-
-
UniBio
What Inspired Us
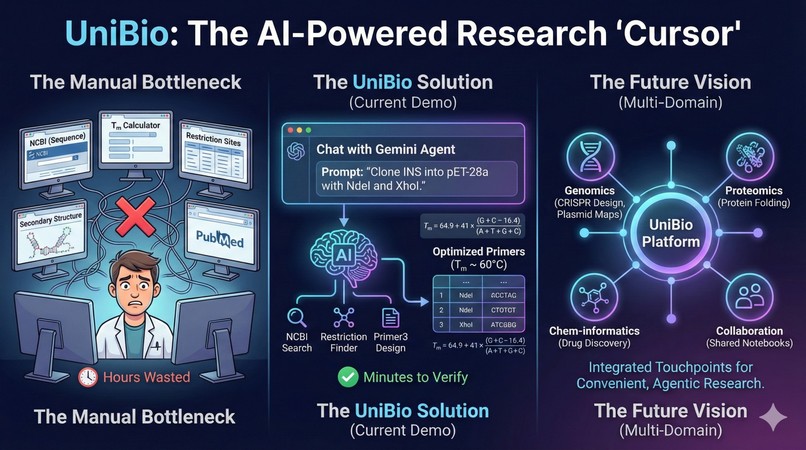
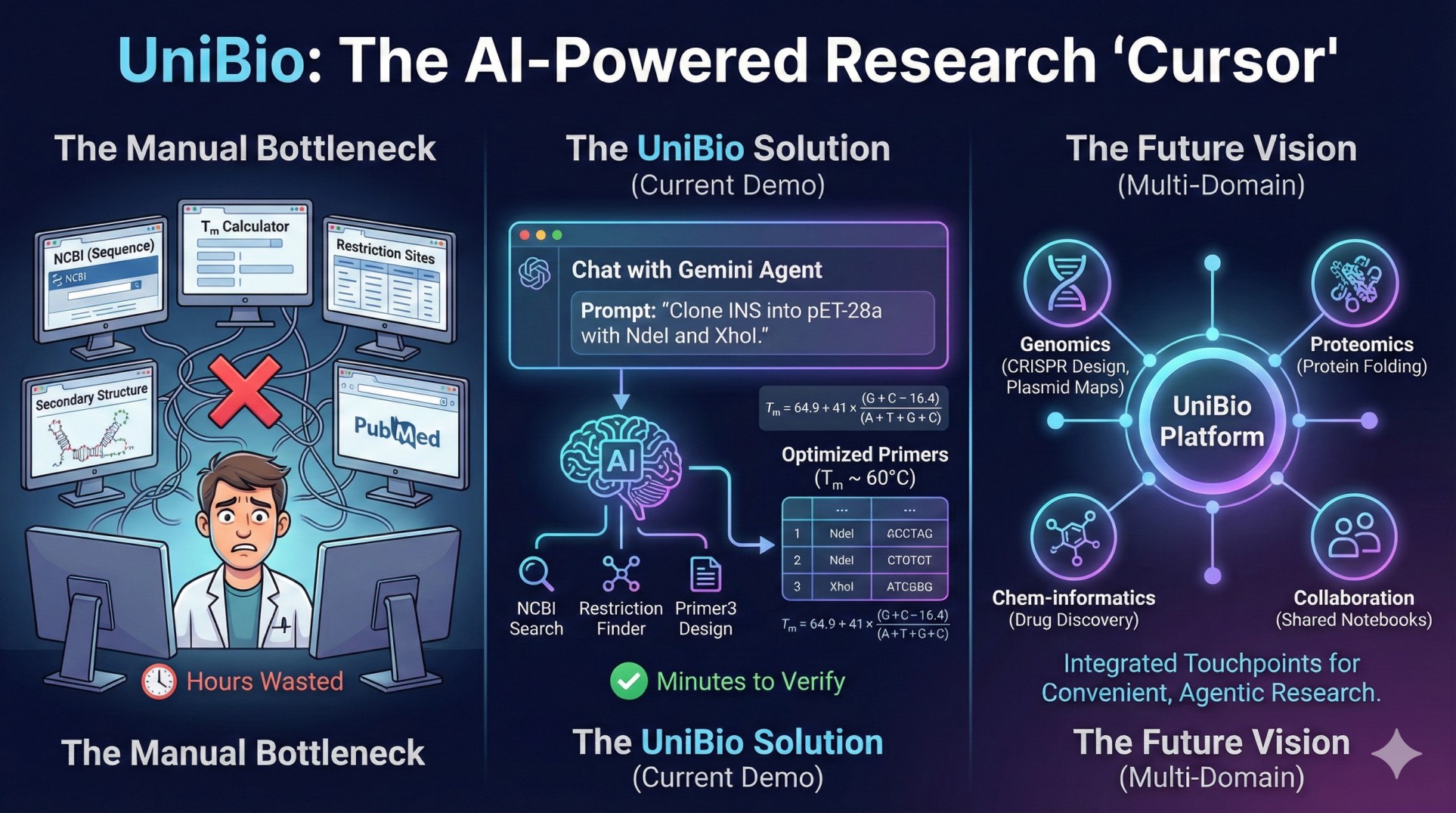
As biotech students, we happened to hit a massive bottleneck in research: the manual juggling of software. Performing a single experiment—like cloning a gene—required jumping between five or more websites (NCBI, melting temperature calculators, secondary structure predictors) just to get one result.
We were inspired to build a single workbench where these tasks live together. We wanted to create an environment where a researcher could simply state their intent—"Clone human insulin into pET-28a with NdeI and XhoI"—and have an AI agent orchestrate the workflow. Our goal was to move from manual orchestration to high-level verification, allowing scientists to focus on the biology, not the data plumbing.
How We Built It
We designed UniBio with a three-layer architecture to ensure that the AI is grounded in real biological data rather than just hallucinating sequences.
Frontend (React, Vite, TypeScript): A modern dashboard that provides both a manual UI for specific tools and an integrated AI chat panel for natural language commands.
Backend (FastAPI, Python): A robust server that handles biology logic using libraries like Biopython and Primer3. We used Pydantic for strict request/response validation.
AI Agent (Gemini API): We utilized Gemini's function-calling capabilities to create a "tool-using" agent. We provided the model with function declarations for every backend capability, such as search_ncbi_nucleotide and design_primers.
The Biology Layer
The platform performs real-world calculations for molecular biology. For example, when designing primers, the system must optimize for the melting temperature \(T_m\) and ensure the product size is appropriate for the experiment:
$$ T_m = 64.9 + 41 \times \frac{(G+C - 16.4)}{(A+T+G+C)} $$
By integrating Primer3, our agent can automate the design of primers that meet these specific kinetic constraints (e.g., \(T_m \approx 60\,\mathrm{°C}\)) while checking for restriction sites or Gibson assembly overlaps.
What We Learned
Agentic Workflows: We learned how to effectively expose bioinformatics functions as "tools" for an LLM. The most critical takeaway was that for an AI to be useful in science, it must be grounded in real-world APIs (NCBI, PubMed) rather than relying solely on its training data.
Full-Stack Integration: We gained experience connecting a React/TypeScript frontend to a FastAPI backend, ensuring that the manual UI and the AI assistant stayed perfectly in sync.
Cloning Semantics: We deepened our technical knowledge of Restriction Cloning vs. Gibson Assembly, learning how to translate these laboratory requirements into code-based constraints for the agent.
Challenges We Faced
Tool Ambiguity: Making tool names and parameter descriptions clear enough so the model reliably chose the right tool (e.g., distinguishing between a general literature search and a specific nucleotide search). We iterated on our Gemini function declarations to ensure high accuracy.
API rate limits: The free tier of the Google Gemini API limits requests to 15 RPM (requests per minute) for Flash models and 2 RPM for Pro models. Since each chat interaction can trigger multiple round-trips (user message → function call → result back to model → next function call → result → final answer), a single complex prompt like "fetch the INS gene, check restriction sites, and design primers" could consume 3–4 API calls in one conversation turn. Under heavy testing or demo conditions, we hit the rate ceiling quickly. We addressed this by defaulting to Gemini 2.5 Flash (higher free-tier limits), keeping the agent's max_iterations capped at 5 to prevent runaway tool-call loops, and advising users to obtain their own API key for higher quotas.
Syncing AI and UI: Every time we added a new feature, like Paper Search, we had to update four separate layers. This taught us the importance of maintaining a strict development checklist to ensure the platform's manual and automated capabilities remained identical.
Accomplishments that we're proud of
We are particularly proud of creating a grounded AI agent. Unlike general-purpose chatbots, UniBio's assistant actually "knows" how to use a wrench. Seeing the agent break down a complex request like "Clone INS into pET-28a" into distinct steps—fetching the sequence, checking for internal restriction sites, and designing primers—was a massive win for us.
What we learned
Agentic Workflows: We learned that the future of scientific software isn't just better UI, but agentic orchestration where the AI acts as a middleware between the scientist and the tools.
Cloning Semantics: We deepened our understanding of the technical requirements for Gibson Assembly vs. Restriction Cloning, specifically how to automate the design of homology overhangs.
Full-Stack Engineering: Building this project from the ground up gave us a much deeper appreciation for how the UI, API, and tool-execution layers must communicate to handle complex data like DNA sequences.
What's next for UniBio
The primer design workflow is just the beginning. Our goal is to transform UniBio from a specialized tool into a cross-disciplinary ecosystem that serves as the primary touchpoint for scientific research.
Multi-Domain Integration: We intend to integrate a variety of touchpoints from diverse scientific fields, unifying the unique workflows of each into our agentic environment.
End-to-End Convenience: We are building toward a future where any complex scientific process—from metabolic path analysis to protein folding simulations—is handled through a single, convenient interface.
Eliminating Manual Drudgery: Moving forward, we plan to integrate more examples of "manual-heavy" tasks into our platform, ensuring that researchers can spend less time on repetitive data entry and more time on high-level innovation.
Interactive Visualizations: Integrating tools like interactive plasmid maps and 3D protein structures directly into the agent's output for immediate verification.
Built With
- biopython
- fastapi
- google-gemini-api
- ncbi-entrez-api
- node.js
- primer3-py
- pubmed
- pydantic
- python
- react
- tailwind-css
- typescript
- vite




Log in or sign up for Devpost to join the conversation.