-
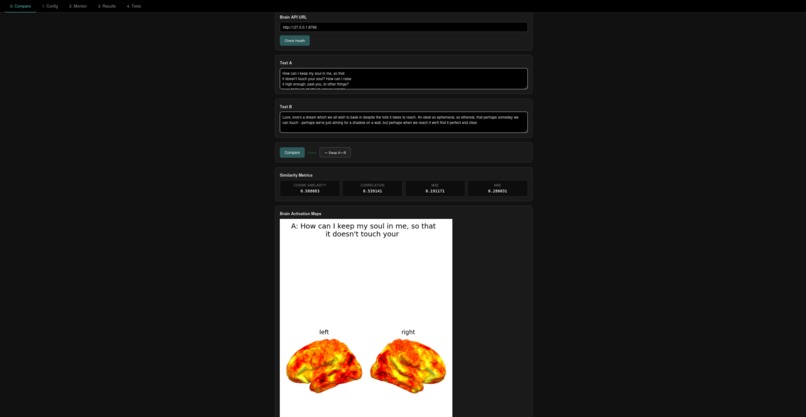
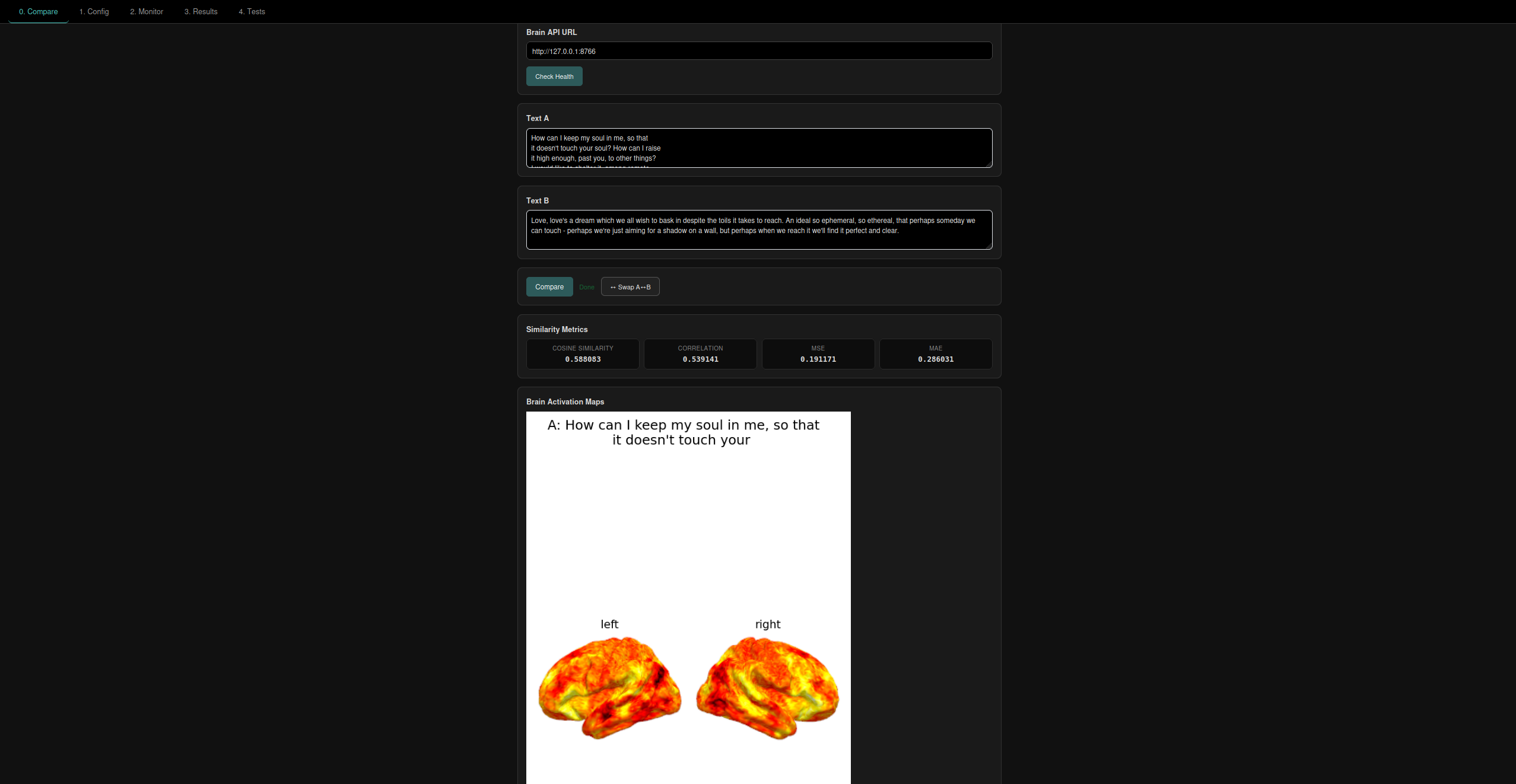
An example of comparing two poems found online about love.
-
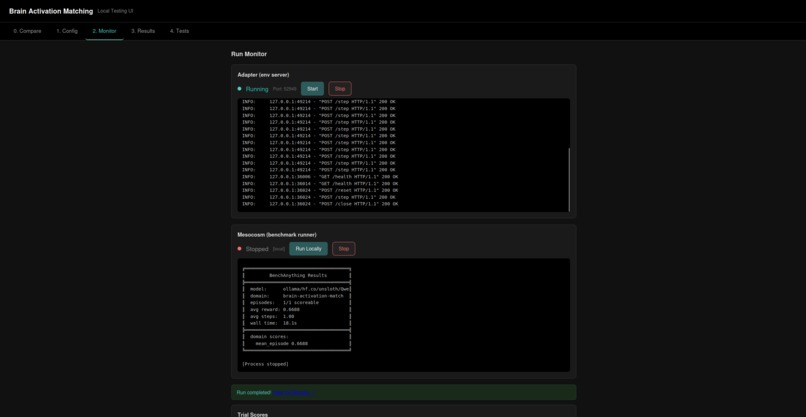
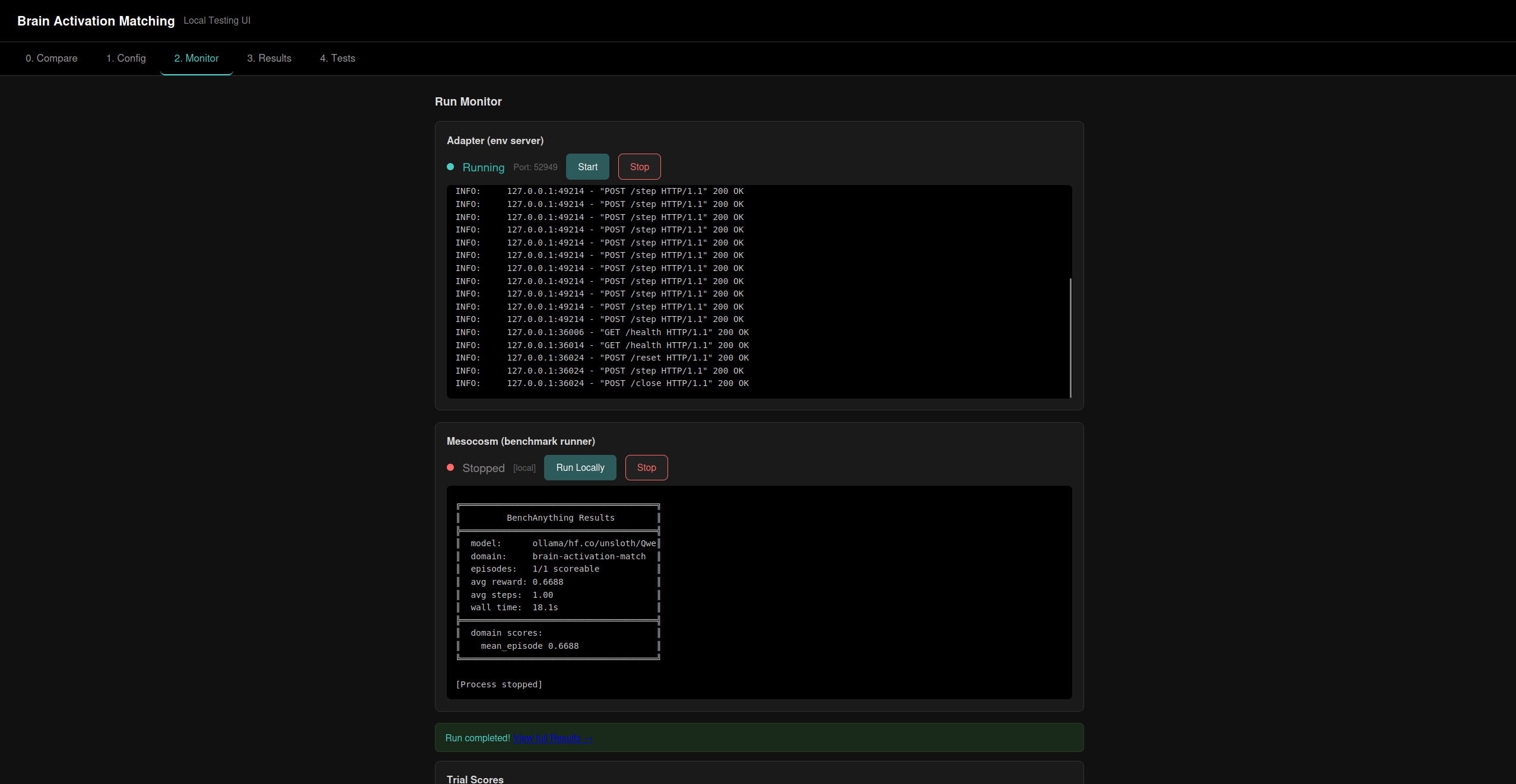
An example run of the benchmark, done locally with qwen.
Inspiration
We realized that one of the few things benchmarks today still lack is the human side of things - in particular, that of emotions. Current benchmarks test the intelligence and coordination of AI, and emotions are a relatively unexplored frontier mostly measured by human feedback. Until recently, emotions and brain responses to triggers have been unable to be measured without either asking for feedback or actual medical equipment.
Tribe v2 is a recently released model which predicts the brain based on video, audio, and text stimuli. Can you guess where we're going with this?
What it does
Our benchmark compares the writings of an AI and that of a poem or text, in context of a tribe v2 brain prediction. We ask the AI to write something that gets a similar reaction to that of the poem, and we compute the cosine similarity of the brain predictions to return a score. By doing so, our benchmark measures a facet of the emotional "intelligence" of the benched AI.
Challenges we ran into along the way
A whole lot, although two really stood out. Originally, we began with a benchmark for Chess - something we still have a fully functional demo for - which could easily have been a final project. However, due to the AI stepping limitations of Mesocosm (and oftentimes our own tools), the AI rarely came to a natural conclusion. It also only really made bad moves, no matter which AI we tried - although that's to be expected.
We then had some deeply confusing issues with tribev2 as a model. For one, models are hard to run! This is a benchmarking server, not a gpu-equipped one. Thus, we had to figure out how to run the model locally - necessitating a persistent web server. Secondly, tribev2 specifically uses a gated llama model, which requires registration - something which wasn't accepted in time for use for us. Thus, we had to figure out the size of the Llama model and the layers involved without access to the model itself, in the end landing on Microsoft's Phi-3-mini-4k-instruct.
In the end,
we succeeded in making a benchmark - despite the time crunch and complexities involved. We hope both this benchmark and the tool can be further used beyond just the scope of this project for training and tuning AI tools. In fact, this would arguable be a better tool for testing AI image and video generation due to the larger changes in the brain such media produces, and as Tribev2 is primarily trained on those forms rather then just text.
![[Insert name here]](https://lh3.googleusercontent.com/a-/AFdZucqyKamBl8DrtQmrh7KHZIS2cUgwXNV9nE8i_iYj7A=s96-c?height=180&width=180 "[Insert name here]")
Log in or sign up for Devpost to join the conversation.