-
-

Digital Era in ur hands
-
Let the flow speak
-

Future Hands
-
Tech for future


Inspiration
Modern digital systems still depend heavily on keyboards, touchscreens, and manual navigation, which can be slow and inaccessible for many users. We wanted to rethink how humans interact with technology by creating a system that understands natural inputs like voice, gestures, and sign language. This idea led to OmniAccess[UNISON] a multimodal AI agent designed to make digital interaction more intuitive, accessible, and intelligent.
What it does
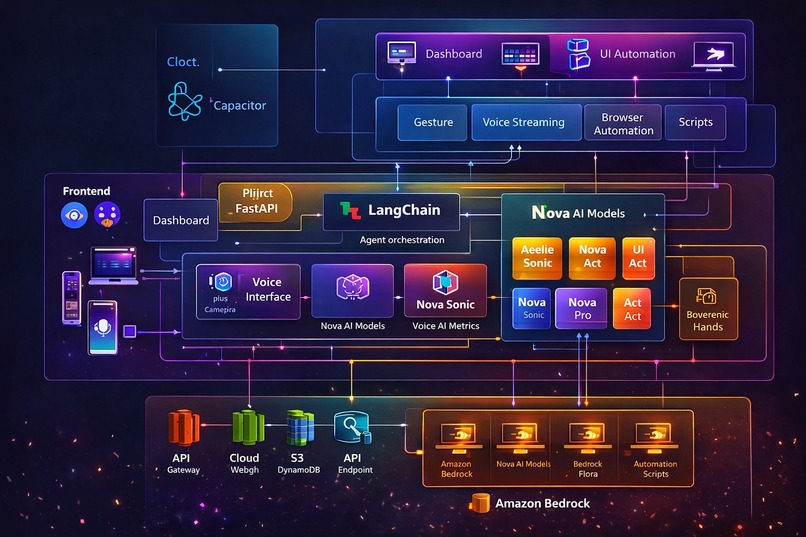
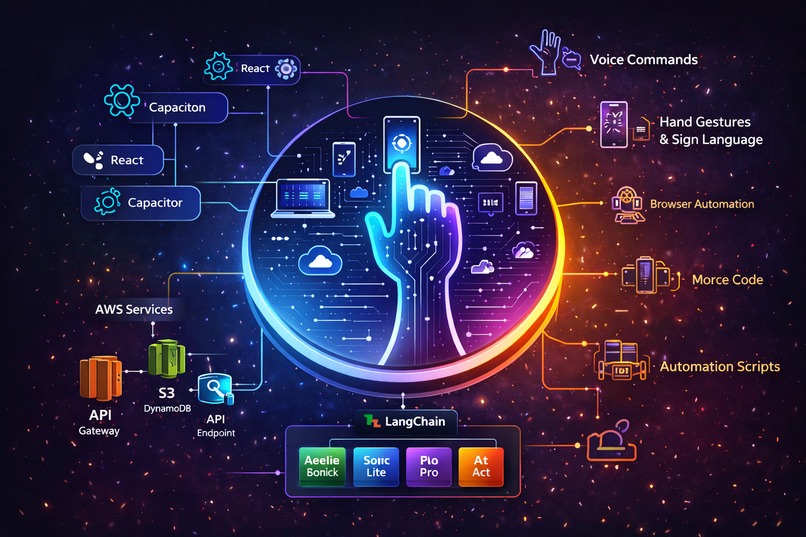
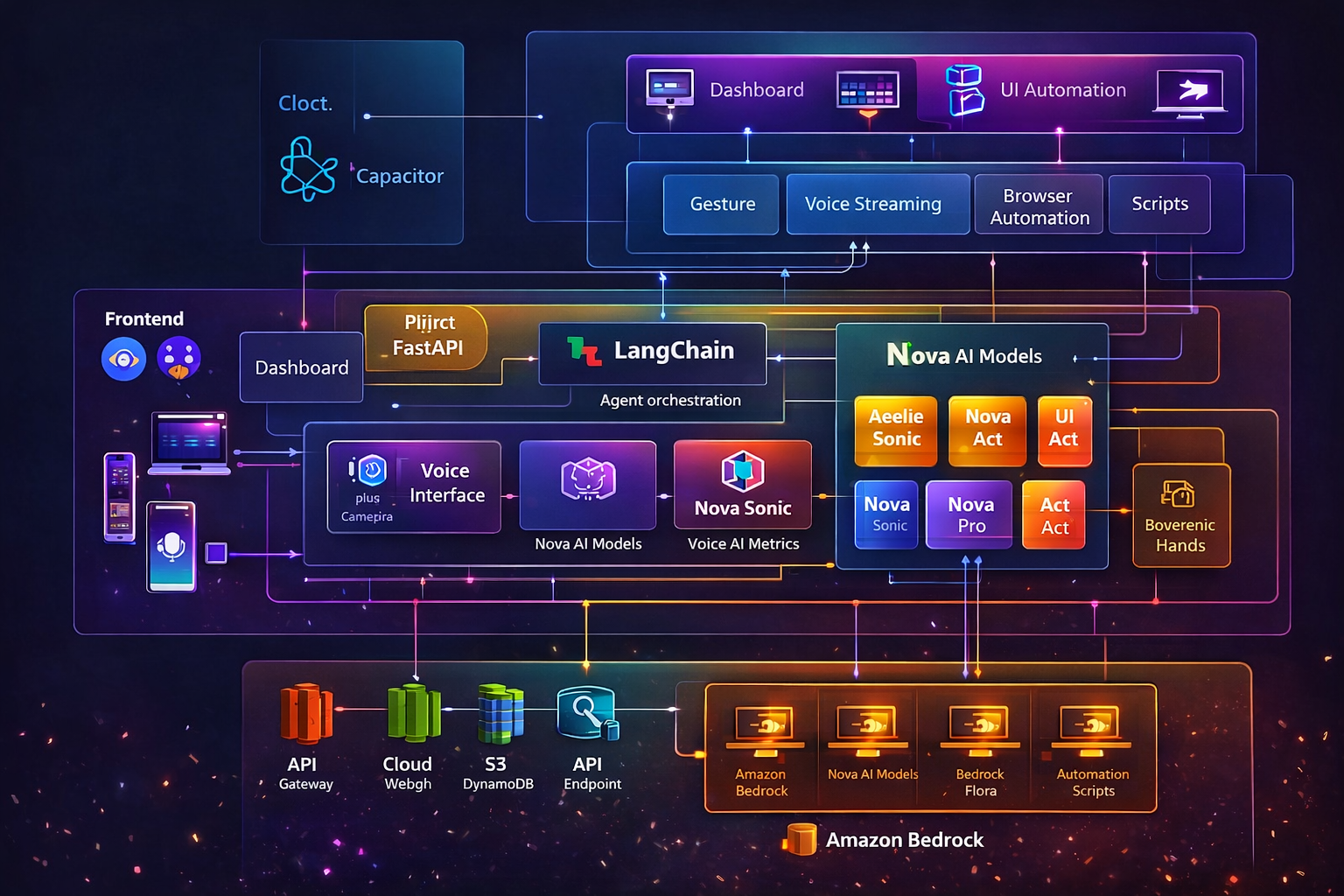
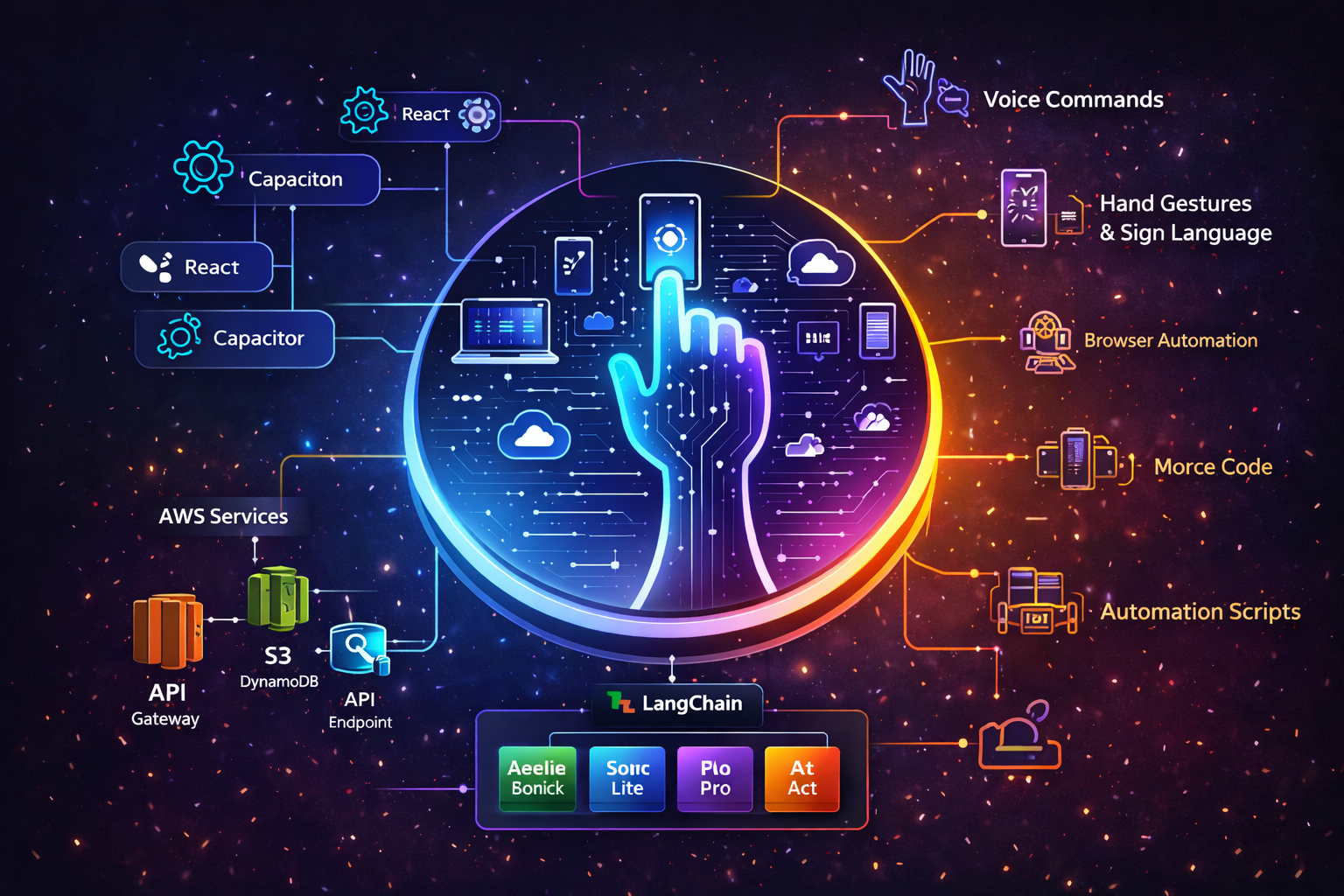
Unison is a Multimodal AI UI Navigator that allows users to control applications, websites, and devices using voice commands, hand gestures, sign language, or Morse code. Powered by Amazon Nova models, the system interprets user intent and automatically executes actions such as opening apps, browsing websites, taking screenshots, sending messages, or transferring tasks between devices. The goal is to create a universal AI interface that simplifies how people interact with technology.
How we built it
The system combines AI, computer vision, and cloud services into a unified architecture. The frontend was built using React and Vite, with Capacitor enabling cross-platform support. The backend uses FastAPI to manage APIs, agent orchestration, and automation tasks. LangChain coordinates the AI agent with Amazon Nova models through Amazon Bedrock for reasoning, voice interaction, and autonomous UI automation. Gesture and sign recognition are implemented using MediaPipe Hands, while automation is handled through tools like Playwright, PyAutoGUI, and ADB.
Challenges we ran into
Building a real-time multimodal system required solving challenges such as accurate gesture detection, synchronizing multiple input methods, reducing AI response latency, and enabling seamless cross-device communication. We addressed these by optimizing the input pipeline, using heuristic fallbacks when AI services were unavailable, and designing a flexible agent architecture.
Accomplishments that we're proud of
We successfully created a working AI-powered multimodal interaction platform that integrates voice, gesture, and automation capabilities. The system demonstrates real-time gesture recognition, autonomous browser navigation, multi-device communication, and support for over 150 languages in voice commands.
What we learned
Through this project we gained experience in building multimodal AI systems, integrating Amazon Bedrock with LangChain, implementing real-time computer vision, and designing scalable APIs with FastAPI. We also learned how combining multiple input modalities can significantly improve accessibility and user experience.
What's next for Unison
In the future we are having vision to expand sign language support, work on access for offline apps,files with permission options, Morse code implementation for screen lock and app lock, Multimodal device connection which traverses various applications within various connected devices through a simple gesture,
Built With
- amazon-bedrock
- amazon-cloudwatch
- amazon-dynamodb
- amazon-nova
- amazon-nova-act
- amazon-nova-lite
- amazon-nova-pro
- amazon-nova-sonic
- amazon-web-services
- android-debug-bridge-(adb)
- aws-api-gateway
- capacitor
- css3
- fastapi
- html5
- java
- javascript
- langchain
- mediapipe-hands
- playwright
- pyautogui
- python
- react
- scikit-learn
- sqlite
- swift
- typescript
- vite
- web-speech-api
- websockets

Log in or sign up for Devpost to join the conversation.