-
sign in to your account
-
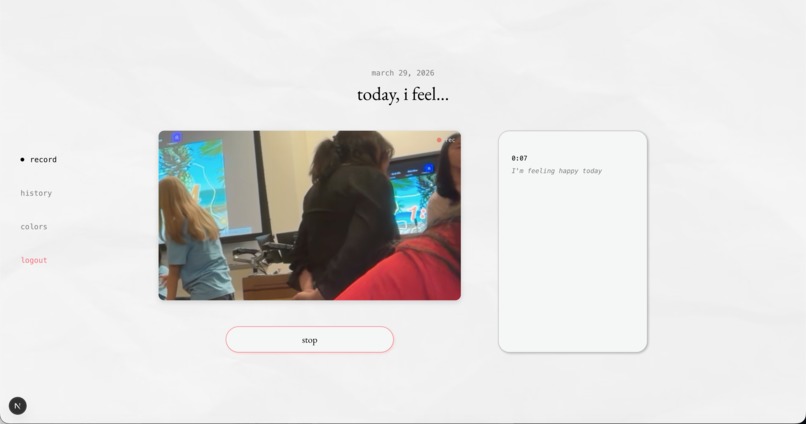
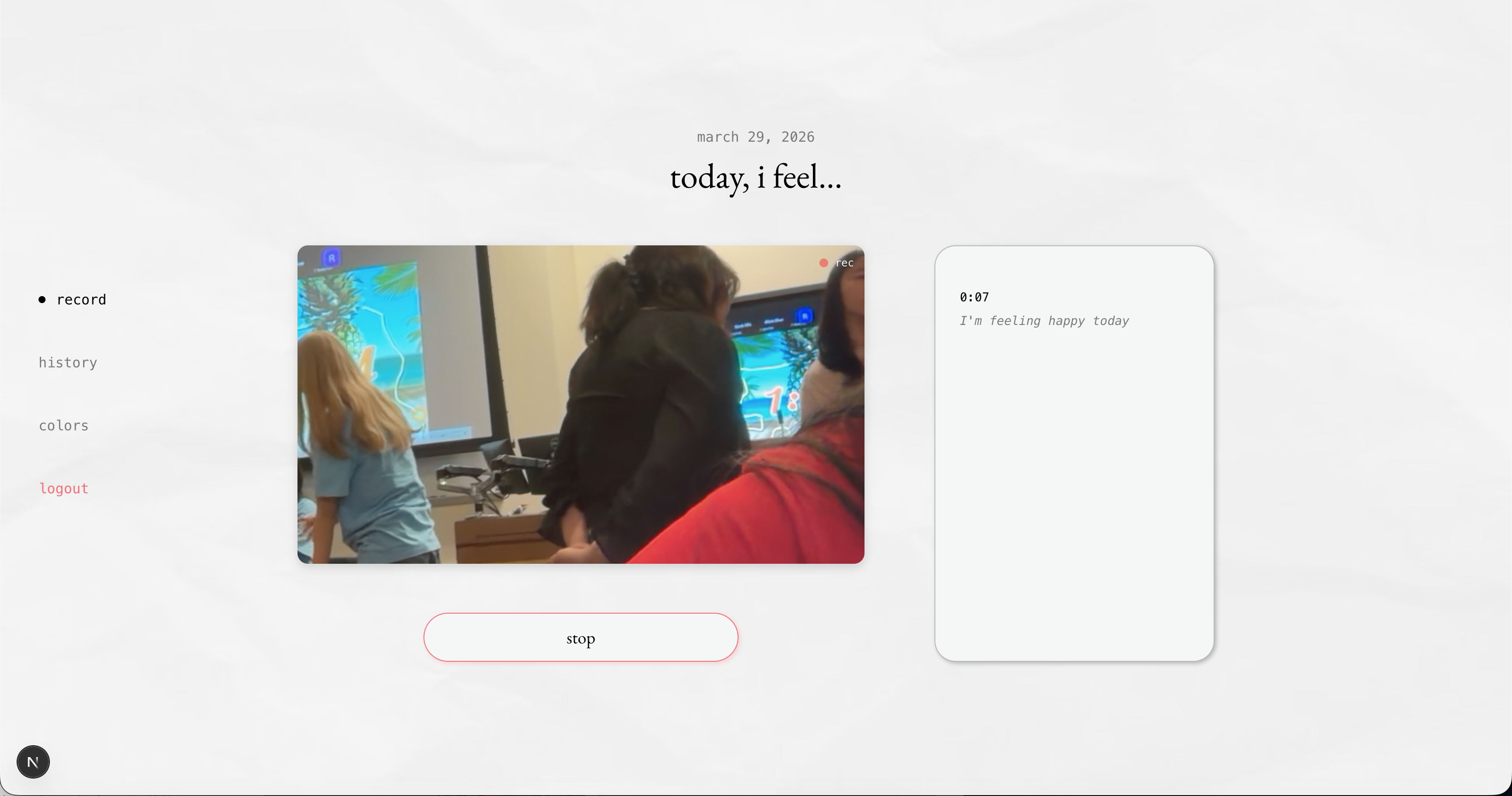
record your thoughts
-
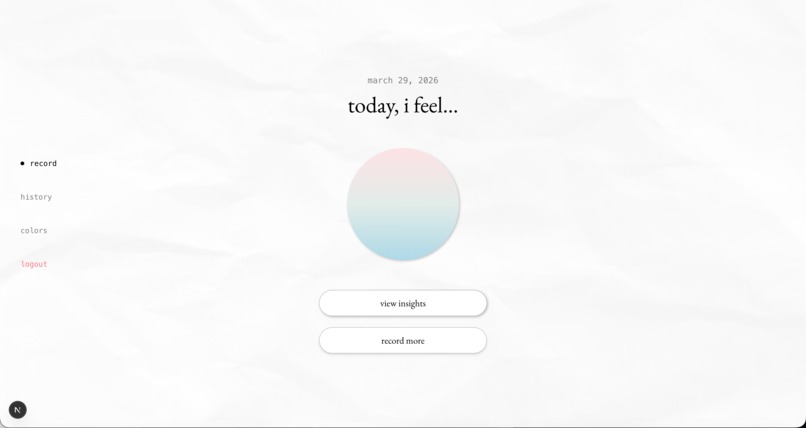
generates a color
-
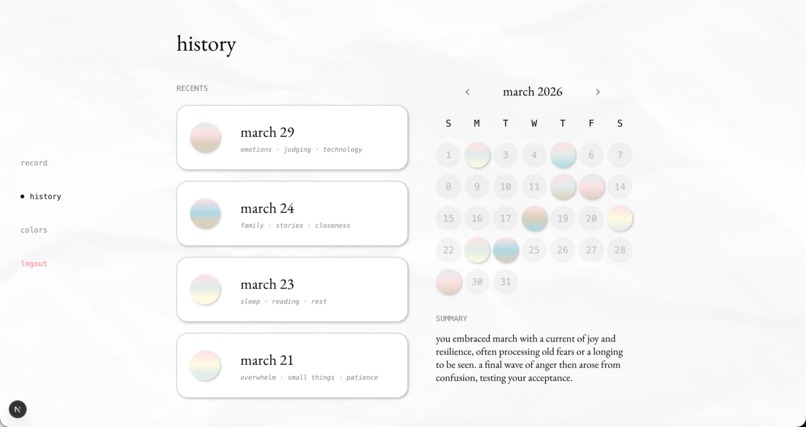
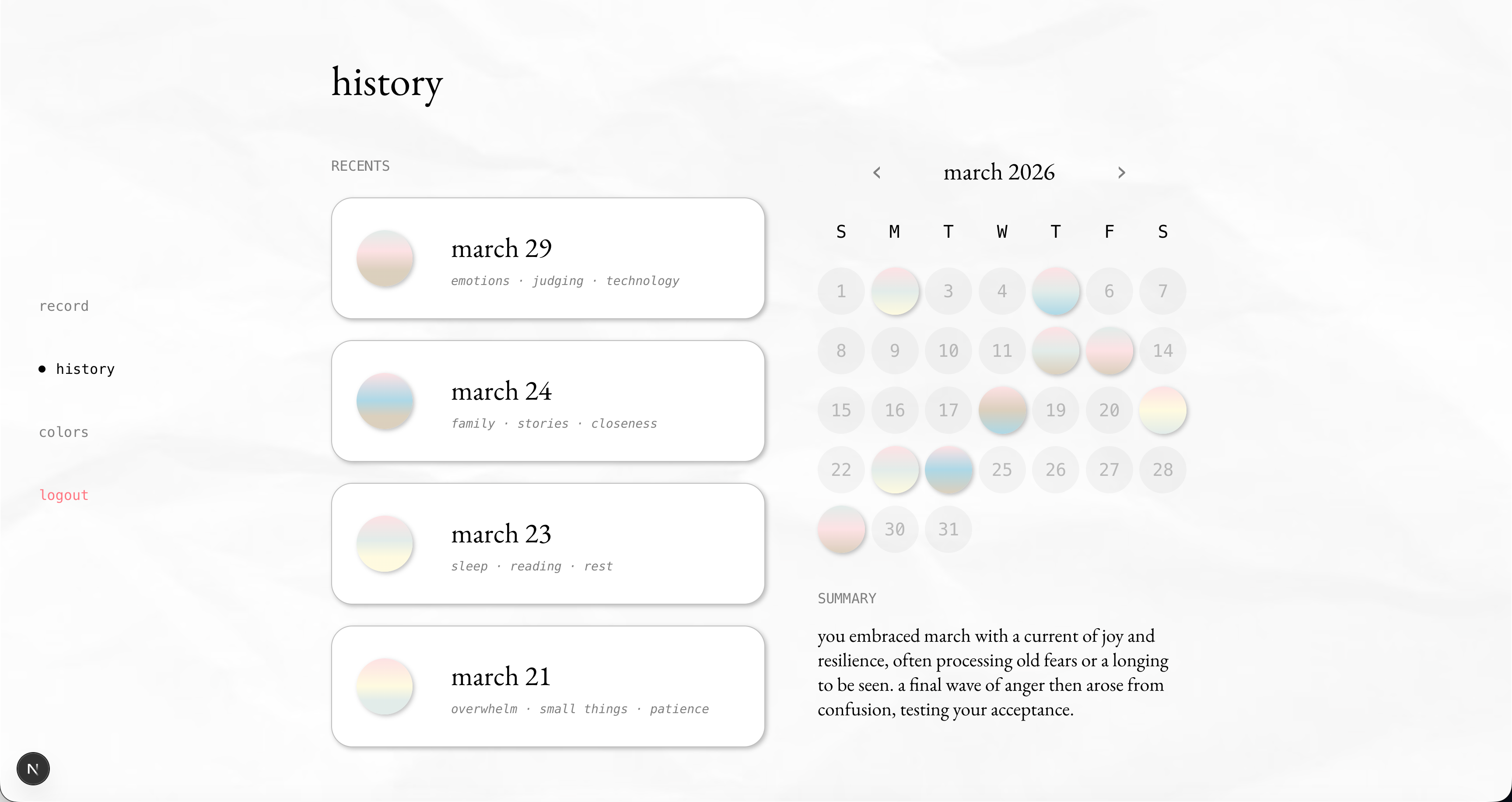
view your past entries + calendar
-
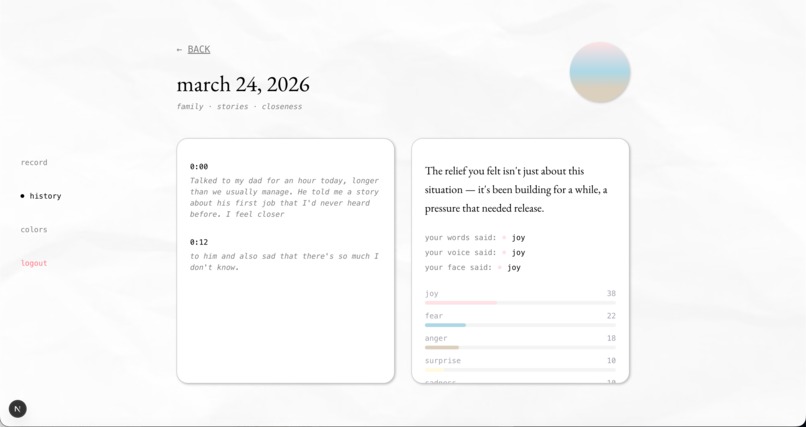
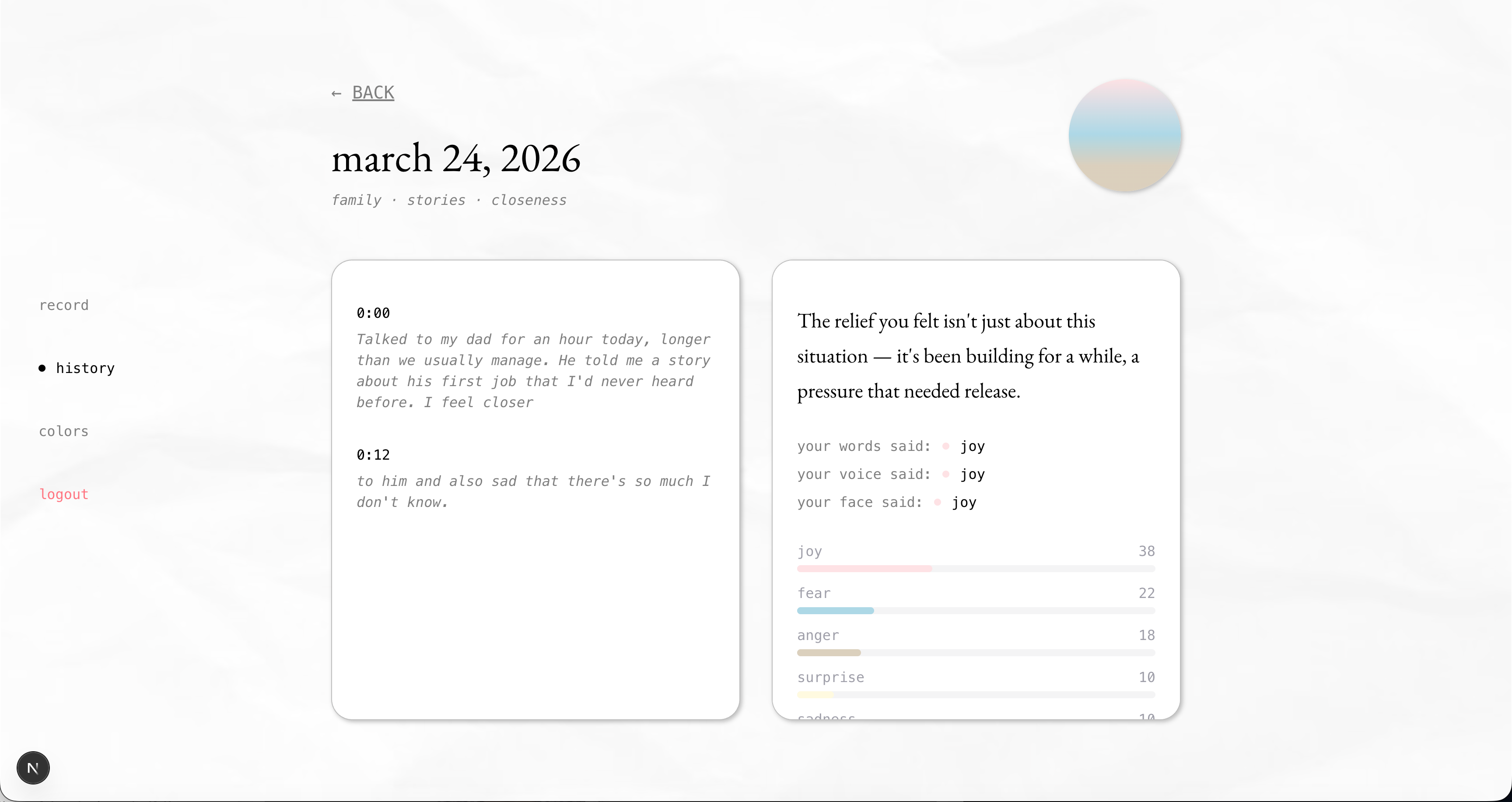
view entry transcription + insights
-
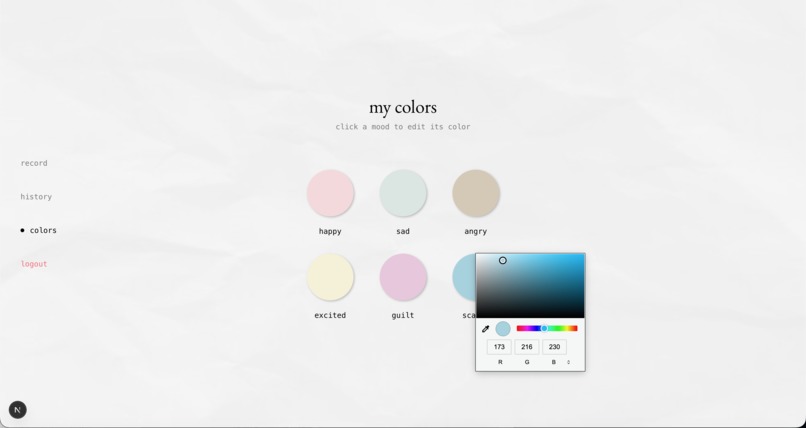
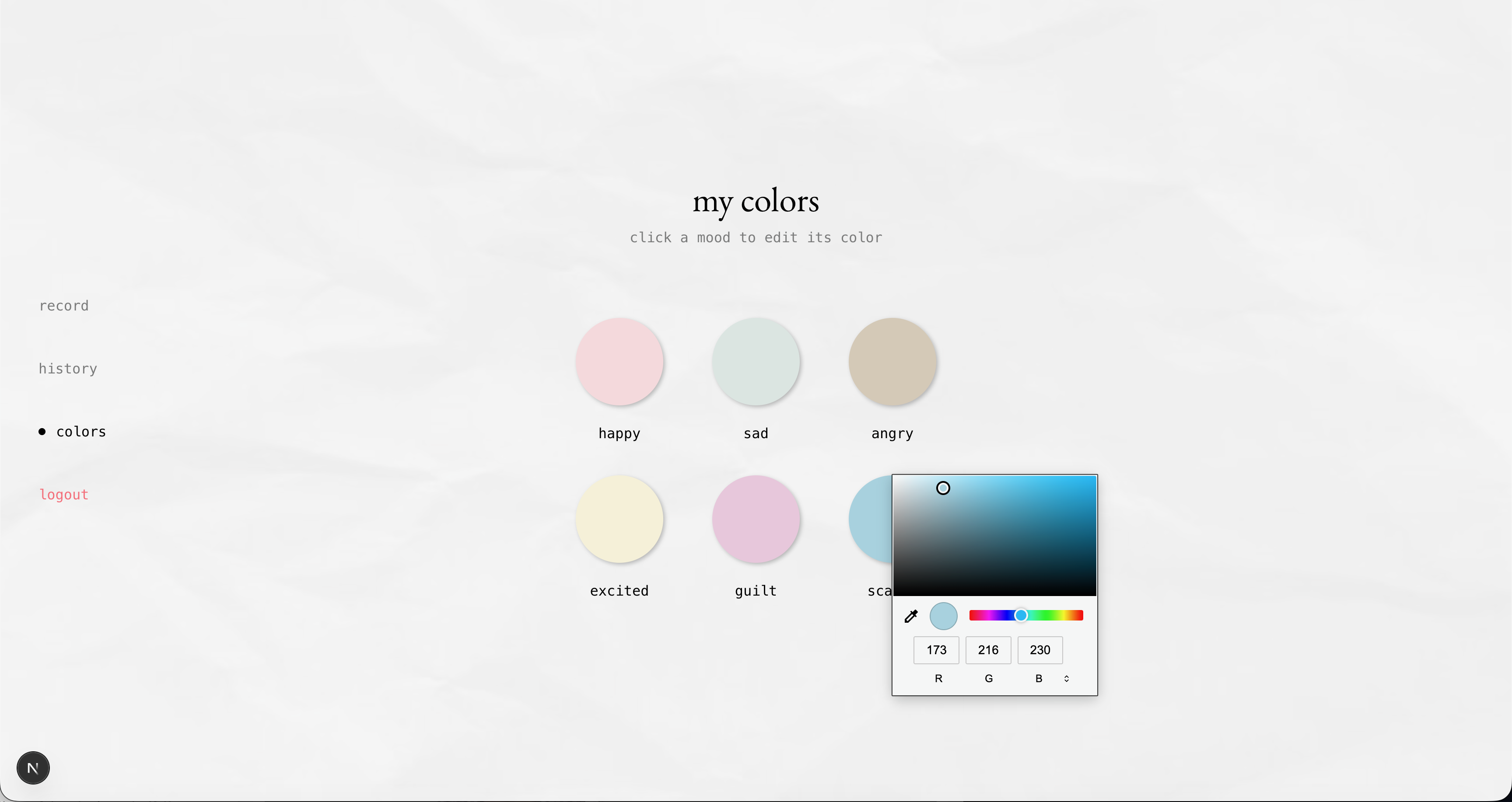
customize your colors
Inspiration
Undercurrent was inspired by a combination of a problem that we all felt. First, a desire to understand and express ourselves and our emotions, and second, a way to record those memories in an interface referenced by a visual display of our emotions. Among all of us, we realized that when we recall our life experiences, our emotions and what we felt in those moments is what sticks to us more vividly than the memories behind them. So that’s why undercurrent directly connects these two ways of recall together while creating a platform for users to be able to video journal in a way that allows them to understand more about themselves in the process. So overall, undercurrent was created by three problems. The need to understand. The need to vent. And the need to remember.
What it does
Undercurrent is an emotional mirror and archive for your life. You tap the record and speak freely—venting, processing, or just capturing a moment. While you talk, Undercurrent runs three signals in parallel:
Words — Gemini API analyzes your transcript for language-level emotion Voice & face — Hume AI reads your vocal tone, pacing, and facial micro-expressions simultaneously
These signals are fused into a single emotional breakdown across six core emotions: joy, anger, fear, sadness, disgust, and surprise. When the signals don’t fully align—when your words sound calm but your tone carries tension—Undercurrent surfaces a moment of insight: “Your words sound calm, but there may be some underlying tension in how you’re expressing it.” Gemini then generates a more specific interpretation grounded in what you said and how it was expressed. Each entry becomes a personalized color gradient, built from the user’s emotion palette and that session’s emotional breakdown. This gradient is saved as a swatch in a monthly calendar, gradually forming a visual record of the user’s emotional life—capturing how they felt in moments that might otherwise fade.
How we built it
Undercurrent is a Next.js 16 (App Router) web app that captures webcam + mic recordings and runs a parallel multi-signal AI pipeline to analyze emotion. After a user records, we immediately redirect them to /results and process four signals concurrently: Gemini 2.5 Flash parses the transcript for semantic emotion, Hume's Expression Measurement API analyzes both the audio prosody and a captured face frame, and ElevenLabs Scribe v2 handles transcription. The signals get fused with a weighted blend (Gemini 61%, Hume Voice 28%, Hume Face 11%) in fusion.ts into a single emotion profile. We used Clerk for auth, MongoDB Atlas + Mongoose for persistence, Vercel Blob for video storage, and a gradient system that maps emotions to custom colors.
Challenges we ran into
This was our first hackathon for all of our members, so much of the format was new to us. We had to navigate by getting advice from mentors and organizers about the typical procedures and the format of the pitch. On the technical side, this was our first time using a non-relational database and we learned how to use MongoDB. We learned how to sync Clerk and MongoDB via webhooks and had to go back and forth using tools to debug and understanding syntax and error messages, as well as learning how to populate databases through scripts. In addition, we also faced some challenges with familiarity with collaborating across Git and version control, including learning how to navigate merge conflicts and learning correct handling of branches during the hackathon.
Accomplishments that we're proud of
Getting the webcam recording and live speech-to-text captions working in tandem was one of our earliest wins, and it set the foundation for everything else. From there, successfully integrating three very different AI APIs (ElevenLabs, Gemini, and Hume) into a single coherent pipeline was the technical accomplishment we're most proud of. Each API speaks a different language, and making them play together cleanly was a non-trivial engineering challenge. On the design side, we're proud of the gradient visualization and calendar view. Translating an abstract emotion profile into something visually expressive was important to us, and we think it landed well. And honestly, the collaboration itself. The work split was even, the team communicated well under time pressure, and that showed in how much we were able to ship.
What's next for Undercurrent
- Richer emotional modeling: Expand beyond the six core emotions to capture more nuanced emotional states and improve the depth of interpretation
- Faster real-time feedback: Reduce latency across transcription and analysis pipelines to make insights feel more immediate and fluid

Log in or sign up for Devpost to join the conversation.