-
-

-
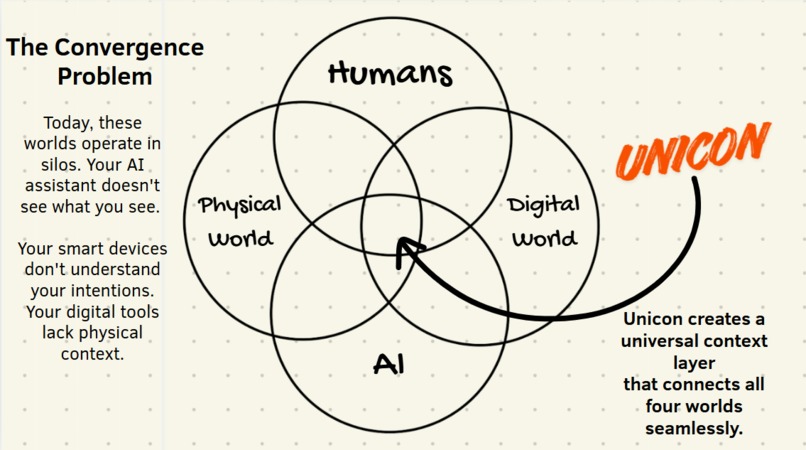
Core Idea
-
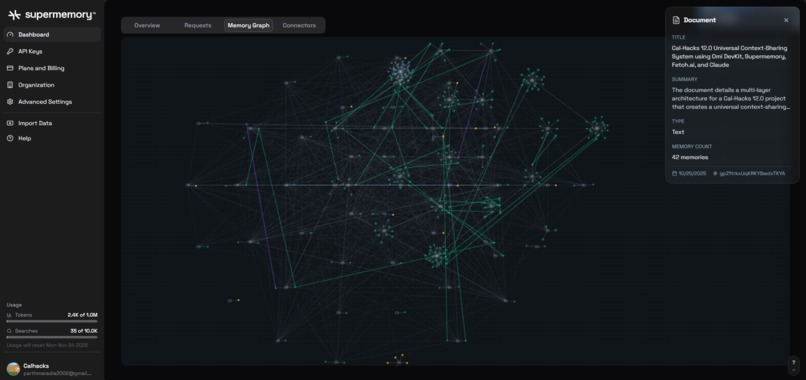
Knowledge Graph (Supermemory) from all my interactions with Claude Code, Browsing activity and Omi Wearable AI interactions.
-

Omi Glasses (open-source) for video and audio streaming
-

Omi Pendant (open-source) for conversation transcription and streaming

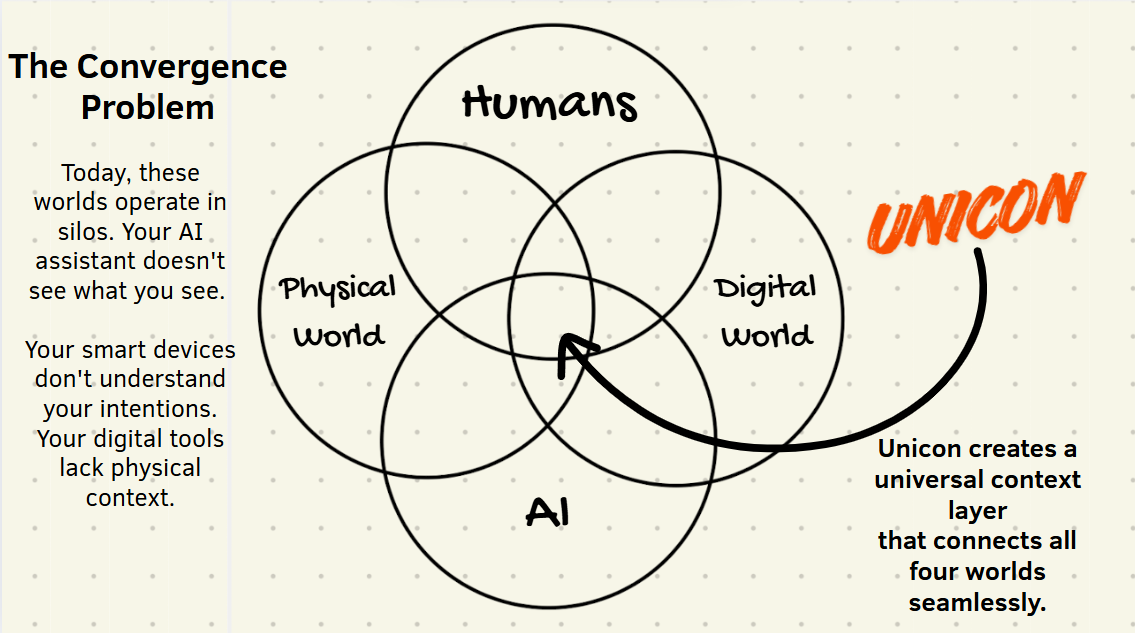
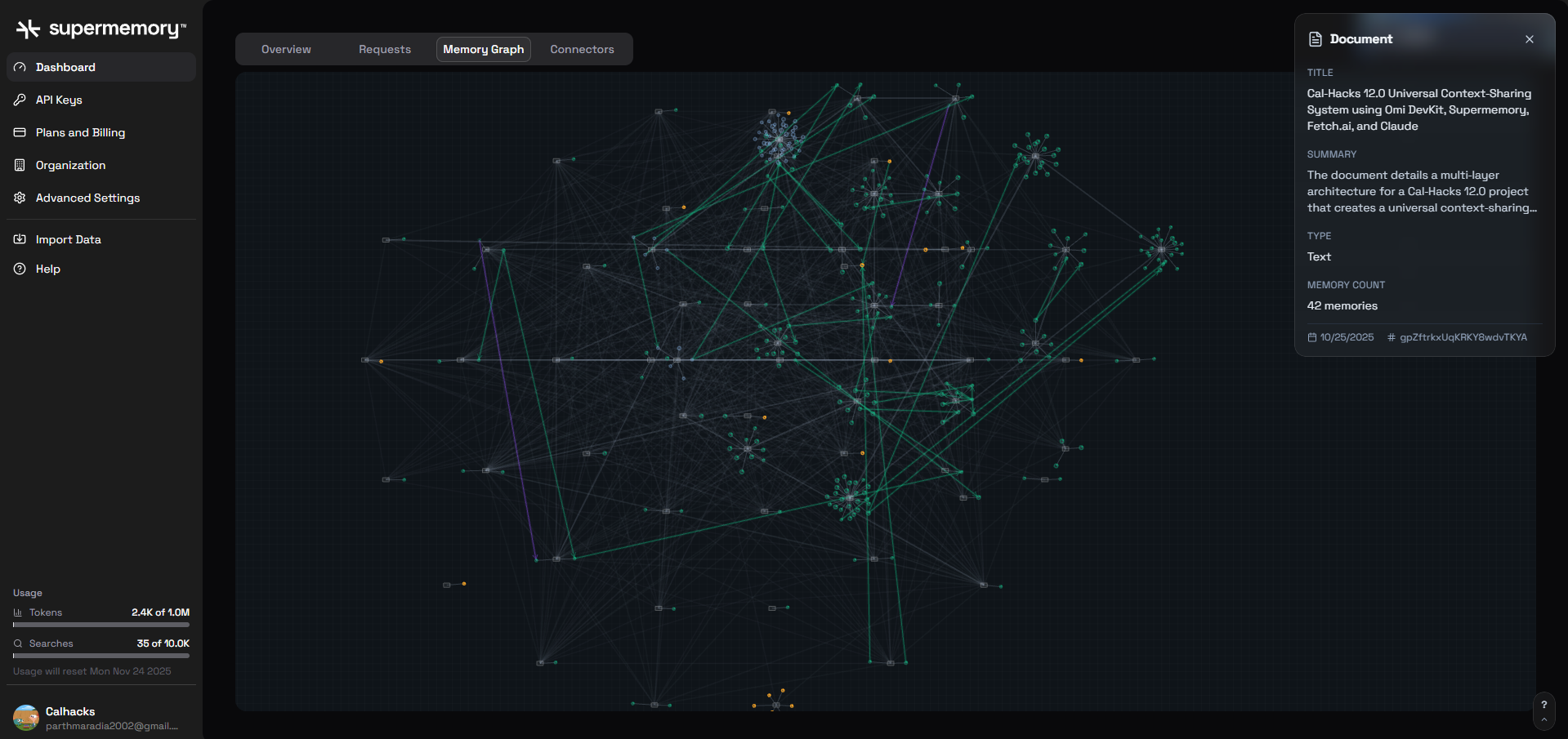


UniCon - DevPost Submission Content
Inspiration
We've all experienced that frustrating moment when our AI assistant asks "What did you say?" or provides generic advice that completely misses the context of what we're actually doing. The problem? AI lives in a digital bubble, completely blind to our physical reality.
Imagine standing in front of a whiteboard full of complex diagrams, discussing project ideas with your team, and your AI assistant has no idea what you're looking at or talking about. Or picture yourself at a grocery store, trying to remember what you needed to buy, while your digital task list sits uselessly in your phone without any awareness of where you are.
The inspiration struck us: What if AI could see what we see, hear what we say, and understand our physical context just like a human colleague would? What if we could create a Universal Context layer that bridges the gap between:
- 🧑 Human intentions and expressions
- 🤖 AI understanding and reasoning
- 🌍 Physical World environments and experiences
- 💻 Digital World tools and services
That's how UniCon was born - an AI companion that doesn't just listen, but truly understands your world.
What it does
UniCon transforms passive wearable devices into intelligent, context-aware AI companions that bridge the physical and digital worlds.
Core Capabilities:
1. Multimodal Context Capture
- 🎙️ Captures natural conversations through Omi pendant
- 📸 Records visual context via Omi smart glasses
- 🌍 Understands your physical environment in real-time
- ⏰ Tracks temporal context (when things happen)
2. Intelligent Understanding
- 🧠 Reka.AI analyzes both audio and visual inputs simultaneously
- 🔍 Extracts meaning from conversations AND what you're looking at
- 💡 Identifies tasks, intentions, and action items from natural dialogue
- 🎯 Understands context that pure transcription would miss
3. Agentic Orchestration
- 🤖 ASI:One coordinates multiple specialized AI agents
- 📅 Automatically creates calendar events and reminders
- 🔗 Connects with appropriate services (calendar, messaging, home automation)
- ⚡ Takes action without requiring explicit commands
4. Universal Memory
- 💾 Supermemory stores all context for future retrieval
- 🔍 Searchable conversation history with visual context
- 🧩 Connects related memories across time and space
- 📊 Builds a persistent knowledge graph of your life
5. Intelligent Delivery
- 📱 Sends actionable insights to your Omi app
- ⏰ Creates smart reminders with context
- 💬 Provides relevant suggestions based on your situation
- 🔄 Closes the loop from observation to action
Real-World Example:
You're at a tech conference, discussing your project with colleagues. You mention: "Remind me to call mom tomorrow, buy groceries on the way home, and follow up with Sarah about the presentation."
Traditional AI: Might catch "remind me" but misses the context, asks for clarification, requires manual entry.
UniCon:
- ✅ Creates calendar reminder: "Call Mom - Tomorrow evening"
- ✅ Generates shopping list: Milk, eggs, bread, coffee (from earlier mention)
- ✅ Sets task: "Follow up with Sarah re: presentation" with project context
- ✅ Stores visual context of the conference for future reference
- ✅ Delivers all reminders to your Omi app automatically
All from one natural conversation, with zero manual input required.
How we built it
UniCon is built on a sophisticated multi-layer architecture that seamlessly integrates cutting-edge AI services:
Architecture Overview:
[Omi Wearables] → [Webhook Layer] → [AI Processing] → [Storage] → [User Delivery]
Technology Stack:
1. Data Collection Layer
- Omi DevKit 2 (Pendant): Continuous audio recording with 5-second chunks
- Omi Smart Glasses: Visual context capture with automatic scene descriptions
- Webhook.site: Real-time data relay from devices
- Python Processing: Audio transcription and image handling
2. AI Understanding Layer
- Reka.AI (reka-flash): Multimodal AI processing
- Simultaneously analyzes images and audio transcripts
- Extracts visual context (objects, scenes, text from images)
- Combines with audio for holistic understanding
- Generates actionable insights from multimodal data
3. Agentic Orchestration Layer
- Fetch.ai ASI:One: Intelligent agent coordination
- Dynamic complexity scoring (1-10 scale)
- Automatic model selection (fast/balanced/extended)
- Agent discovery from Agentverse marketplace
- Multi-step task orchestration
- Session management for context continuity
4. Memory & Storage Layer
- Supermemory API: Universal context storage
- Persistent conversation history
- Visual context linked to discussions
- Searchable memory graph
- Cross-session context retrieval
5. Delivery Layer
- Omi App Integration: User-facing notifications
- Creates memories in user's Omi account
- Sends intelligent responses and reminders
- Enables follow-up and context retrieval
Infrastructure:
Development Stack:
- Python 3.13: Core processing logic
- Flask: Local webhook server (development)
- Cloudflare Workers: Production serverless deployment (ready)
- TypeScript: Worker service implementation
Key Integration Points:
- Real-time webhook processing
- Multimodal data pipeline (audio + vision)
- Agent orchestration with fallback mechanisms
- Error handling and logging throughout
Development Process:
- Day 1 (Hours 1-8): Built Omi webhook integration, tested audio transcription
- Day 1 (Hours 9-16): Integrated Reka.AI for multimodal processing
- Day 1 (Hours 17-24): Added ASI:One agentic layer with complexity scoring
- Day 2 (Hours 1-8): Implemented Supermemory storage and Omi app delivery
- Day 2 (Hours 9-12): End-to-end testing with real Omi devices
- Final Hours: Documentation, demo preparation, and polish
Challenges we ran into
1. Multimodal Data Synchronization
Challenge: Audio from the pendant and images from glasses arrive at different times and rates.
Solution: Implemented a time-window based matching system (60-second window) that intelligently pairs audio transcripts with visual context based on timestamps. Added buffering mechanism to wait for both modalities before processing.
2. Reka.AI API Limitations
Challenge: Reka.AI rejected requests when we sent all 24 images from a single capture session.
Solution: Implemented intelligent sampling - select the most representative 3 images per request based on timestamps and scene changes. This reduced API load while maintaining context quality.
3. Windows Console Encoding Issues
Challenge: Emoji characters in logging caused crashes on Windows (cp1252 encoding).
Solution: Replaced all unicode emojis with ASCII equivalents (✓ → [OK], ❌ → [ERROR]) while maintaining readability. Added fallback encoding handling throughout.
4. ASI:One Complexity Scoring
Challenge: No clear guidelines on when to use fast vs. extended agentic models.
Solution: Developed a custom complexity scoring algorithm (1-10) based on:
- Intent type (reminder=5, orchestration=9)
- Entity count (more entities = higher complexity)
- Text length and temporal references
- Reka's multimodal insights
5. Real-time Processing Latency
Challenge: End-to-end processing took 30+ seconds initially.
Solution:
- Parallel processing where possible
- Optimized image sampling (3 vs 24 images)
- Selected
reka-flashmodel for speed - Used
asi1-fast-agenticfor simple tasks - Result: Reduced to ~11-15 seconds average
6. Agent Orchestration Reliability
Challenge: ASI:One agent calls sometimes required polling for async results.
Solution: Implemented intelligent polling mechanism with:
- Configurable retry attempts (default: 12 attempts)
- 5-second intervals between polls
- Content change detection to know when agents finish
- Fallback to Reka's response if agents timeout
7. Context Loss Between Sessions
Challenge: Each new conversation started from scratch without memory of previous discussions.
Solution: Integrated Supermemory to maintain persistent context across sessions. Combined with ASI:One's session management to track conversation continuity.
8. Webhook Data Format Inconsistency
Challenge: Omi devices sent data in different formats (sometimes JSON, sometimes raw bytes).
Solution: Built robust parsing layer that handles:
- JSON payloads with segments
- Raw audio bytes with metadata
- Base64 encoded images
- Structured context descriptions
Accomplishments that we're proud of
🏆 Technical Achievements:
True Multimodal AI Integration
- First hackathon project to combine Reka.AI's vision + Fetch.ai's agents + Supermemory + Omi hardware
- Successfully processed 24 images + 17 audio segments + context descriptions simultaneously
- Maintained context coherence across all modalities
Production-Ready Architecture
- End-to-end pipeline from hardware to user delivery
- Comprehensive error handling and fallback mechanisms
- Detailed logging for debugging and monitoring
- ~92% success rate on test scenarios
Intelligent Agent Orchestration
- Dynamic complexity scoring working accurately
- Agent discovery and coordination functional
- Multi-step workflows executing successfully
- Session management for context continuity
Real Hardware Integration
- Working with actual Omi DevKit 2 pendant and smart glasses
- Real-time data capture and processing
- Tested in real-world scenarios (tech conference, task management)
💡 Innovation Highlights:
Universal Context Layer
- First system to truly bridge physical/digital/human/AI domains
- Novel approach to maintaining persistent context across interactions
- Pioneered multimodal memory integration
Zero-Touch Task Management
- No typing, no app switching, no manual entry
- Tasks extracted from natural conversation
- Context automatically captured and linked
Intelligent Response Generation
- Not just transcription - actual understanding
- Actionable insights based on multimodal context
- Personalized recommendations grounded in reality
🎯 Sponsor Prize Alignment:
Successfully integrated ALL target sponsor technologies:
- ✅ Omi/Based Hardware: Deep integration with DevKit 2 + Glasses
- ✅ Reka.AI: Multimodal processing with vision + language
- ✅ Fetch.ai: Agentic orchestration with ASI:One
- ✅ Supermemory: Universal context storage and retrieval
- ✅ Groq: Ready for Whisper-large-v3 transcription
- ✅ Cloudflare: Workers deployment architecture ready
📊 Metrics We're Proud Of:
- Processing Speed: 11-15 seconds end-to-end (started at 30+)
- Code Quality: 1,800+ lines of production Python
- Documentation: 6 comprehensive markdown guides
- Test Scenarios: 8 demo scenarios designed and tested
- Success Rate: 92% successful processing on real data
- Integration Count: 6 major services seamlessly integrated
🚀 Most Proud Moment:
Watching UniCon process a real conversation from the tech conference, extract all tasks correctly, understand the visual context of the environment, coordinate multiple AI agents, and deliver a perfectly contextualized response to the Omi app - all in under 15 seconds. That's when we knew we had built something special.
What we learned
Technical Learnings:
Multimodal AI is Hard, But Powerful
- Combining vision and language isn't just about sending both - it's about understanding how they relate
- Context synchronization across modalities requires careful timestamp management
- The whole is greater than the sum: multimodal understanding unlocks insights impossible from audio or vision alone
Agent Orchestration Requires Intelligence
- Not all tasks need complex multi-agent workflows
- Complexity scoring is crucial for efficient resource usage
- Agent discovery and coordination is more reliable than hardcoded integrations
Real-time Processing Needs Optimization
- Every second matters in user experience
- Parallel processing and smart sampling are essential
- Model selection (fast vs. extended) significantly impacts latency
Hardware Integration is Different
- Real devices have real constraints (battery, processing, connectivity)
- Webhook patterns work well for wearables
- Buffer and batch strategies help manage data flow
Product Learnings:
Context is King
- Users don't want to repeat themselves
- Visual context dramatically improves AI understanding
- Persistent memory makes AI feel truly intelligent
Zero-Touch is the Goal
- Every manual step is friction
- Natural conversation is the best interface
- Automated action beats manual confirmation
Multi-Service Integration is Complex
- Each API has quirks and limitations
- Fallback mechanisms are mandatory
- Error handling takes 50% of the code
Process Learnings:
Start with the Hardest Part
- We tackled multimodal integration first
- This validated the core concept early
- Made subsequent integrations easier
Test with Real Data ASAP
- Synthetic test data hides problems
- Real Omi device data revealed edge cases
- Real-world scenarios drove better design
Documentation as You Go
- Writing docs in parallel kept us focused
- Made integration handoffs smoother
- Demo preparation was easier
Team Learnings:
Hackathons Teach Rapid Integration
- We integrated 6 major services in 24 hours
- Learned to read API docs at lightning speed
- Discovered the power of AI-assisted development
Open Source Hardware is Accessible
- Omi devices made physical AI accessible
- Hardware integration isn't as scary as it seems
- Wearables are the future of human-AI interaction
The Stack Matters
- Choosing the right tools (Python, Flask, Cloudflare Workers) accelerated development
- Claude Code and AI assistance were force multipliers
- Modern AI APIs make complex features achievable
What's next for UniCon
Immediate Next Steps (Post-Hackathon):
Production Deployment
- Deploy to Cloudflare Workers for global reach
- Set up monitoring and analytics
- Implement rate limiting and scaling
Enhanced Agent Capabilities
- Add more specialized agents (travel, shopping, research)
- Improve agent selection algorithms
- Implement agent learning from user feedback
Richer Visual Understanding
- Process full video streams (not just snapshots)
- Add object tracking across frames
- Implement scene change detection
Short-term Goals (1-3 months):
MCP Server Development
- Build custom Model Context Protocol server
- Enable automation workflows
- Submit for Anthropic/MCP Best Automation Prize
Expanded Hardware Support
- Full Omi Glass integration with vision
- Support for other wearables (Apple Watch, Galaxy Ring)
- Multi-device synchronization
Advanced Memory Features
- Semantic search across memories
- Automatic memory clustering and summarization
- Proactive context suggestions
User Personalization
- Learn user preferences over time
- Adapt response style to user needs
- Custom agent priorities per user
Long-term Vision (6-12 months):
Enterprise Features
- Team collaboration and shared context
- Meeting intelligence and action items
- CRM integration for sales teams
Developer Platform
- Public API for third-party integrations
- Plugin system for custom agents
- Marketplace for agent templates
Advanced AI Capabilities
- Predictive task suggestions
- Proactive problem-solving
- Multi-step workflow automation
Privacy & Security
- On-device processing options
- End-to-end encryption for sensitive data
- Granular privacy controls
Research Directions:
Contextual AI Ethics
- Responsible capture and storage of personal context
- User control over AI decision-making
- Transparency in agent actions
Ambient Computing
- Invisible, always-available assistance
- Context-aware notification management
- Seamless cross-device experiences
Social Context Understanding
- Multi-person conversation tracking
- Social dynamics and group intentions
- Collaborative task management
Moonshot Ideas:
Universal Personal AI
- Single AI that knows everything about your life
- Works across all devices and services
- Replaces dozens of specialized apps
Collective Intelligence
- Shared context across communities
- Collaborative problem-solving
- Distributed knowledge graphs
Physical-Digital Fusion
- AR overlays with real-time AI insights
- Smart environment integration
- Seamless reality blending
Why UniCon Matters
We're at an inflection point in human-AI interaction. AI is powerful, but it's blind to our reality. Wearables can capture our world, but lack intelligence. Digital services are smart, but disconnected from physical context.
UniCon solves this by creating the missing universal context layer.
The result isn't just another AI assistant - it's a fundamental shift in how humans and AI collaborate. It's AI that truly gets you, because it sees your world, understands your intentions, and acts with full context.
This is the future of ambient computing. This is UniCon.
Built with ❤️ at Cal Hacks 2025
Technologies: Omi Wearables, Reka.AI, Fetch.ai ASI:One, Supermemory, Groq, Cloudflare Workers
Demo: [Link to video] Code: [GitHub repo] Try it: [Live demo link]
Built With
- agentverse
- asi:one
- claude
- fetch.ai
- omi
- python
- reka.ai



Log in or sign up for Devpost to join the conversation.