-
-
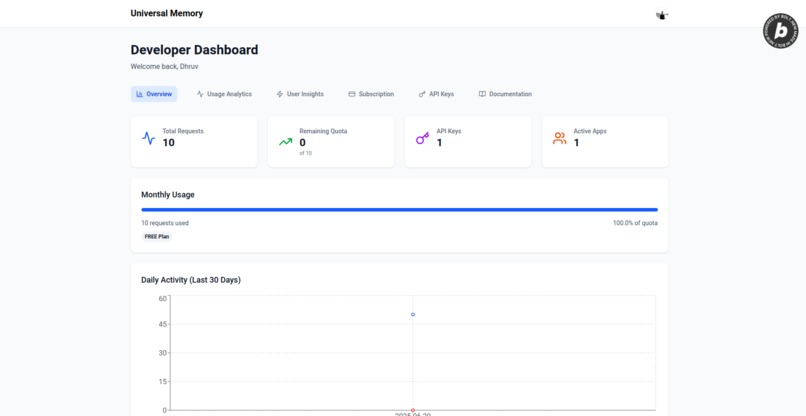
Dashboard #1
-
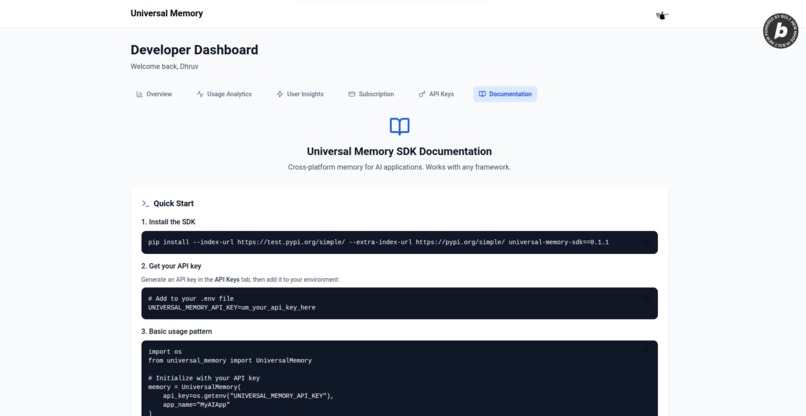
Dashboard #2
-
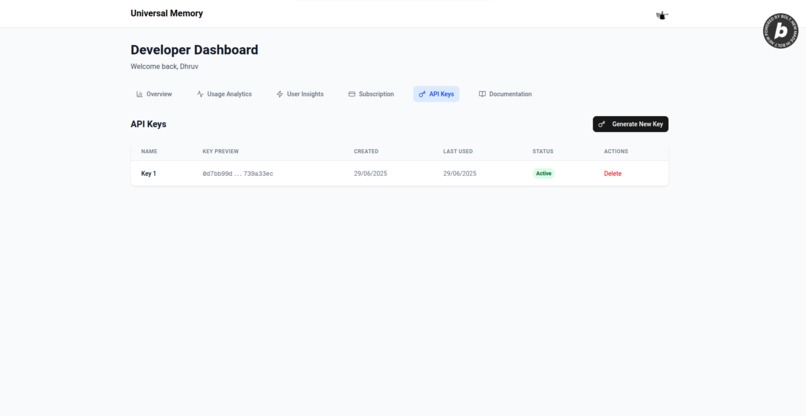
Dashboard #3
Inspiration
The current landscape of AI assistants and chatbots is fragmented—each platform operates in isolation, unaware of a user’s history or preferences from other systems. This siloed memory approach severely limits the quality of contextual understanding and continuity across experiences. We were inspired to build a universal memory layer that enables seamless context-sharing across large language model (LLM) applications, no matter which company or interface the user interacts with.
What it does
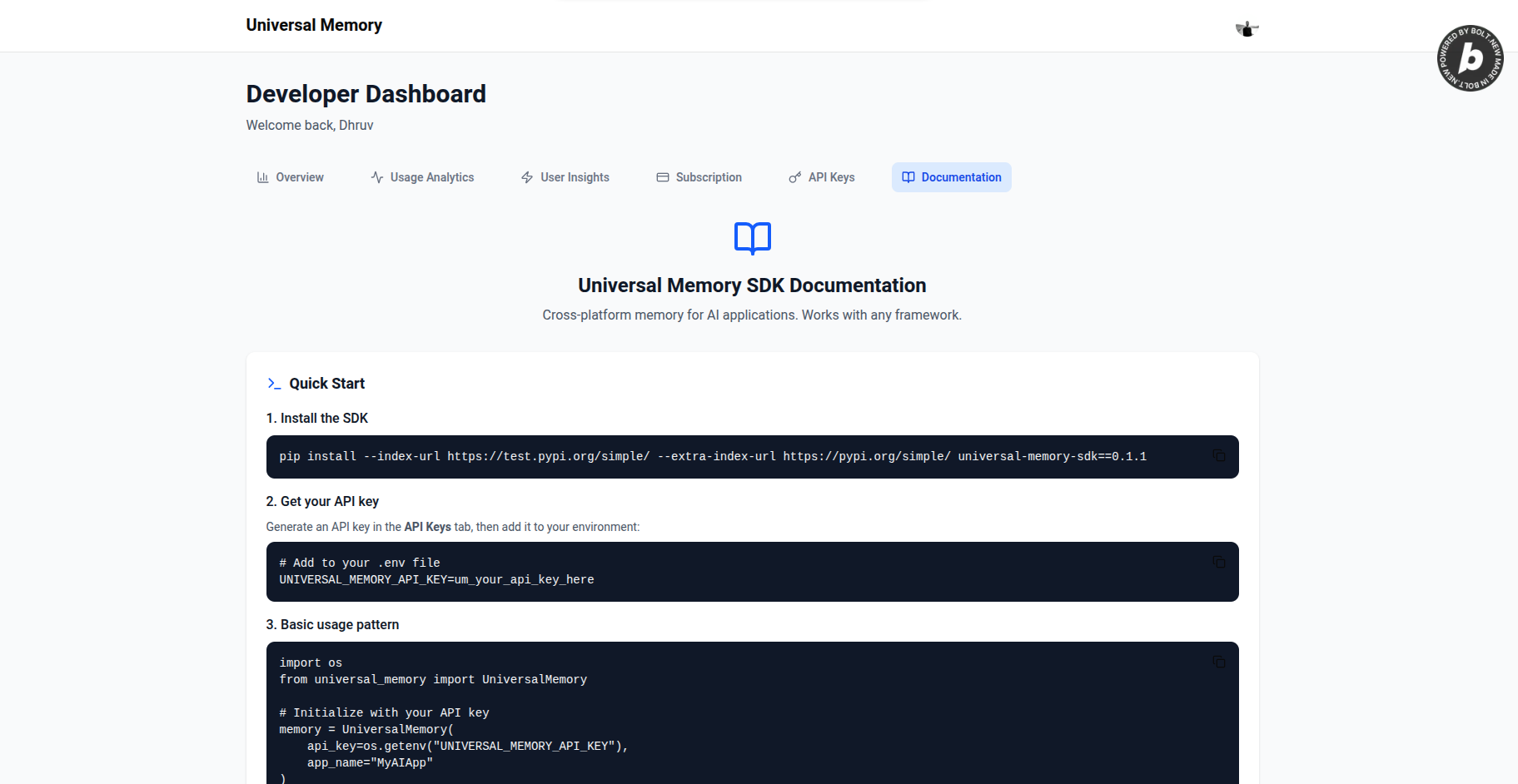
Universal Memory SDK is a cross-platform abstraction layer for memory and context in LLM applications. It standardizes how user interactions, preferences, and context are stored and accessed, making it possible for different AI assistants and chatbots to share memory securely. With this shared memory, assistants can provide more personalized, coherent, and high-quality responses—even when the conversation spans multiple platforms or services.
How we built it
We built Universal Memory SDK as a comprehensive system with three main components:
Python SDK: Built with UV dependency management, httpx for robust API communication with retry mechanisms, and comprehensive validation. Features email-based user identification with SHA-256 client-side hashing for true privacy, framework-agnostic memory interface that works with any AI framework (LangChain, LangGraph, custom code), and app-level context scoping for memory isolation.
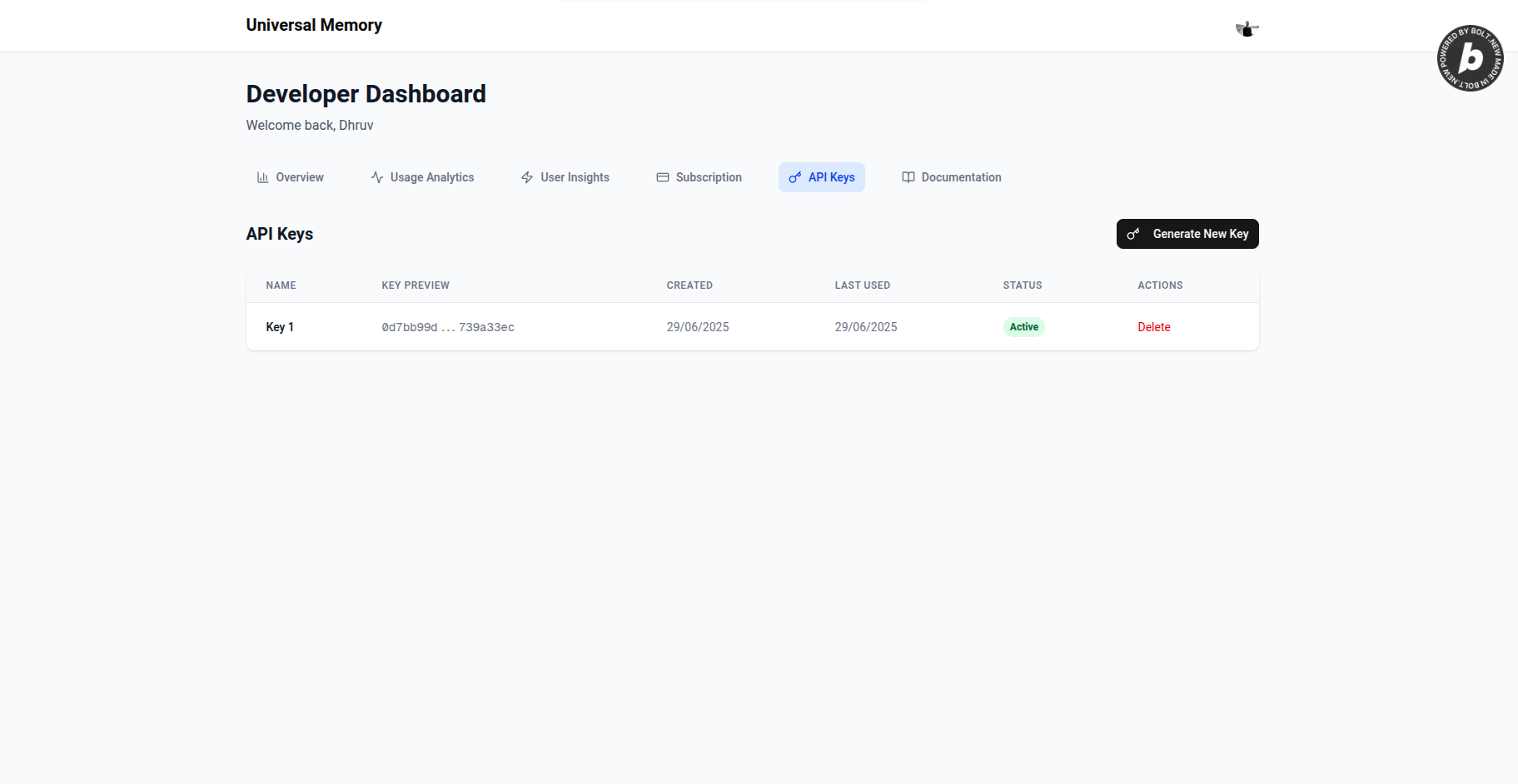
Next.js Dashboard: Developer-facing web application built with Next.js 15, Clerk authentication, and Tailwind CSS. Includes comprehensive API middleware stack for authentication and usage tracking, tiered subscription model (100/1000/10000 requests/month), and real-time usage analytics with Supabase backend.
Privacy-First Architecture: Implemented true privacy where emails are SHA-256 hashed client-side before transmission—the backend never sees actual email addresses. Added semantic search using OpenAI embeddings, AI-generated context summaries with GPT-3.5-turbo, and context insights that process raw memories into structured insights without exposing private conversations.
Challenges we ran into
Privacy Architecture: Designing a system that enables memory sharing while maintaining true privacy required implementing client-side email hashing and ensuring the backend never sees raw user data.
Framework Agnosticism: Creating a memory interface that works seamlessly across different AI frameworks (LangChain, custom implementations, etc.) without imposing specific patterns or dependencies was technically challenging.
Scalable Usage Tracking: Building a comprehensive usage tracking system that handles tiered subscriptions, quota enforcement, and detailed analytics while maintaining performance required careful database design and caching strategies.
Semantic Search Implementation: Integrating OpenAI embeddings for semantic similarity while providing graceful fallbacks when AI services are unavailable required robust error handling and retry mechanisms.
Accomplishments that we're proud of
Complete Production System: Built a fully functional SDK with Python package, Next.js developer dashboard, comprehensive API middleware, and Supabase database backend with proper authentication and usage tracking.
True Privacy Implementation: Achieved genuine privacy protection through client-side SHA-256 email hashing—backend services never see actual email addresses, only cryptographic hashes.
Framework-Agnostic Design: Created a memory interface that works seamlessly with any AI framework (LangChain, LangGraph, custom implementations) without vendor lock-in.
Advanced AI Features: Implemented semantic search using OpenAI embeddings for enhanced context retrieval and AI-powered context summaries for better insights.
Developer Experience: Built comprehensive tooling including API key management, usage analytics, health monitoring, and detailed documentation for easy integration.
What we learned Developers are eager for shared context, but trust and control over data are essential to adoption.
LLMs become significantly more powerful when given persistent, cross-platform memory—not just longer context windows.
A modular approach with standardized interfaces makes adoption easier for both open-source and enterprise users.
What's next for Universal Memory SDK
Enhanced AI Capabilities: Expand beyond GPT-3.5-turbo to support multiple AI providers for embeddings and summaries, implement advanced context processing with conversation clustering and automatic tagging.
Broader Framework Support: While we already support framework-agnostic integration, we plan to create dedicated plugins for popular frameworks like LlamaIndex and Semantic Kernel for even easier adoption.
Scale and Performance: Implement vector database integration for faster semantic search, add real-time synchronization capabilities, and optimize for high-volume enterprise usage.
Developer Tools: Build comprehensive SDKs for additional languages (JavaScript/TypeScript, Go, Rust), create visual memory exploration tools in the dashboard, and add advanced analytics and insights.
Enterprise Features: Add team collaboration features, audit logging, advanced access controls, and custom deployment options for sensitive environments.
Built With
- bolt
- netlify
- nextjs
- python
- supabase

Log in or sign up for Devpost to join the conversation.