-
-
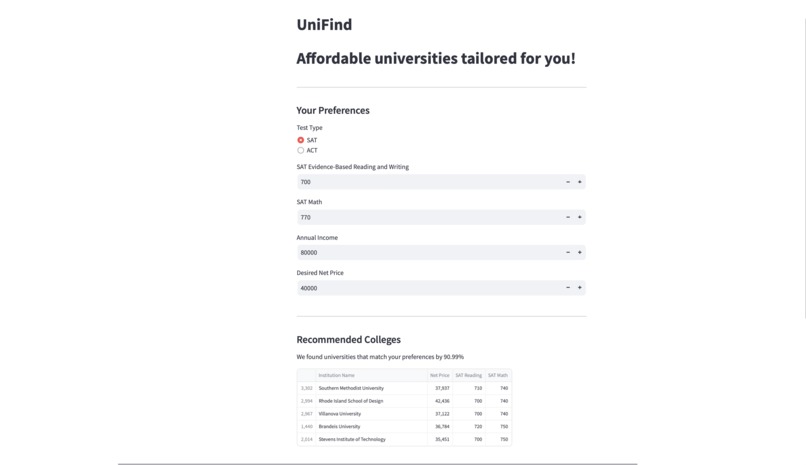
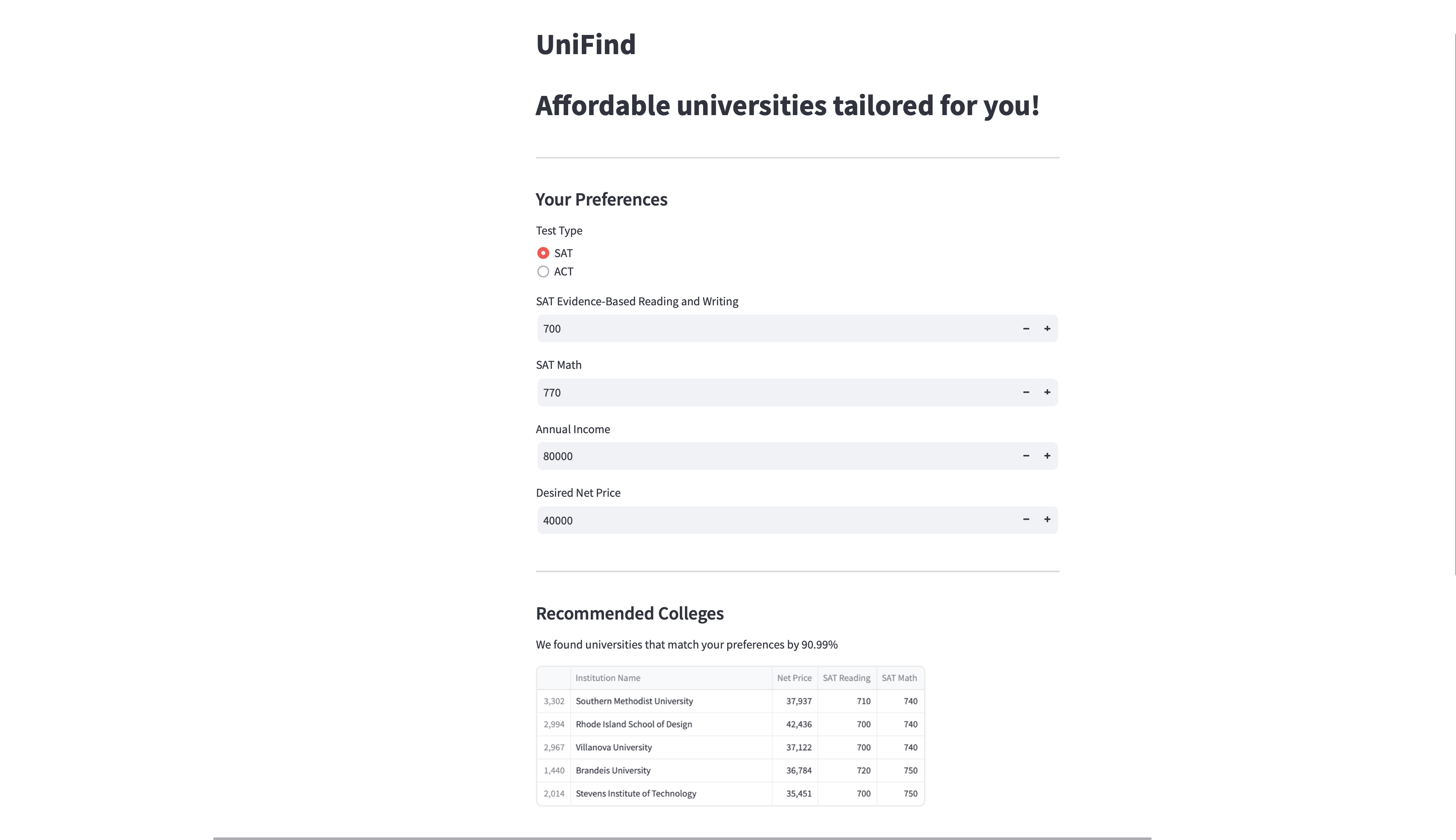
A simple to use, browser-based GUI
-
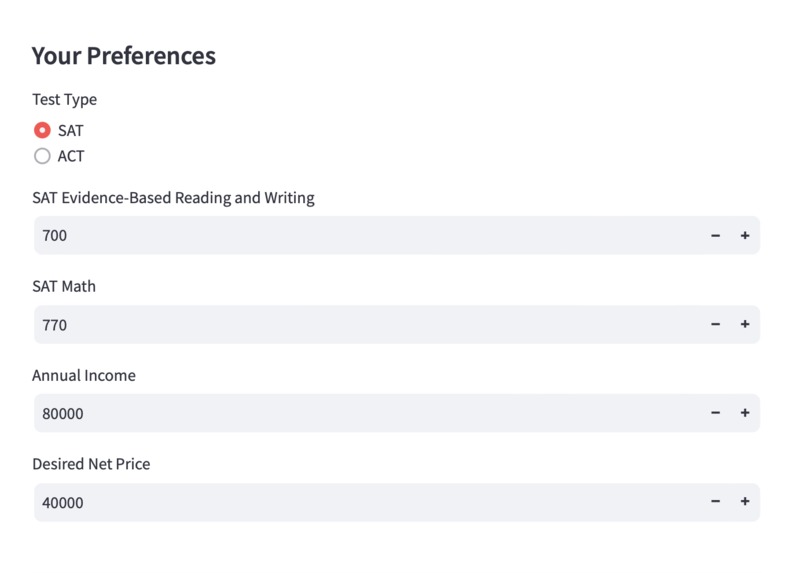
An interactive interface for taking in user inputs
-
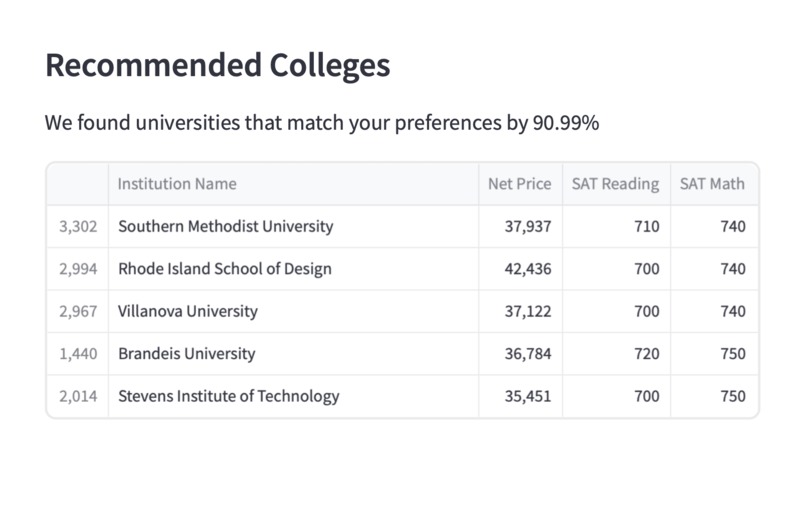
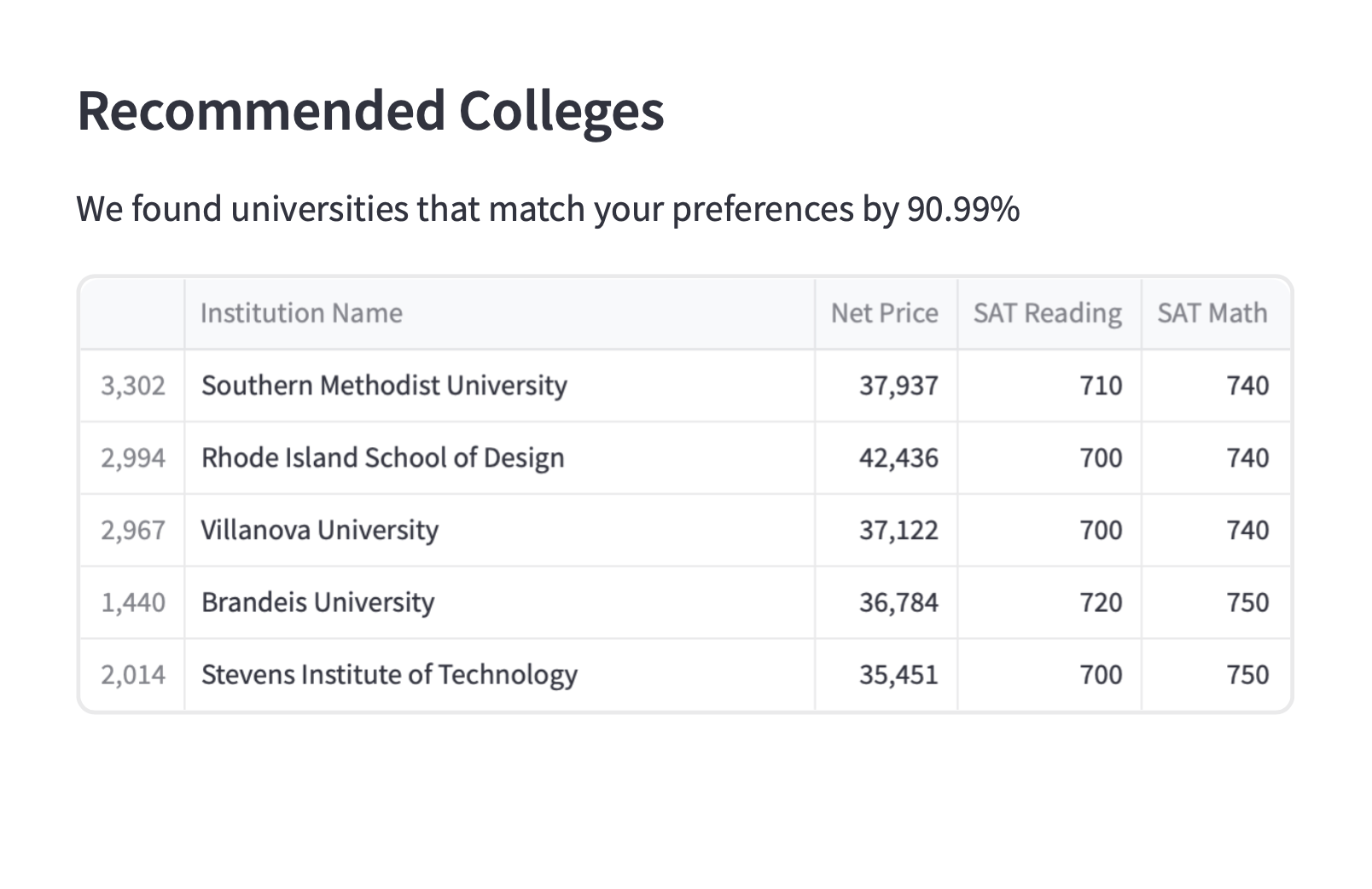
A specially curated list of universities that match your needs
Presentation: https://docs.google.com/presentation/d/1OMathHJOkVLbNz823BsYCN2oEQPvYCmmXkVdBDJc9zw/edit?usp=sharing
Inspiration
Getting into an affordable college that matches your financial needs is getting harder and harder. This creates stress among high-school students who have competitive standardised test scores, but struggling financially. We wanted to make a useful tool that recommends a list of colleges to help students find their fit.
What it does
UniFind takes in the student's standardised test scores, net income, and the amount they are able to pay for college. Using ML and data science techniques and a database of colleges, it gives the student a ranked list of colleges that fit their academic and financial needs. A perfect balance! Along with this, it also shows the similarity of the modelling. This helps keep the model transparent to needs of students. If the model is doing a good job, you should be sure about it!
How we built it
We use the K Nearest Neighbours model to train a students data on a list of over 6,000 universities in the US. The K-Nearest Neighbours model we used also determines the Euclidean distance between the user input data and the data in our colleges data frame. This distance is essentially the dissimilarity between the user data and the college data. For frontend, we use a Streamlit, which gives UniFind its user-friendly, interactive browser-based GUI.
Challenges we ran into
During the first few hours, we had many ideas, so we have to be highly selective about an idea that we could implement well in a short amount of time. Our team considered took too many factors at first, which restricted our ability to train data using the KNN model When trying to fit the model using the we factors we wanted to consider, we ran into difficulty with how KNN trains user's data on databases. We had to get rid of some factors such as gender and admit rate. Towards the end, we also faced challenges in calculating a similarity score for our model, so that users could be aware of the accuracy of the model.
Accomplishments that we're proud of
In general, we are proud that our model solves a real-world problem for financially challenged high-school students. Furthermore, it is amazing that UniFind is able to find an astoundingly good recommendations and a high similarity score, even though the model isn't too complex.
What we learned
Among learning about utilising the KNN model by fitting it with relevant factors and training it on a large database, we are inspired by the real-world applications for data science. A couple of our team members also learned how to use frontend with Python to make a user-friendly, browser-based application.
What's next for UniFind
Our team wants to work towards adding more functionality to UniFind. We can modify the KNN model's implementation to consider a user's preferred field of study, their gender, in-state residency or a universities admit rate.
Built With
- pandas
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.