-
-
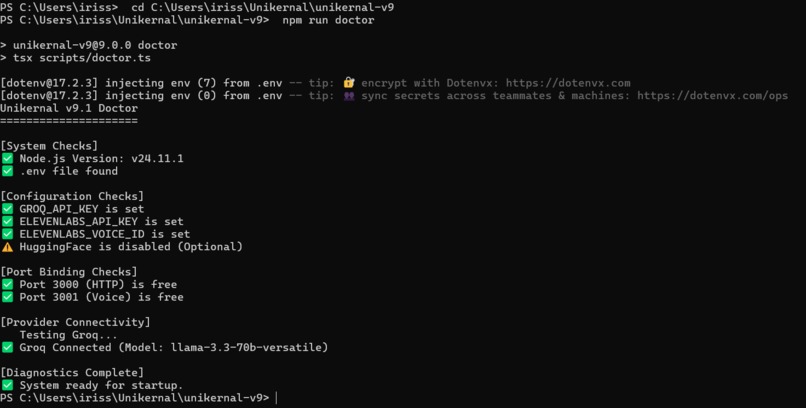
Start Doctor
-
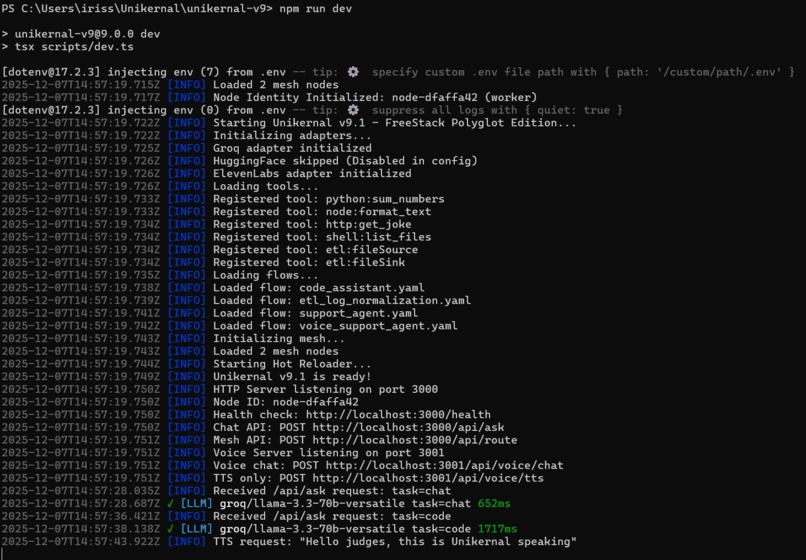
Start Kernel
-

Chat Demo
-

Code Agent Demo
-

TTS Demo



🧠 Unikernal v9.1 — FreeStack Polyglot AI Operating System 🌟 Inspiration
Modern AI projects waste enormous time wiring together LLMs, voice systems, Python tools, APIs, and infrastructure. Every hackathon, every startup, every team ends up rebuilding the same integrations over and over again.
I asked myself:
“Why doesn’t AI have an operating system?”
Not a model. Not a framework. A kernel — that makes Python, Node, LLMs, voice, APIs, and workflows all talk through a single universal layer.
This became the inspiration for Unikernal v9.1: A FreeStack AI OS that works entirely on free-tier providers (Groq, ElevenLabs, HuggingFace optional), so it is accessible, fast, and hackathon-friendly.
⚙️ What it does
Unikernal v9.1 is a universal interoperability engine that gives AI applications a single kernel for:
✔ Ultra-fast LLM generation (Groq) ✔ High-quality text-to-speech and speech-to-text (ElevenLabs) ✔ Code generation and specialized coding agents ✔ Polyglot tool execution (Python / Node.js / Shell) ✔ Workflow automation via YAML flows ✔ Distributed mesh networking ✔ Fault tolerance, retries, and a Dead Letter Queue ✔ Zero-trust security with scope-based access ✔ Hot-reloading tools and flows without restarting
In short:
Unikernal lets any language talk to any AI or tool, instantly, through one kernel.
Developers can build chatbots, voice assistants, IoT controllers, ETL pipelines, or multi-agent systems without rewriting integrations.
🛠️ How we built it
Unikernal v9.1 is built as a modular AI OS with several layers:
- Universal Messaging Layer (UDL/UDM)
UDL = Universal Data Language (call/event/stream messages)
UDM = Universal Data Model (tools, services, agents)
This standardizes how every tool and agent communicates.
- Routing Kernel
Central brain that routes all messages to:
Groq LLM Adapter
ElevenLabs TTS/STT Adapter
Python Tool Adapter
Node Tool Adapter
Shell Tool Adapter
HTTP Tool Adapter
It supports:
Idempotency
Retries with exponential backoff
Dead Letter Queue
Mesh forwarding over HTTP
- FreeStack AI Layer
Groq → primary LLM provider (70B/8B models, ultra-fast)
ElevenLabs → Voice generation (new free-tier models)
HuggingFace (optional) → backup LLM provider
Configured via:
config/llm.runtime.json .env
- Agent System
Support Agent
Code Agent
Voice Agent
Orchestrator Agent
Each built on YAML flows and tool definitions.
- Tooling Layer
Custom tools:
python:sum_numbers
node:format_text
http:get_joke
shell:list_files
ETL fileSource / fileSink tools
- Diagnostics Layer
A built-in Doctor:
npm run doctor
Checks:
Node version
Ports
.env validity
Provider connectivity
Config validity
- Runtime Layer
Hot Reloading (config/tools.yaml & flows)
Mesh nodes (config/mesh.nodes.yaml)
Structured logs
🧩 Challenges we ran into ❌ Model deprecations
Groq and ElevenLabs deprecated old free-tier models, requiring dynamic model routing and config overrides.
❌ HuggingFace API migration
Old inference API (api-inference.huggingface.co) was shut down → upgraded to router-based endpoints.
❌ Body parsing mismatch for TTS endpoint
Voice API needed multi-format parsers for text/plain, json, and form-data.
❌ Distributed mesh networking reliability
Solved using:
HTTP forwarding
Node registry
Heartbeats (future work)
DLQ for message failures
❌ Hot-reloading correctness
Updating flows/tools while running required careful cache invalidation.
🏆 Accomplishments we’re proud of ⭐ Built a complete AI Operating System from scratch ⭐ Achieved full polyglot execution (Python + Node + Shell + HTTP) ⭐ Integrated LLMs and TTS on fully free-tier APIs ⭐ Designed a universal data model (UDL/UDM) ⭐ Implemented fault tolerance, retries & DLQ ⭐ Built mesh networking between kernel nodes ⭐ Voice pipeline works end-to-end (JSON → MP3 output) ⭐ Created a dev experience with:
npm run dev
npm run doctor
npm run test:api
⭐ It runs locally, with no cloud cost
Perfect for hackathons.
📚 What we learned
How to build a kernel-style architecture for AI systems
How to design universal agent/tool interfaces
How to integrate multiple LLM providers gracefully
How to handle model deprecations dynamically
How to build robust voice pipelines with ElevenLabs
How to design ETL workflows using YAML
How to use observability patterns (structured logs, DLQ, retries)
How to design AI systems that run offline / on free-tier infrastructure
🚀 What’s next for Unikernal-v9 🔜 v9.2 — Vision Agent (image understanding on Groq) 🔜 v9.3 — Memory Engine (long-term project memory) 🔜 v9.4 — Real-time WebSocket Streaming 🔜 v10 — Portable Edge Edition for IoT devices 🔜 Unikernal Hub — tool marketplace (community plugins) 🔜 Android / iOS client SDK 🔜 Web dashboard UI (flows, logs, testing tools) 🔜 Multi-agent orchestrator with auto-tools
And ultimately:
Turn Unikernal into a universal AI OS used across industries and hackathons worldwide.
Built With
- ai
- custom
- dotenvx
- elevenlabs
- express.js
- groq
- huggingface
- node.js
- python
- typescript
- yaml


Log in or sign up for Devpost to join the conversation.