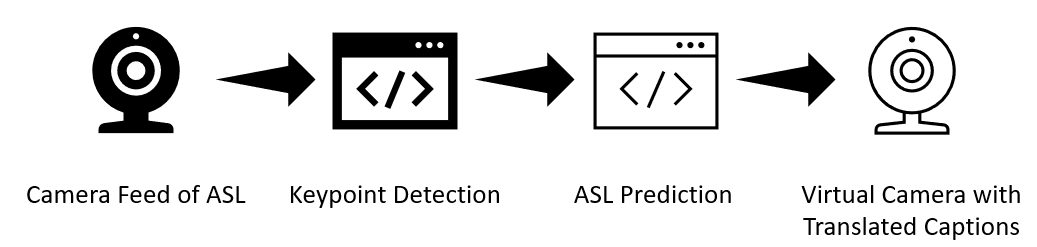
System Workflow
-
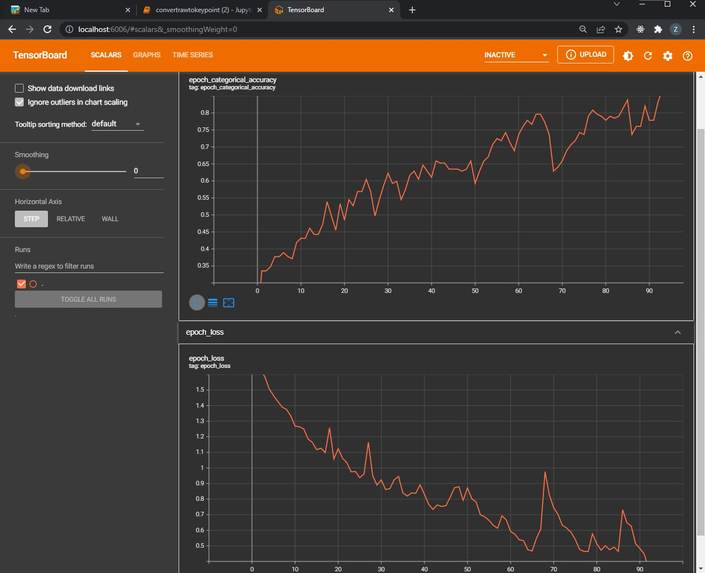
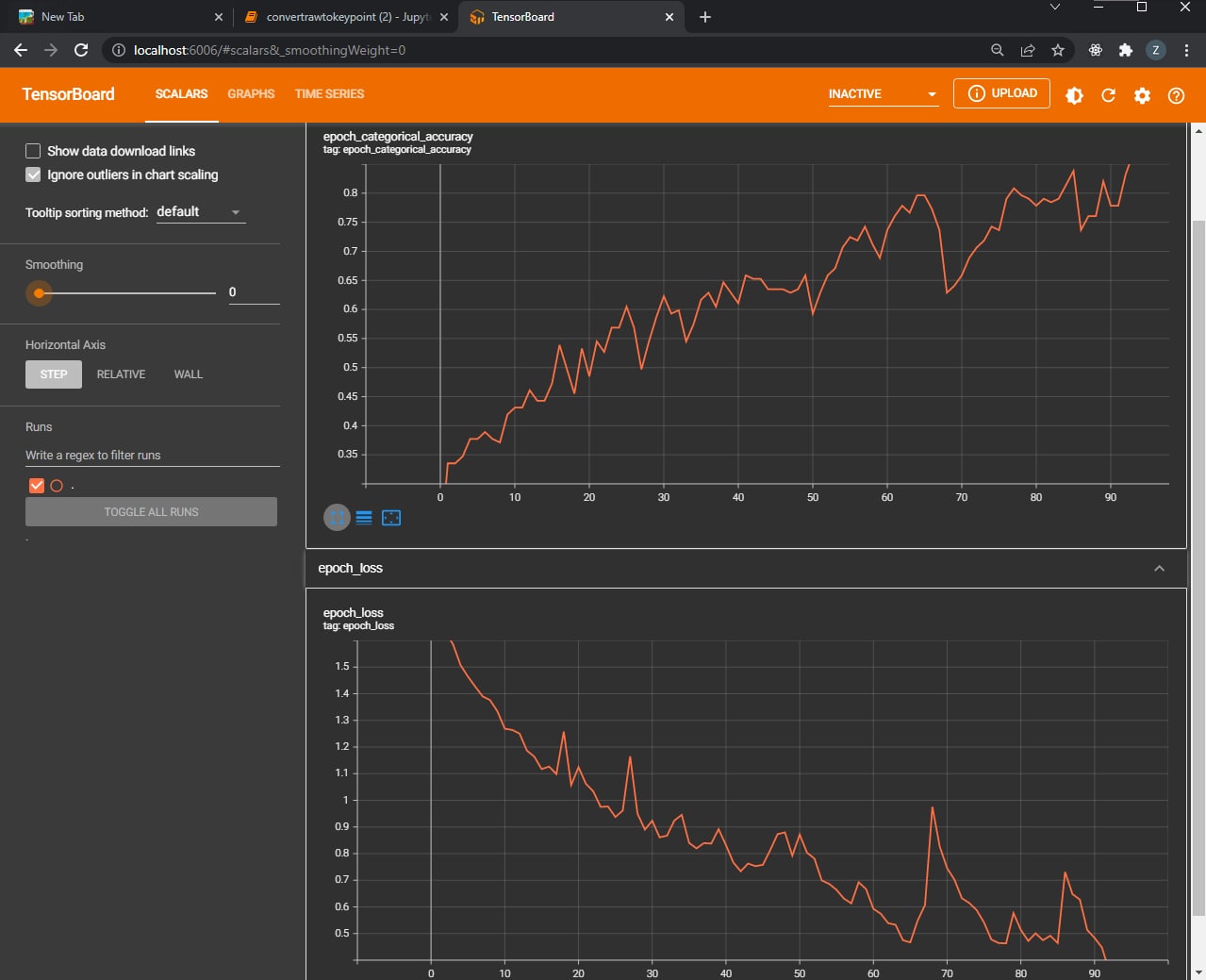
Tensorboard documentation
Inspiration
Do you recall that lawyer that was stuck with a cat filter? Video filters have become commonplace on Instagram Stories, Tik-Tok and even Zoom in light of COVID-19. Although they are fun, they provide little value. What if we made video filters a powerful accessibility tool?
Did you know that 1 in 11 people in Singapore suffer from hearing impairments, our teammate Haozhi :( included. Some of these people are unable to communicate verbally, instead relying on sign language. Majority of society are unable to understand sign language and hence hearing-impaired people may feel excluded from society. While one can say why not just type their words?, well this is because it is much more natural to sign rather than type, similar to how you would rather speak in a call than type in the chat. Inclusivity is all about making everyone feel at home and thus our idea is to develop a solution that allows the deaf to 'speak' naturally, be it to their friends, colleagues or at job interviews.
What it does
Our solution, UnMuTeD, is a video filter that can be applied to most video-calling apps, such as Zoom, Discord, etc. It translates sign language to english captions and displays it directly into the video-call so that the layman can understand ASL. Currently, the model is able to translate 6 commonly used words as follows:
afternoon, bye, fine, good, hello, morning
How we built it
Some of the technologies used in this project includes machine learning with recurrent neural networks (RNN), data science, computer vision and virtual cameras.
Training
- We obtained the initial dataset from WLASL and then supplemented the data with our own videos when we found that model accuracy was too low.
- We then processed the videos into keypoints* to prepare the data to be fed into the model
- Our model architecture was adapted from models with similar purposes and then fine-tuned through trial and error.
- We managed to obtain an categorical accuracy of 0.88%
*location of important features such as fingers, facial expressions and pose.
Deployment
- The python script accesses the webcam and passes the video stream into the first machine learning model (from mediapipe) which predicts and returns the location of the keypoints.
- These keypoint data will then be passed into our RNN model which makes a prediction based off the last few seconds of keypoints. This prediction will then be visually drawn onto the video before returning it.
- The returned video stream can be accessed through a virtual camera (OBS-VirtualCam) which can then be chosen as the camera in video-calling apps, effectively applying the filter.
Challenges we ran into
As with all data science projects, we ran into the issue of lack of data. The data from the initial dataset was insufficient and we had to scramble to add our own videos. The performance of the model was unfortunately not as good during deployment and we think this may be due to the dataset containing a diverse group of people.
Another challenge we did not foresee was the lack of knowledge of ASL and how it works. Our solution may not fully represent ASL correctly.
Accomplishments that we're proud of
We are definitely proud of completing this project! One feature we thought was very cool was how we were able to make this filter easily accessible to those who are not tech-savy, with simple instructions in the github repository and continues to be in line with the theme of accessibility.
What we learned
It was our first time experimenting with RNNs and we learnt the basics of designing architecture. Another interesting technology was the mediapipe model and its keypoint predictions. It opens up a slew of possibilities for future projects.
What's next for unmuted
More words would be a good start. We would also like to look into building these filters directly into the video-calling apps such as Zoom directly through the API, so that its even more accessible! Another thing that would be helpful is to engage with those who use ASL in their daily lives to get a feel of what proper ASL is like. On a parting note, we may also look into crowdsourcing videos, such that the model can be expanded.



Log in or sign up for Devpost to join the conversation.