-
-
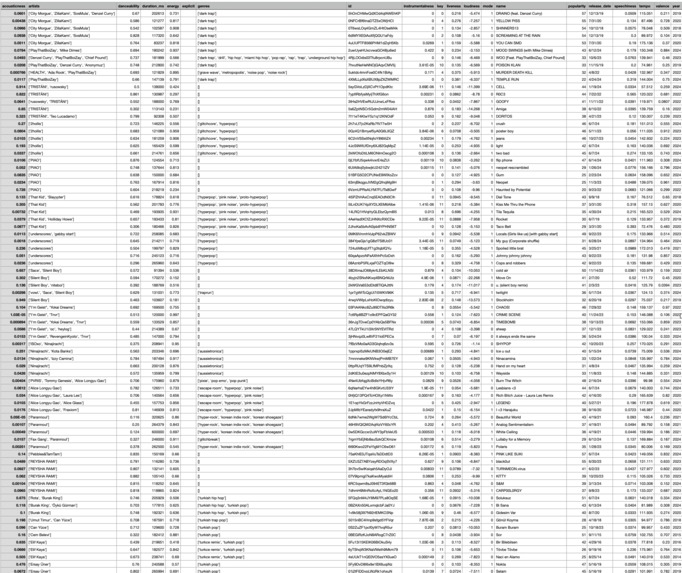
Screenshot of a part of the dataset
-

How we think the feature can be integrated into the actual TikTok app

Inspiration
Our project is inspired by our love for music and our passion for discovering underground artists. We recognize the immense potential of music that isn't mainstream and wanted to create a platform that could bring these hidden gems to the forefront. By recommending songs from lesser-known artists, we aim to boost their listeners and help them gain the recognition they deserve.
Frontend
The primary goal of the frontend was to show how the feature can be integrated within the actual TikTok app. The frontend for our Underground Artist Recommendation System was built using Flutter, chosen for its versatility in creating robust applications. Throughout the project, we gained valuable insights and skills, such as:
- Creating Highlighted Containers: We learned to design visually appealing containers to enhance the user interface.
- Implementing a Scrolling View with Videos: We mastered the technique of integrating a smooth scrolling view that includes video content.
- Displaying Text on Specific Screens: By creating a state and checking the current page, we successfully displayed text on designated screens during scrolling.
One significant challenge we faced was implementing the text display feature on only the third screen. Initially, we struggled to conceptualize the solution. However, after brainstorming and conducting research, we devised a method to create a stateful screen that tracks the user's current page. This breakthrough allowed us to overcome the obstacle and implement the desired functionality
Data Collection
The dataset was built using a combination of web crawling and web scraping. Initially, the web scraper built a repository of artist links from a large list of diverse Spotify playlist. This was achieved using the Selenium library in python. Then, these artists were used as a base for the web crawler. The web crawler was built using the Beautiful Soup library as it allows faster connections to be made as compared to Selenium. Starting from the base artists list, the web crawler collected more links from each artist’s Spotify page found in the “Related Artists” section. The web crawler collected around 600,000 Spotify artist links. Another program visited all these links and verified whether these artists fit our criteria for our “Underground” artist ( 100,000 - 1,000,000 monthly listeners). If these artists fit the criteria, the web scraper collected the song ids of the top 5 songs on the artists page. After filtering and collecting songs, we had a dataset of around 200,000 songs. Using the song id database, the program accessed the Spotify API and extracted the features of the song such as danceability, energy, key, loudness, mode, speechiness, acousticness, instrumentalness, liveness, valence, tempo, and duration. I There were, however, a lot of challenges while building the dataset. The largest one was being constantly blocked by Spotify whether it was because there were too many connections made to their website or because we exceeded the Spotify API rate limit. To overcome this, we started using batch requests to the Spotify API even though it made processing the data slightly harder. We also ran instances of the filtering script on different computers and on cloud environments in order to prevent being flagged by the Spotify servers. It taught us a lot of things in the field of web scraping which can only be learnt by experiencing working with various websites. We also learnt a lot about the python libraries Selenium and Beautiful Soup and the strengths and weaknesses of each.
Data Processing and Building The Recommendation Engine
- Data Source: In addition to the dataset we built above, we also used a dataset of 170k Spotify songs from kaggle.
- Data Cleaning: The collected data was cleaned to remove any duplicates or irrelevant entries. This ensured that our dataset was accurate and reliable for building the recommendation engine.
- Feature Engineering: We performed feature engineering to normalize and scale the features. This step was crucial to ensure that all features contributed equally to the recommendation process. Similarity Calculation: We used cosine similarity to calculate the similarity between songs. Cosine similarity measures the cosine of the angle between two non-zero vectors, which, in this case, represent the features of different songs.
- Recommendation Algorithm: The recommendation algorithm works by selecting a set of seed songs (songs that the user has in their profile) and finding other songs in the dataset that are most similar to these seed songs based on the calculated cosine similarity. Using TF-IDF (Term Frequency - Inverse Document Frequency) we created a metric for relevance based on the genre of songs to see which genres carried more important in the profile of a user, then creating a similarity index between potential recommendations and the songs in the user’s profile. A feature set of 15000+ genres was engineered for this, enabling high quality results. By using a combination of cosine similarity and the popularity of the song, the engine sets an order of priority for the list of song recommendations. Challenges Faced
- Data Manipulation: One of the major challenges was manipulating the data to ensure it was in the right format for analysis. This involved extensive data cleaning, normalization, and feature scaling. Creating a dataset and a system where recommendations wouldn’t be limited to only a few artists or genres (i.e. linear recommendations) was challenging, but the challenge was overcome through out-of-the-box use of basic data science principles like data wrangling.
Throughout the development of this AI algorithm, we gained valuable insights into data science and machine learning, particularly in the context of music recommendation systems. We learned how to effectively manipulate and preprocess large datasets, implement similarity-based recommendation algorithms, and integrate user feedback to enhance personalization. Our Spotify Recommendation Engine project demonstrates the potential of using advanced data analysis and machine learning techniques to enhance the music discovery experience. By focusing on lesser-known artists, we aim to create a platform that not only benefits music lovers but also supports emerging artists in gaining the recognition they deserve.




Log in or sign up for Devpost to join the conversation.